



In the Matter of OpenAI vs LangGraph
The silent war in Agent Engineering gets loud.
Quick reminder: AI Engineer CFPs close soon! Take a look at “undervalued tracks” like Computer Use, Voice, and Reasoning, and apply via our CFP MCP (talks OR workshops, we’ll figure it out).
Relevant to today’s quick post we do have an Agent Reliability track. Also: take the 2025 State of AI Engineering Survey!
The AI attention economy has enabled a hypeboi priesthood who exist in a perpetual state of performative orgasmic nirvana, minds continually blown as every launch Changes Everything, vibing at gigahertz oscillations of “it’s so over” vs “so back”. OpenAI’s “Practical Guide to Building Agents” is the latest such earth shatterer:
This guide, however, has been less well received than Anthropic’s equivalent.
If you watch his multiple appearances with us, Harrison Chase is not someone who is quick to “anger”, so calling this guide “misguided” and doing a word by word teardown can seem like fighting words for him1.

At the heart of the battle is a core tension we’ve discussed several times on the pod - team “Big Model take the wheel” vs team “nooooo we need to write code” (what used to be called chains, now it seems the term “workflows” has won).
Team Big Workflows
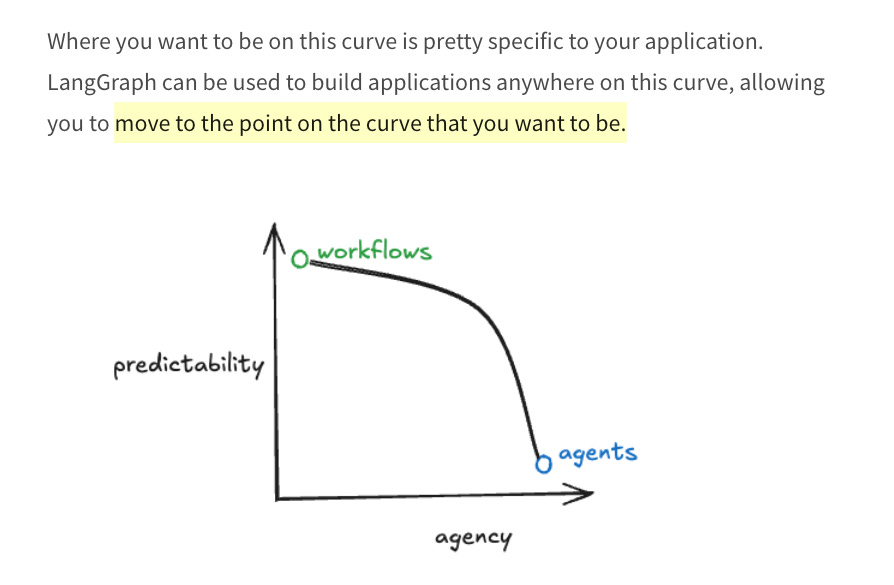
You should read Harrison’s full rebuttal for the argument, but minus the LangGraph specific parts, the argument that stood out best to me was that you can replace every LLM call in a workflow with an agent and still have an agentic system:

And the ideal agent framework lets you start from one side of the spectrum and move to the other, optimizing for making code easy to change:
Team Big Model
To be clear it’s easy to understand where the Big Model folks are coming from: if you work with Big Lab enough, you’ve seen hundreds of engineer-hours of hand tuned workflows obliterated overnight with the next big model update — the AI Engineer equivalent of learning the Bitter Lesson again and again. This is why “AI engineering with the Bitter Lesson in mind” was such a resonant topic at the Summit (now at 124k views across platforms):
Specifically, I think the success of both OpenAI and Gemini’s Deep Research this year primarily leveraging O3 to reason through research planning and execution, and later Bolt and Manus AI doing the same with Claude, with very little workflow engineering, has demonstrated that there’s a lot to be said for building general purpose agents that simply augment models without the “inductive bias” constraints of workflows. O-team researcher Hyung Won Chung noted that adding more structure gets you wins in the short term, but that structure tends to lose in performance as the model (pretrain or inference compute) keeps scaling up.
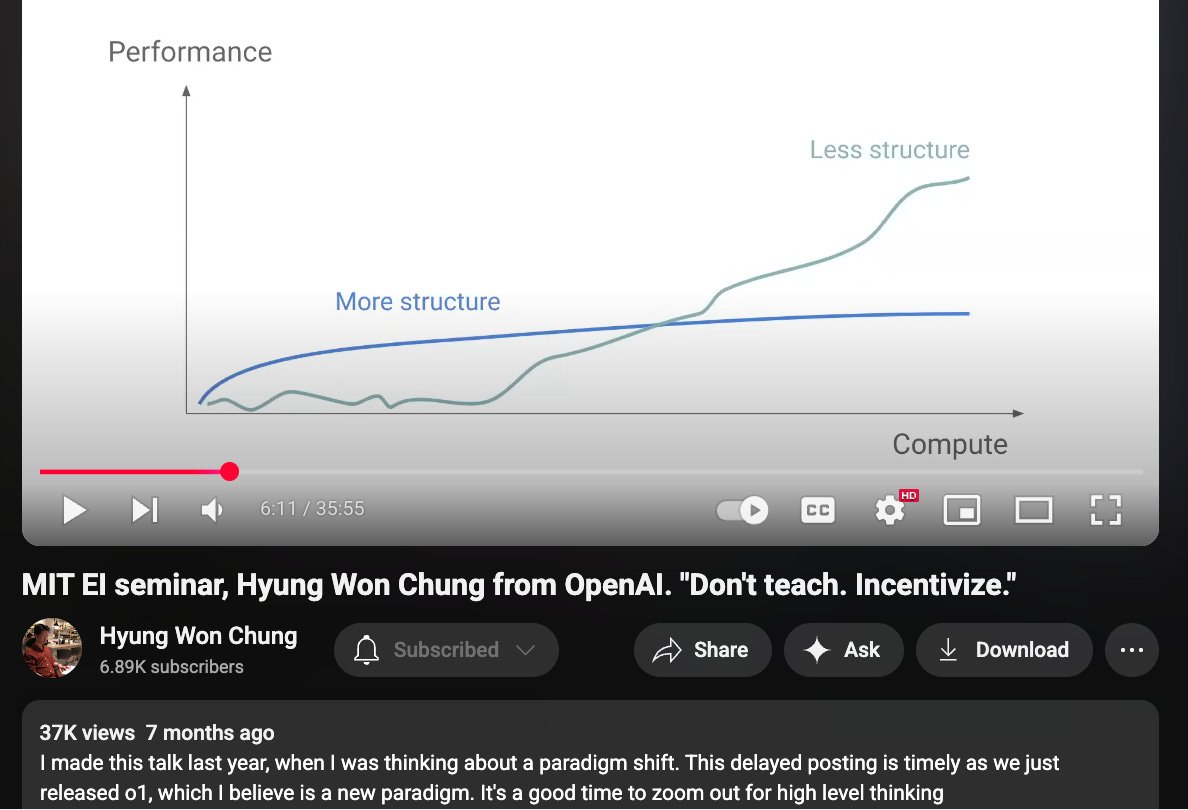
If your goal is to build AGI, to build a horizontal platform, particularly one targeting non-technical consumers who are confused by even having a model selector, then it’s an understandable position to take, and (even encourage, for the purposes of dataset/human feedback collection).
Workflows AND Agents, not OR
Ultimately the reason I argue Harrison isn’t -actually- taking a fighting stance is he leaves room for the spectrum to exist and makes a remarkably (for someone with obvious skin in the game) balanced argument that you’re going to just want options for doing both:
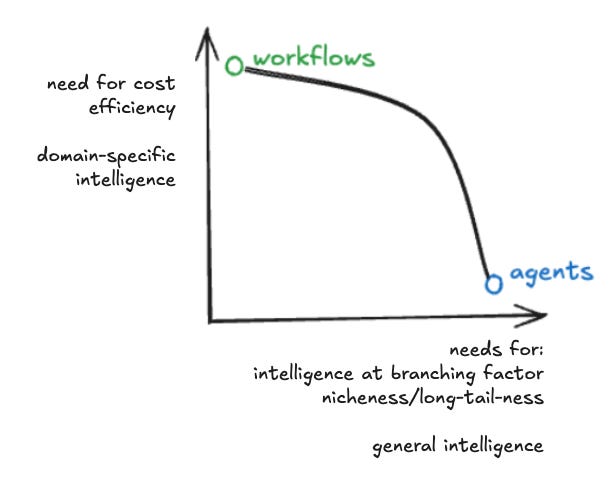
I find this hard to debate - if meaningful conversation is to be had, it really is more about where the current state of this Pareto frontier really is today (I’m not sure it is convex yet) and how to move it out.
IMPACT of Agent Frameworks
The other pretty cool thing that Harrison did in his piece was publish a full comparison table of all relevant Agent Frameworks today, although of course even he couldn’t escape the McCormick trap. It’s useful to test our descriptive metaframework of everybody’s Agent definitions against a new out-of-distribution Agents definition:
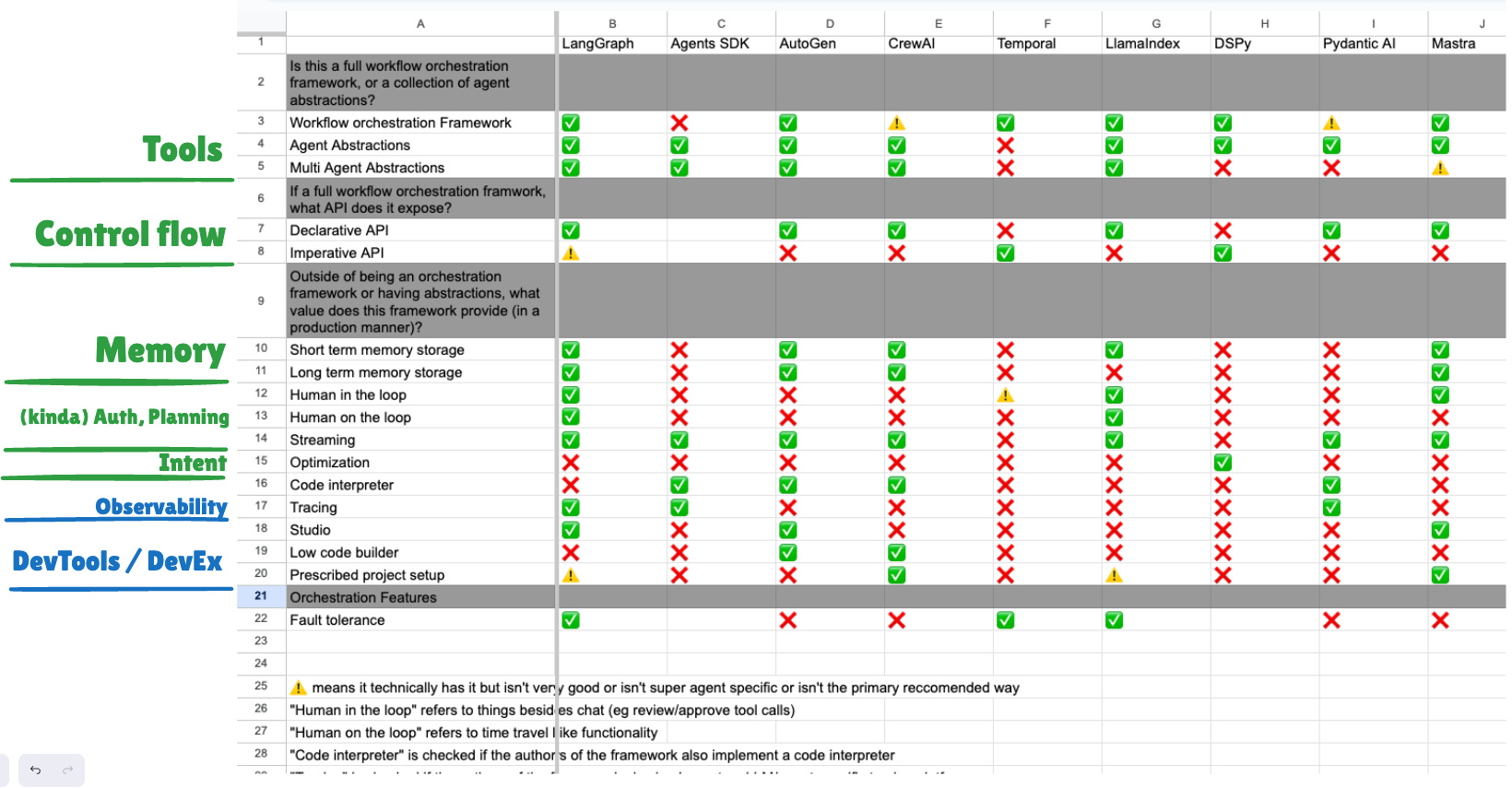
I think this is a remarkably fair shopping list of abstractions and features for the discerning Agent Engineer — it also articulates why you feel certain gaps when an Agent Framework promises you the world and yet you can’t do some things easily.
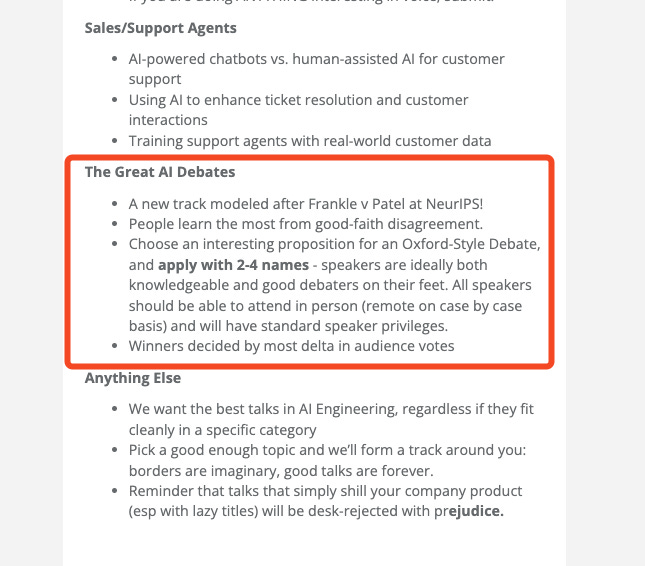
The Great Debates
If you like this kind of debate, we’re doubling down on the success of the Dylan v Frankle showdown from last year’s NeurIPS, and also accepting submissions for what we’re calling “The Great Debates” - good faith debaters from two sides of a relevant industry debate. Everybody wins, but the people who are best able to change minds win the most. Apply in pairs!
As I’ll argue: they’re actually not! Harrison is ever the diplomat.
I would also put in guardrails, evals, tool use & cost/time monitors as others important bits for agentic products in production.
nicely done, great read ...