


While everyone is now repeating that 2025 is the “Year of the Agent”, OpenAI is heads down building towards it. In the first 2 months of the year they released Operator and Deep Research (arguably the most successful agent archetype so far), and today they are bringing a lot of those capabilities to the API:
A new open source Agents SDK with integrated Observability Tools
We cover all this and more in today’s lightning pod on YouTube!
More details here:
Responses API

In our Michelle Pokrass episode we talked about the Assistants API needing a redesign. Today OpenAI is launching the Responses API, “a more flexible foundation for developers building agentic applications”. It’s a superset of the chat completion API, and the suggested starting point for developers working with OpenAI models.
One of the big upgrades is the new set of built-in tools for the responses API: Web Search, Computer Use, and Files.
Web Search Tool
We previously had Exa AI on the podcast to talk about web search for AI. OpenAI is also now joining the race; the Web Search API is actually a new “model” that exposes two 4o fine-tunes: gpt-4o-search-preview and gpt-4o-mini-search-preview. These are the same models that power ChatGPT Search, and are priced at $30/1000 queries and $25/1000 queries respectively.
The killer feature is inline citations: you do not only get a link to a page, but also a deep link to exactly where your query was answered in the result page.

Computer Use Tool
The model that powers Operator, called Computer-Using-Agent (CUA), is also now available in the API. The computer-use-preview model is SOTA on most benchmarks, achieving 38.1% success on OSWorld for full computer use tasks, 58.1% on WebArena, and 87% on WebVoyager for web-based interactions.
As you will notice in the docs, `computer-use-preview` is both a model and a tool through which you can specify the environment.

Usage is priced at $3/1M input tokens and $12/1M output tokens, and it’s currently only available to users in tiers 3-5.
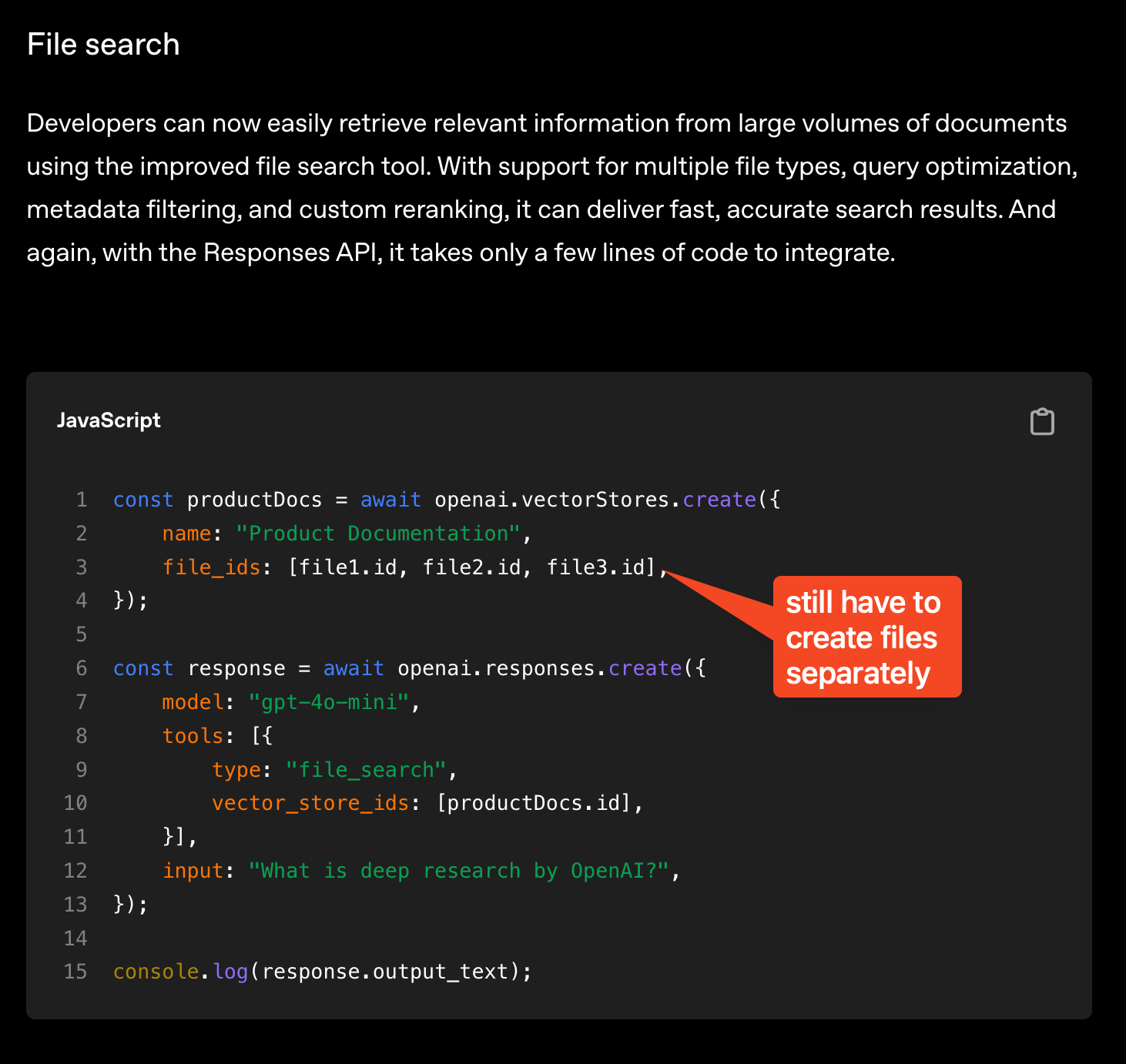
File Search Tool
File Search was also available in the Assistants API, and it’s now coming to Responses too. OpenAI is bringing search + RAG all under one umbrella, and we’ll definitely see more people trying to find new ways to build all-in-one apps on OpenAI.
Usage is priced at $2.50 per thousand queries and file storage at $0.10/GB/day, with the first GB free.
Agent SDK: Swarms++!
https://github.com/openai/openai-agents-python

To bring it all together, after the viral reception to Swarm, OpenAI is releasing an officially supported agents framework (which was previewed at our AI Engineer Summit) with 4 core pieces:
Agents: Easily configurable LLMs with clear instructions and built-in tools.
Handoffs: Intelligently transfer control between agents.
Guardrails: Configurable safety checks for input and output validation.
Tracing & Observability: Visualize agent execution traces to debug and optimize performance.
Multi-agent workflows are here to stay!

OpenAI is now explicitly designs for a set of common agentic patterns: Workflows, Handoffs, Agents-as-Tools, LLM-as-a-Judge, Parallelization, and Guardrails. OpenAI previewed this in part 2 of their talk at NYC:
Further coverage of the launch from Kevin Weil, WSJ, and OpenAIDevs, AMA here.
Show Notes
Timestamps
00:00 Intros
02:31 Responses API
08:34 Web Search API
17:14 Files Search API
18:46 Files API vs RAG
20:06 Computer Use / Operator API
22:30 Agents SDK
And of course you can catch up with the full livestream here:
Transcript
Alessio [00:00:03]: Hey, everyone. Welcome back to another Latent Space Lightning episode. This is Alessio, partner and CTO at Decibel, and I'm joined by Swyx, founder of Small AI.
swyx [00:00:11]: Hi, and today we have a super special episode because we're talking with our old friend Roman. Hi, welcome.
Romain [00:00:19]: Thank you. Thank you for having me.
swyx [00:00:20]: And Nikunj, who is most famously, if anyone has ever tried to get any access to anything on the API, Nikunj is the guy. So I know your emails because I look forward to them.
Nikunj [00:00:30]: Yeah, nice to meet all of you.
swyx [00:00:32]: I think that we're basically convening today to talk about the new API. So perhaps you guys want to just kick off. What is OpenAI launching today?
Nikunj [00:00:40]: Yeah, so I can kick it off. We're launching a bunch of new things today. We're going to do three new built-in tools. So we're launching the web search tool. This is basically chat GPD for search, but available in the API. We're launching an improved file search tool. So this is you bringing your data to OpenAI. You upload it. We, you know, take care of parsing it, chunking it. We're embedding it, making it searchable, give you this like ready vector store that you can use. So that's the file search tool. And then we're also launching our computer use tool. So this is the tool behind the operator product in chat GPD. So that's coming to developers today. And to support all of these tools, we're going to have a new API. So, you know, we launched chat completions, like I think March 2023 or so. It's been a while. So we're looking for an update over here to support all the new things that the models can do. And so we're launching this new API. It is, you know, it works with tools. We think it'll be like a great option for all the future agentic products that we build. And so that is also launching today. Actually, the last thing we're launching is the agents SDK. We launched this thing called Swarm last year where, you know, it was an experimental SDK for people to do multi-agent orchestration and stuff like that. It was supposed to be like educational experimental, but like people, people really loved it. They like ate it up. And so we are like, all right, let's, let's upgrade this thing. Let's give it a new name. And so we're calling it the agents SDK. It's going to have built-in tracing in the OpenAI dashboard. So lots of cool stuff going out. So, yeah.
Romain [00:02:14]: That's a lot, but we said 2025 was the year of agents. So there you have it, like a lot of new tools to build these agents for developers.
swyx [00:02:20]: Okay. I guess, I guess we'll just kind of go one by one and we'll leave the agents SDK towards the end. So responses API, I think the sort of primary concern that people have and something I think I've voiced to you guys when, when, when I was talking with you in the, in the planning process was, is chat completions going away? So I just wanted to let it, let you guys respond to the concerns that people might have.
Romain [00:02:41]: Chat completion is definitely like here to stay, you know, it's a bare metal API we've had for quite some time. Lots of tools built around it. So we want to make sure that it's maintained and people can confidently keep on building on it. At the same time, it was kind of optimized for a different world, right? It was optimized for a pre-multi-modality world. We also optimized for kind of single turn. It takes two problems. It takes prompt in, it takes response out. And now with these agentic workflows, we, we noticed that like developers and companies want to build longer horizon tasks, you know, like things that require multiple returns to get the task accomplished. And computer use is one of those, for instance. And so that's why the responses API came to life to kind of support these new agentic workflows. But chat completion is definitely here to stay.
swyx [00:03:27]: And assistance API, we've, uh, has a target sunset date of first half of 2020. So this is kind of like, in my mind, there was a kind of very poetic mirroring of the API with the models. This, I kind of view this as like kind of the merging of assistance API and chat completions, right. Into one unified responses. So it's kind of like how GPT and the old series models are also unifying.
Romain [00:03:48]: Yeah, that's exactly the right, uh, that's the right framing, right? Like, I think we took the best of what we learned from the assistance API, especially like being able to access tools very, uh, very like conveniently, but at the same time, like simplifying the way you have to integrate, like, you no longer have to think about six different objects to kind of get access to these tools with the responses API. You just get one API request and suddenly you can weave in those tools, right?
Nikunj [00:04:12]: Yeah, absolutely. And I think we're going to make it really easy and straightforward for assistance API users to migrate over to responsive. Right. To the API without any loss of functionality or data. So our plan is absolutely to add, you know, assistant like objects and thread light objects to that, that work really well with the responses API. We'll also add like the code interpreter tool, which is not launching today, but it'll come soon. And, uh, we'll add async mode to responses API, because that's another difference with, with, uh, assistance. I will have web hooks and stuff like that, but I think it's going to be like a pretty smooth transition. Uh, once we have all of that in place. And we'll be. Like a full year to migrate and, and help them through any issues they, they, they face. So overall, I feel like assistance users are really going to benefit from this longer term, uh, with this more flexible, primitive.
Alessio [00:05:01]: How should people think about when to use each type of API? So I know that in the past, the assistance was maybe more stateful, kind of like long running, many tool use kind of like file based things. And the chat completions is more stateless, you know, kind of like traditional completion API. Is that still the mental model that people should have? Or like, should you buy the.
Nikunj [00:05:20]: So the responses API is going to support everything that it's at launch, going to support everything that chat completion supports, and then over time, it's going to support everything that assistance supports. So it's going to be a pretty good fit for anyone starting out with open AI. Uh, they should be able to like go to responses responses, by the way, also has a stateless mode, so you can pass in store false and they'll make the whole API stateless, just like chat completions. You're really trying to like get this unification. A story in so that people don't have to juggle multiple endpoints. That being said, like chat completions, just like the most widely adopted API, it's it's so popular. So we're still going to like support it for years with like new models and features. But if you're a new user, you want to or if you want to like existing, you want to tap into some of these like built in tools or something, you should feel feel totally fine migrating to responses and you'll have more capabilities and performance than the tech completions.
swyx [00:06:16]: I think the messaging that I agree that I think resonated the most. When I talked to you was that it is a strict superset, right? Like you should be able to do everything that you could do in chat completions and with assistants. And the thing that I just assumed that because you're you're now, you know, by default is stateful, you're actually storing the chat logs or the chat state. I thought you'd be charging me for it. So, you know, to me, it was very surprising that you figured out how to make it free.
Nikunj [00:06:43]: Yeah, it's free. We store your state for 30 days. You can turn it off. But yeah, it's it's free. And the interesting thing on state is that it just like makes particularly for me, it makes like debugging things and building things so much simpler, where I can like create a responses object that's like pretty complicated and part of this more complex application that I've built, I can just go into my dashboard and see exactly what happened that mess up my prompt that is like not called one of these tools that misconfigure one of the tools like the visual observability of everything that you're doing is so, so helpful. So I'm excited, like about people trying that out and getting benefits from it, too.
swyx [00:07:19]: Yeah, it's a it's really, I think, a really nice to have. But all I'll say is that my friend Corey Quinn says that anything that can be used as a database will be used as a database. So be prepared for some abuse.
Romain [00:07:34]: All right. Yeah, that's a good one. Some of that I've tried with the metadata. That's some people are very, very creative at stuffing data into an object. Yeah.
Nikunj [00:07:44]: And we do have metadata with responses. Exactly. Yeah.
Alessio [00:07:48]: Let's get through it. All of these. So web search. I think the when I first said web search, I thought you were going to just expose a API that then return kind of like a nice list of thing. But the way it's name is like GPD for all search preview. So I'm guessing you have you're using basically the same model that is in the chat GPD search, which is fine tune for search. I'm guessing it's a different model than the base one. And it's impressive the jump in performance. So just to give an example, in simple QA, GPD for all is 38% accuracy for all search is 90%. But we always talk about. How tools are like models is not everything you need, like tools around it are just as important. So, yeah, maybe give people a quick review on like the work that went into making this special.
Nikunj [00:08:29]: Should I take that?
Alessio [00:08:29]: Yeah, go for it.
Nikunj [00:08:30]: So firstly, we're launching web search in two ways. One in responses API, which is our API for tools. It's going to be available as a web search tool itself. So you'll be able to go tools, turn on web search and you're ready to go. We still wanted to give chat completions people access to real time information. So in that. Chat completions API, which does not support built in tools. We're launching the direct access to the fine tuned model that chat GPD for search uses, and we call it GPD for search preview. And how is this model built? Basically, we have our search research team has been working on this for a while. Their main goal is to, like, get information, like get a bunch of information from all of our data sources that we use to gather information for search and then pick the right things and then cite them. As accurately as possible. And that's what the search team has really focused on. They've done some pretty cool stuff. They use like synthetic data techniques. They've done like all series model distillation to, like, make these four or fine tunes really good. But yeah, the main thing is, like, can it remain factual? Can it answer questions based on what it retrieves and get cited accurately? And that's what this like fine tune model really excels at. And so, yeah, so we're excited that, like, it's going to be directly available in chat completions along with being available as a tool. Yeah.
Alessio [00:09:49]: Just to clarify, if I'm using the responses API, this is a tool. But if I'm using chat completions, I have to switch model. I cannot use 01 and call search as a tool. Yeah, that's right. Exactly.
Romain [00:09:58]: I think what's really compelling, at least for me and my own uses of it so far, is that when you use, like, web search as a tool, it combines nicely with every other tool and every other feature of the platform. So think about this for a second. For instance, imagine you have, like, a responses API call with the web search tool, but suddenly you turn on function calling. You also turn on, let's say, structure. So you can have, like, the ability to structure any data from the web in real time in the JSON schema that you need for your application. So it's quite powerful when you start combining those features and tools together. It's kind of like an API for the Internet almost, you know, like you get, like, access to the precise schema you need for your app. Yeah.
Alessio [00:10:39]: And then just to wrap up on the infrastructure side of it, I read on the post that people, publisher can choose to appear in the web search. So are people by default in it? Like, how can we get Latent Space in the web search API?
Nikunj [00:10:53]: Yeah. Yeah. I think we have some documentation around how websites, publishers can control, like, what shows up in a web search tool. And I think you should be able to, like, read that. I think we should be able to get Latent Space in for sure. Yeah.
swyx [00:11:10]: You know, I think so. I compare this to a broader trend that I started covering last year of online LLMs. Actually, Perplexity, I think, was the first. It was the first to say, to offer an API that is connected to search, and then Gemini had the sort of search grounding API. And I think you guys, I actually didn't, I missed this in the original reading of the docs, but you even give like citations with like the exact sub paragraph that is matching, which I think is the standard nowadays. I think my question is, how do we take what a knowledge cutoff is for something like this, right? Because like now, basically there's no knowledge cutoff is always live, but then there's a difference between what the model has sort of internalized in its back propagation and what is searching up its rag.
Romain [00:11:53]: I think it kind of depends on the use case, right? And what you want to showcase as the source. Like, for instance, you take a company like Hebbia that has used this like web search tool. They can combine like for credit firms or law firms, they can find like, you know, public information from the internet with the live sources and citation that sometimes you do want to have access to, as opposed to like the internal knowledge. But if you're building something different, well, like, you just want to have the information. If you want to have an assistant that relies on the deep knowledge that the model has, you may not need to have these like direct citations. So I think it kind of depends on the use case a little bit, but there are many, uh, many companies like Hebbia that will need that access to these citations to precisely know where the information comes from.
swyx [00:12:34]: Yeah, yeah, uh, for sure. And then one thing on the, on like the breadth, you know, I think a lot of the deep research, open deep research implementations have this sort of hyper parameter about, you know, how deep they're searching and how wide they're searching. I don't see that in the docs. But is that something that we can tune? Is that something you recommend thinking about?
Nikunj [00:12:53]: Super interesting. It's definitely not a parameter today, but we should explore that. It's very interesting. I imagine like how you would do it with the web search tool and responsive API is you would have some form of like, you know, agent orchestration over here where you have a planning step and then each like web search call that you do like explicitly goes a layer deeper and deeper and deeper. But it's not a parameter that's available out of the box. But it's a cool. It's a cool thing to think about. Yeah.
swyx [00:13:19]: The only guidance I'll offer there is a lot of these implementations offer top K, which is like, you know, top 10, top 20, but actually don't really want that. You want like sort of some kind of similarity cutoff, right? Like some matching score cuts cutoff, because if there's only five things, five documents that match fine, if there's 500 that match, maybe that's what I want. Right. Yeah. But also that might, that might make my costs very unpredictable because the costs are something like $30 per a thousand queries, right? So yeah. Yeah.
Nikunj [00:13:49]: I guess you could, you could have some form of like a context budget and then you're like, go as deep as you can and pick the best stuff and put it into like X number of tokens. There could be some creative ways of, of managing cost, but yeah, that's a super interesting thing to explore.
Alessio [00:14:05]: Do you see people using the files and the search API together where you can kind of search and then store everything in the file so the next time I'm not paying for the search again and like, yeah, how should people balance that?
Nikunj [00:14:17]: That's actually a very interesting question. And let me first tell you about how I've seen a really cool way I've seen people use files and search together is they put their user preferences or memories in the vector store and so a query comes in, you use the file search tool to like get someone's like reading preferences or like fashion preferences and stuff like that, and then you search the web for information or products that they can buy related to those preferences and you then render something beautiful to show them, like, here are five things that you might be interested in. So that's how I've seen like file search, web search work together. And by the way, that's like a single responses API call, which is really cool. So you just like configure these things, go boom, and like everything just happens. But yeah, that's how I've seen like files and web work together.
Romain [00:15:01]: But I think that what you're pointing out is like interesting, and I'm sure developers will surprise us as they always do in terms of how they combine these tools and how they might use file search as a way to have memory and preferences, like Nikum says. But I think like zooming out, what I find very compelling and powerful here is like when you have these like neural networks. That have like all of the knowledge that they have today, plus real time access to the Internet for like any kind of real time information that you might need for your app and file search, where you can have a lot of company, private documents, private details, you combine those three, and you have like very, very compelling and precise answers for any kind of use case that your company or your product might want to enable.
swyx [00:15:41]: It's a difference between sort of internal documents versus the open web, right? Like you're going to need both. Exactly, exactly. I never thought about it doing memory as well. I guess, again, you know, anything that's a database, you can store it and you will use it as a database. That sounds awesome. But I think also you've been, you know, expanding the file search. You have more file types. You have query optimization, custom re-ranking. So it really seems like, you know, it's been fleshed out. Obviously, I haven't been paying a ton of attention to the file search capability, but it sounds like your team has added a lot of features.
Nikunj [00:16:14]: Yeah, metadata filtering was like the main thing people were asking us for for a while. And I'm super excited about it. I mean, it's just so critical once your, like, web store size goes over, you know, more than like, you know, 5,000, 10,000 records, you kind of need that. So, yeah, metadata filtering is coming, too.
Romain [00:16:31]: And for most companies, it's also not like a competency that you want to rebuild in-house necessarily, you know, like, you know, thinking about embeddings and chunking and, you know, how of that, like, it sounds like very complex for something very, like, obvious to ship for your users. Like companies like Navant, for instance. They were able to build with the file search, like, you know, take all of the FAQ and travel policies, for instance, that you have, you, you put that in file search tool, and then you don't have to think about anything. Now your assistant becomes naturally much more aware of all of these policies from the files.
swyx [00:17:03]: The question is, like, there's a very, very vibrant RAG industry already, as you well know. So there's many other vector databases, many other frameworks. Probably if it's an open source stack, I would say like a lot of the AI engineers that I talk to want to own this part of the stack. And it feels like, you know, like, when should we DIY and when should we just use whatever OpenAI offers?
Nikunj [00:17:24]: Yeah. I mean, like, if you're doing something completely from scratch, you're going to have more control, right? Like, so super supportive of, you know, people trying to, like, roll up their sleeves, build their, like, super custom chunking strategy and super custom retrieval strategy and all of that. And those are things that, like, will be harder to do with OpenAI tools. OpenAI tool has, like, we have an out-of-the-box solution. We give you the tools. We use some knobs to customize things, but it's more of, like, a managed RAG service. So my recommendation would be, like, start with the OpenAI thing, see if it, like, meets your needs. And over time, we're going to be adding more and more knobs to make it even more customizable. But, you know, if you want, like, the completely custom thing, you want control over every single thing, then you'd probably want to go and hand roll it using other solutions. So we're supportive of both, like, engineers should pick. Yeah.
Alessio [00:18:16]: And then we got computer use. Which I think Operator was obviously one of the hot releases of the year. And we're only two months in. Let's talk about that. And that's also, it seems like a separate model that has been fine-tuned for Operator that has browser access.
Nikunj [00:18:31]: Yeah, absolutely. I mean, the computer use models are exciting. The cool thing about computer use is that we're just so, so early. It's like the GPT-2 of computer use or maybe GPT-1 of computer use right now. But it is a separate model that has been, you know, the computer. The computer use team has been working on, you send it screenshots and it tells you what action to take. So the outputs of it are almost always tool calls and you're inputting screenshots based on whatever computer you're trying to operate.
Romain [00:19:01]: Maybe zooming out for a second, because like, I'm sure your audience is like super, super like AI native, obviously. But like, what is computer use as a tool, right? And what's operator? So the idea for computer use is like, how do we let developers also build agents that can complete tasks for the users, but using a computer? Okay. Or a browser instead. And so how do you get that done? And so that's why we have this custom model, like optimized for computer use that we use like for operator ourselves. But the idea behind like putting it as an API is that imagine like now you want to, you want to automate some tasks for your product or your own customers. Then now you can, you can have like the ability to spin up one of these agents that will look at the screen and act on the screen. So that means able, the ability to click, the ability to scroll. The ability to type and to report back on the action. So that's what we mean by computer use and wrapping it as a tool also in the responses API. So now like that gives a hint also at the multi-turned thing that we were hinting at earlier, the idea that like, yeah, maybe one of these actions can take a couple of minutes to complete because there's maybe like 20 steps to complete that task. But now you can.
swyx [00:20:08]: Do you think a computer use can play Pokemon?
Romain [00:20:11]: Oh, interesting. I guess we tried it. I guess we should try it. You know?
swyx [00:20:17]: Yeah. There's a lot of interest. I think Pokemon really is a good agent benchmark, to be honest. Like it seems like Claude is, Claude is running into a lot of trouble.
Romain [00:20:25]: Sounds like we should make that a new eval, it looks like.
swyx [00:20:28]: Yeah. Yeah. Oh, and then one more, one more thing before we move on to agents SDK. I know you have a hard stop. There's all these, you know, blah, blah, dash preview, right? Like search preview, computer use preview, right? And you see them all like fine tunes of 4.0. I think the question is, are we, are they all going to be merged into the main branch or are we basically always going to have subsets? Of these models?
Nikunj [00:20:49]: Yeah, I think in the early days, research teams at OpenAI like operate with like fine tune models. And then once the thing gets like more stable, we sort of merge it into the main line. So that's definitely the vision, like going out of preview as we get more comfortable with and learn about all the developer use cases and we're doing a good job at them. We'll sort of like make them part of like the core models so that you don't have to like deal with the bifurcation.
Romain [00:21:12]: You should think of it this way as exactly what happened last year when we introduced vision capabilities, you know. Yes. Vision capabilities were in like a vision preview model based off of GPT-4 and then vision capabilities now are like obviously built into GPT-4.0. You can think about it the same way for like the other modalities like audio and those kind of like models, like optimized for search and computer use.
swyx [00:21:34]: Agents SDK, we have a few minutes left. So let's just assume that everyone has looked at Swarm. Sure. I think that Swarm has really popularized the handoff technique, which I thought was like, you know, really, really interesting for sort of a multi-agent. What is new with the SDK?
Nikunj [00:21:50]: Yeah. Do you want to start? Yeah, for sure. So we've basically added support for types. We've made this like a lot. Yeah. Like we've added support for types. We've added support for guard railing, which is a very common pattern. So in the guardrail example, you basically have two things happen in parallel. The guardrail can sort of block the execution. It's a type of like optimistic generation that happens. And I think we've added support for tracing. So I think that's really cool. So you can basically look at the traces that the Agents SDK creates in the OpenAI dashboard. We also like made this pretty flexible. So you can pick any API from any provider that supports the ChatCompletions API format. So it supports responses by default, but you can like easily plug it in to anyone that uses the ChatCompletions API. And similarly, on the tracing side, you can support like multiple tracing providers. By default, it sort of points to the OpenAI dashboard. But, you know, there's like so many tracing providers. There's so many tracing companies out there. And we'll announce some partnerships on that front, too. So just like, you know, adding lots of core features and making it more usable, but still centered around like handoffs is like the main, main concept.
Romain [00:22:59]: And by the way, it's interesting, right? Because Swarm just came to life out of like learning from customers directly that like orchestrating agents in production was pretty hard. You know, simple ideas could quickly turn very complex. Like what are those guardrails? What are those handoffs, et cetera? So that came out of like learning from customers. And it was initially shipped. It was not as a like low-key experiment, I'd say. But we were kind of like taken by surprise at how much momentum there was around this concept. And so we decided to learn from that and embrace it. To be like, okay, maybe we should just embrace that as a core primitive of the OpenAI platform. And that's kind of what led to the Agents SDK. And I think now, as Nikuj mentioned, it's like adding all of these new capabilities to it, like leveraging the handoffs that we had, but tracing also. And I think what's very compelling for developers is like instead of having one agent to rule them all and you stuff like a lot of tool calls in there that can be hard to monitor, now you have the tools you need to kind of like separate the logic, right? And you can have a triage agent that based on an intent goes to different kind of agents. And then on the OpenAI dashboard, we're releasing a lot of new user interface logs as well. So you can see all of the tracing UIs. Essentially, you'll be able to troubleshoot like what exactly happened. In that workflow, when the triage agent did a handoff to a secondary agent and the third and see the tool calls, et cetera. So we think that the Agents SDK combined with the tracing UIs will definitely help users and developers build better agentic workflows.
Alessio [00:24:28]: And just before we wrap, are you thinking of connecting this with also the RFT API? Because I know you already have, you kind of store my text completions and then I can do fine tuning of that. Is that going to be similar for agents where you're storing kind of like my traces? And then help me improve the agents?
Nikunj [00:24:43]: Yeah, absolutely. Like you got to tie the traces to the evals product so that you can generate good evals. Once you have good evals and graders and tasks, you can use that to do reinforcement fine tuning. And, you know, lots of details to be figured out over here. But that's the vision. And I think we're going to go after it like pretty hard and hope we can like make this whole workflow a lot easier for developers.
Alessio [00:25:05]: Awesome. Thank you so much for the time. I'm sure you'll be busy on Twitter tomorrow with all the developer feedback. Yeah.
Romain [00:25:12]: Thank you so much for having us. And as always, we can't wait to see what developers will build with these tools and how we can like learn as quickly as we can from them to make them even better over time.
Nikunj [00:25:21]: Yeah.
Romain [00:25:22]: Thank you, guys.
Nikunj [00:25:23]: Thank you.
Romain [00:25:23]: Thank you both. Awesome.