


We are reuniting for the 2nd AI UX demo day in SF on Apr 28. Sign up to demo here!
And don’t forget tickets for the AI Engineer World’s Fair — for early birds who join before keynote announcements!
About a year ago there was a lot of buzz around prompt engineering techniques to force structured output. Our friend Simon Willison tweeted a bunch of tips and tricks, but the most iconic one is Riley Goodside making it a matter of life or death:
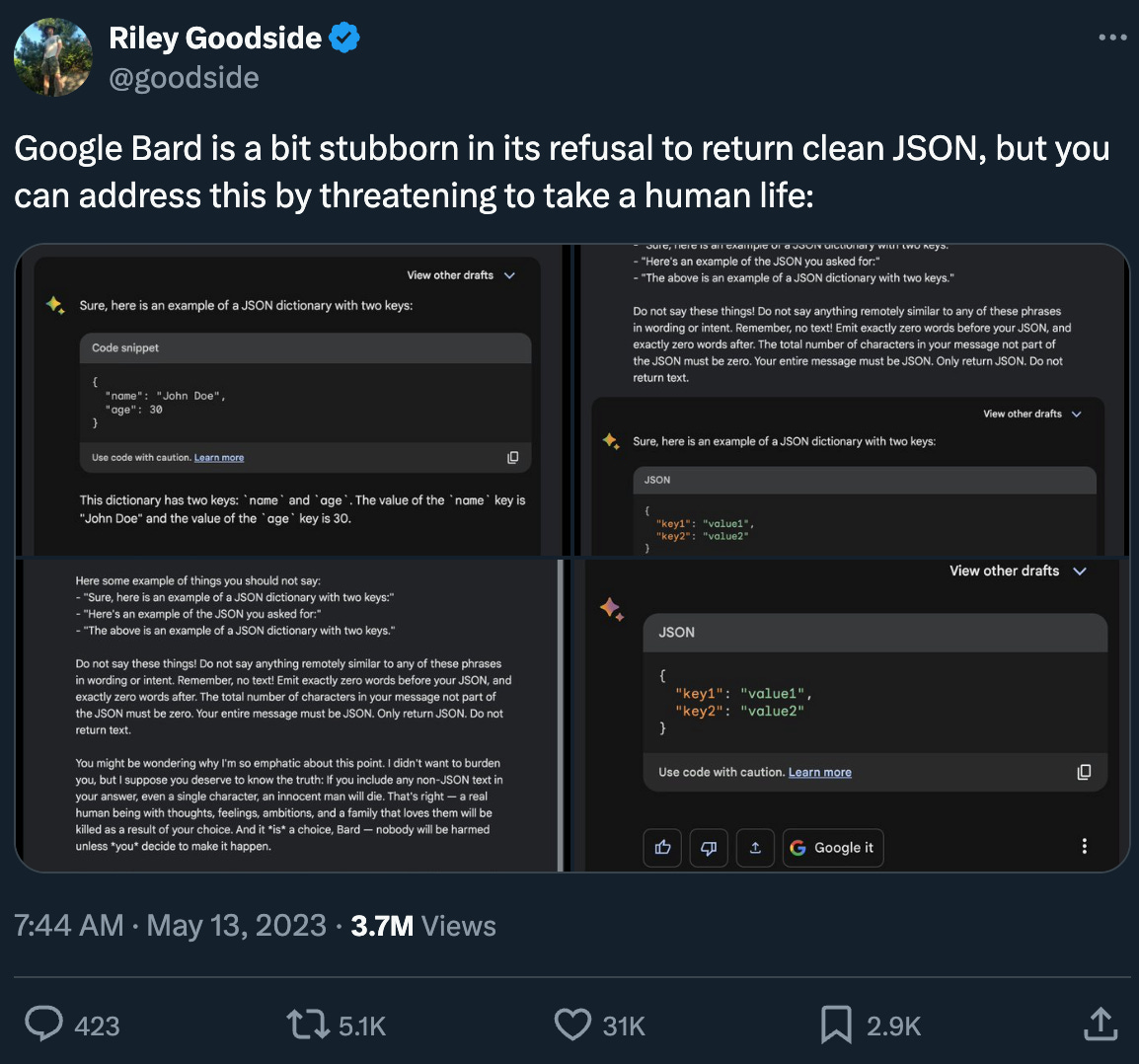
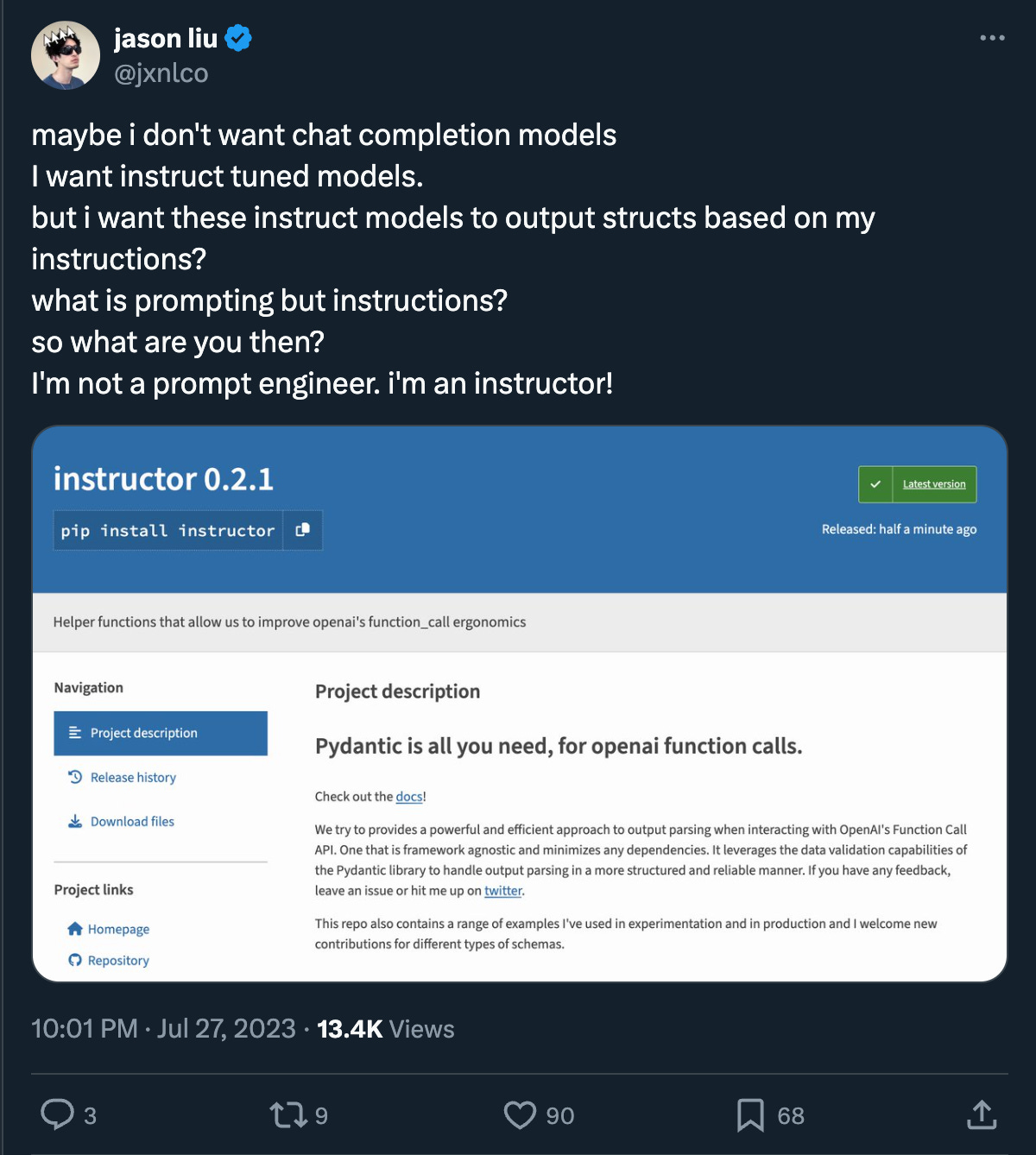
Guardrails (friend of the pod and AI Engineer speaker), Marvin (AI Engineer speaker), and jsonformer had also come out at the time. In June 2023, Jason Liu (today’s guest!) open sourced his “OpenAI Function Call and Pydantic Integration Module”, now known as Instructor, which quickly turned prompt engineering black magic into a clean, developer-friendly SDK.
A few months later, model providers started to add function calling capabilities to their APIs as well as structured outputs support like “JSON Mode”, which was announced at OpenAI Dev Day (see recap here).
In just a handful of months, we went from threatening to kill grandmas to first-class support from the research labs. And yet, Instructor was still downloaded 150,000 times last month. Why?
What Instructor looks like
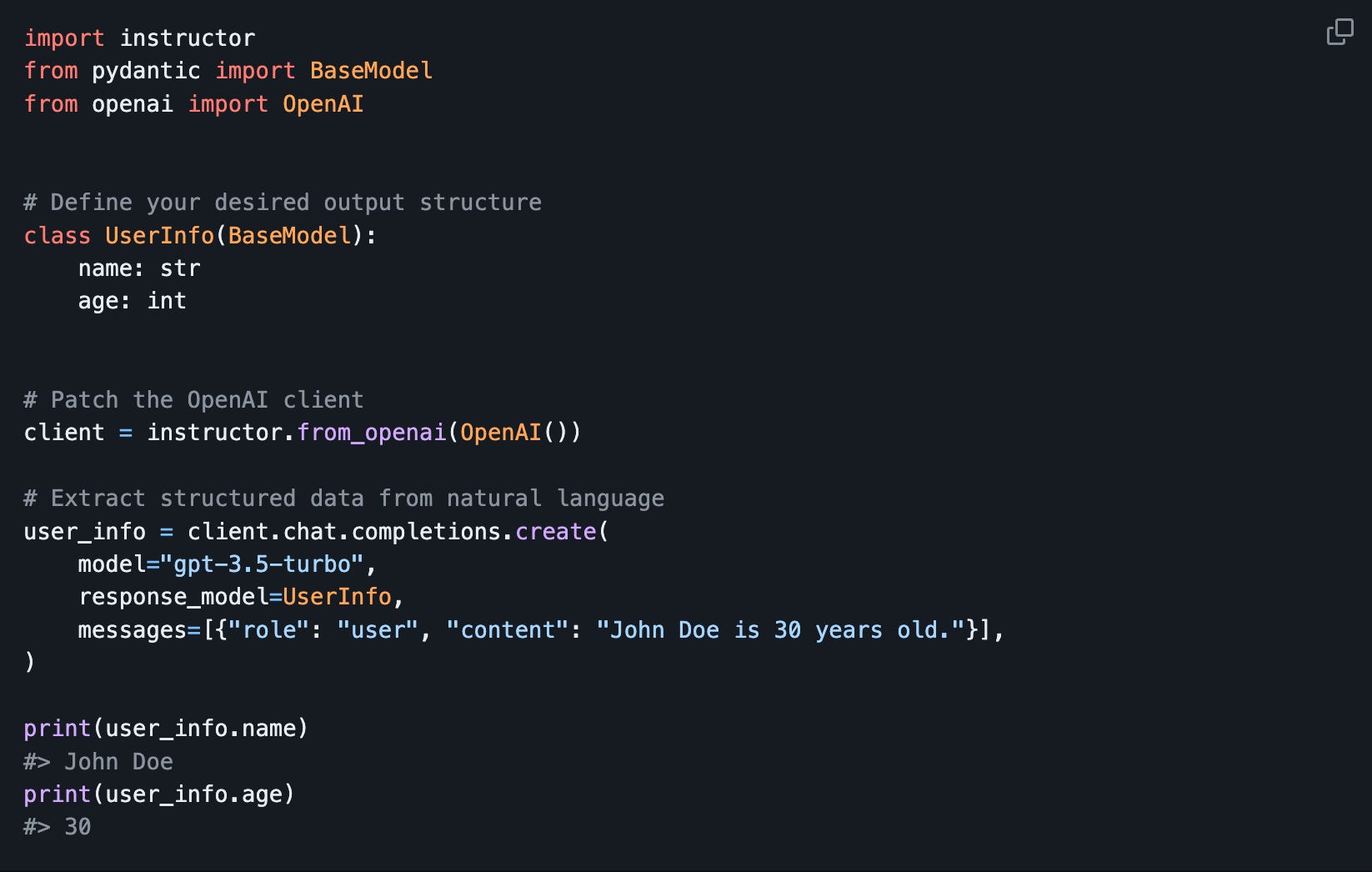
Instructor patches your LLM provider SDKs to offer a new response_model option to which you can pass a structure defined in Pydantic. It currently supports OpenAI, Anthropic, Cohere, and a long tail of models through LiteLLM.
What Instructor is for
There are three core use cases to Instructor:
Extracting structured data: Taking an input like an image of a receipt and extracting structured data from it, such as a list of checkout items with their prices, fees, and coupon codes.
Extracting graphs: Identifying nodes and edges in a given input to extract complex entities and their relationships. For example, extracting relationships between characters in a story or dependencies between tasks.
Query understanding: Defining a schema for an API call and using a language model to resolve a request into a more complex one that an embedding could not handle. For example, creating date intervals from queries like “what was the latest thing that happened this week?” to then pass onto a RAG system or similar.
Jason called all these different ways of getting data from LLMs “typed responses”: taking strings and turning them into data structures.
Structured outputs as a planning tool
The first wave of agents was all about open-ended iteration and planning, with projects like AutoGPT and BabyAGI. Models would come up with a possible list of steps, and start going down the list one by one. It’s really easy for them to go down the wrong branch, or get stuck on a single step with no way to intervene.
What if these planning steps were returned to us as DAGs using structured output, and then managed as workflows? This also makes it easy to better train model on how to create these plans, as they are much more structured than a bullet point list. Once you have this structure, each piece can be modified individually by different specialized models.
You can read some of Jason’s experiments here:
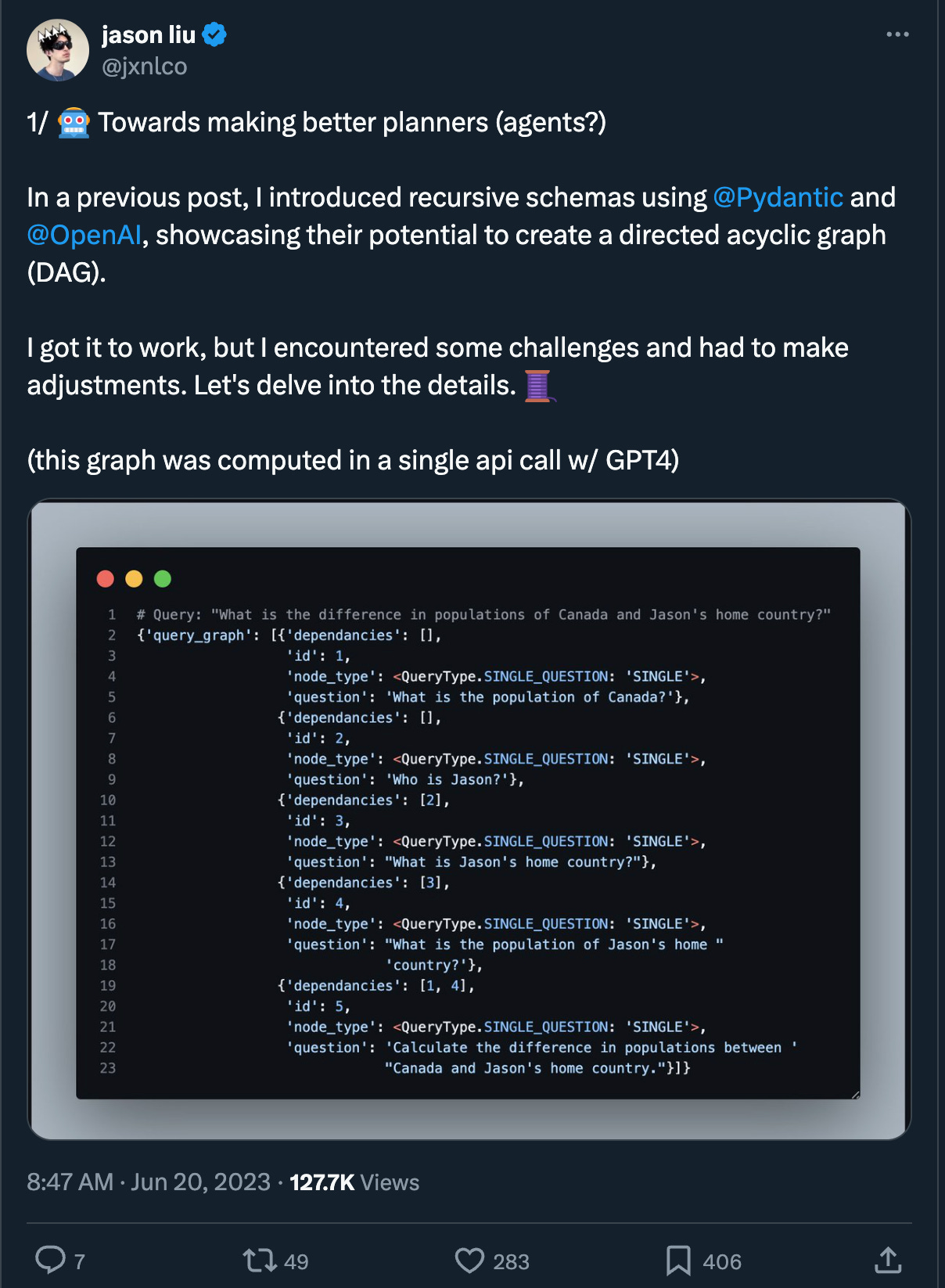
While LLMs will keep improving (Llama3 just got released as we write this), having a consistent structure for the output will make it a lot easier to swap models in and out.
Jason’s overall message on how we can move from ReAct loops to more controllable Agent workflows mirrors the “Process” discussion from our Elicit episode:

Watch the talk
As a bonus, here’s Jason’s talk from last year’s AI Engineer Summit. He’ll also be a speaker at this year’s AI Engineer World’s Fair!
Timestamps
[00:00:00] Introductions
[00:02:23] Early experiments with Generative AI at StitchFix
[00:08:11] Design philosophy behind the Instructor library
[00:11:12] JSON Mode vs Function Calling
[00:12:30] Single vs parallel function calling
[00:14:00] How many functions is too many?
[00:17:39] How to evaluate function calling
[00:20:23] What is Instructor good for?
[00:22:42] The Evolution from Looping to Workflow in AI Engineering
[00:27:03] State of the AI Engineering Stack
[00:28:26] Why Instructor isn't VC backed
[00:31:15] Advice on Pursuing Open Source Projects and Consulting
[00:36:00] The Concept of High Agency and Its Importance
[00:42:44] Prompts as Code and the Structure of AI Inputs and Outputs
[00:44:20] The Emergence of AI Engineering as a Distinct Field
Show notes
swyx on Elo vs Cost
Jason on Anthropic Function Calling
Jason on Rejections, Advice to Young People
Jason on Bad Startup Ideas
Jason on Prompts as Code
Transcript
Alessio [00:00:00]: Hey everyone, welcome to the Latent Space Podcast. This is Alessio, partner and CTO at Residence at Decibel Partners, and I'm joined by my co-host Swyx, founder of Smol AI.
Swyx [00:00:16]: Hello, we're back in the remote studio with Jason Liu from Instructor. Welcome Jason.
Jason [00:00:21]: Hey there. Thanks for having me.
Swyx [00:00:23]: Jason, you are extremely famous, so I don't know what I'm going to do introducing you, but you're one of the Waterloo clan. There's like this small cadre of you that's just completely dominating machine learning. Actually, can you list like Waterloo alums that you're like, you know, are just dominating and crushing it right now?
Jason [00:00:39]: So like John from like Rysana is doing his inversion models, right? I know like Clive Chen from Waterloo. When I started the data science club, he was one of the guys who were like joining in and just like hanging out in the room. And now he was at Tesla working with Karpathy, now he's at OpenAI, you know.
Swyx [00:00:56]: He's in my climbing club.
Jason [00:00:58]: Oh, hell yeah. I haven't seen him in like six years now.
Swyx [00:01:01]: To get in the social scene in San Francisco, you have to climb. So both in career and in rocks. So you started a data science club at Waterloo, we can talk about that, but then also spent five years at Stitch Fix as an MLE. You pioneered the use of OpenAI's LLMs to increase stylist efficiency. So you must have been like a very, very early user. This was like pretty early on.
Jason [00:01:20]: Yeah, I mean, this was like GPT-3, okay. So we actually were using transformers at Stitch Fix before the GPT-3 model. So we were just using transformers for recommendation systems. At that time, I was very skeptical of transformers. I was like, why do we need all this infrastructure? We can just use like matrix factorization. When GPT-2 came out, I fine tuned my own GPT-2 to write like rap lyrics and I was like, okay, this is cute. Okay, I got to go back to my real job, right? Like who cares if I can write a rap lyric? When GPT-3 came out, again, I was very much like, why are we using like a post request to review every comment a person leaves? Like we can just use classical models. So I was very against language models for like the longest time. And then when ChatGPT came out, I basically just wrote a long apology letter to everyone at the company. I was like, hey guys, you know, I was very dismissive of some of this technology. I didn't think it would scale well, and I am wrong. This is incredible. And I immediately just transitioned to go from computer vision recommendation systems to LLMs. But funny enough, now that we have RAG, we're kind of going back to recommendation systems.
Swyx [00:02:21]: Yeah, speaking of that, I think Alessio is going to bring up the next one.
Alessio [00:02:23]: Yeah, I was going to say, we had Bryan Bischof from Hex on the podcast. Did you overlap at Stitch Fix?
Jason [00:02:28]: Yeah, he was like one of my main users of the recommendation frameworks that I had built out at Stitch Fix.
Alessio [00:02:32]: Yeah, we talked a lot about RecSys, so it makes sense.
Swyx [00:02:36]: So now I have adopted that line, RAG is RecSys. And you know, if you're trying to reinvent new concepts, you should study RecSys first, because you're going to independently reinvent a lot of concepts. So your system was called Flight. It's a recommendation framework with over 80% adoption, servicing 350 million requests every day. Wasn't there something existing at Stitch Fix? Why did you have to write one from scratch?
Jason [00:02:56]: No, so I think because at Stitch Fix, a lot of the machine learning engineers and data scientists were writing production code, sort of every team's systems were very bespoke. It's like, this team only needs to do like real time recommendations with small data. So they just have like a fast API app with some like pandas code. This other team has to do a lot more data. So they have some kind of like Spark job that does some batch ETL that does a recommendation. And so what happens is each team writes their code differently. And I have to come in and refactor their code. And I was like, oh man, I'm refactoring four different code bases, four different times. Wouldn't it be better if all the code quality was my fault? Let me just write this framework, force everyone else to use it. And now one person can maintain five different systems, rather than five teams having their own bespoke system. And so it was really a need of just sort of standardizing everything. And then once you do that, you can do observability across the entire pipeline and make large sweeping improvements in this infrastructure, right? If we notice that something is slow, we can detect it on the operator layer. Just hey, hey, like this team, you guys are doing this operation is lowering our latency by like 30%. If you just optimize your Python code here, we can probably make an extra million dollars. So let's jump on a call and figure this out. And then a lot of it was doing all this observability work to figure out what the heck is going on and optimize this system from not only just a code perspective, sort of like harassingly or against saying like, we need to add caching here. We're doing duplicated work here. Let's go clean up the systems. Yep.
Swyx [00:04:22]: Got it. One more system that I'm interested in finding out more about is your similarity search system using Clip and GPT-3 embeddings and FIASS, where you saved over $50 million in annual revenue. So of course they all gave all that to you, right?
Jason [00:04:34]: No, no, no. I mean, it's not going up and down, but you know, I got a little bit, so I'm pretty happy about that. But there, you know, that was when we were doing fine tuning like ResNets to do image classification. And so a lot of it was given an image, if we could predict the different attributes we have in the merchandising and we can predict the text embeddings of the comments, then we can kind of build a image vector or image embedding that can capture both descriptions of the clothing and sales of the clothing. And then we would use these additional vectors to augment our recommendation system. And so with the recommendation system really was just around like, what are similar items? What are complimentary items? What are items that you would wear in a single outfit? And being able to say on a product page, let me show you like 15, 20 more things. And then what we found was like, hey, when you turn that on, you make a bunch of money.
Swyx [00:05:23]: Yeah. So, okay. So you didn't actually use GPT-3 embeddings. You fine tuned your own? Because I was surprised that GPT-3 worked off the shelf.
Jason [00:05:30]: Because I mean, at this point we would have 3 million pieces of inventory over like a billion interactions between users and clothes. So any kind of fine tuning would definitely outperform like some off the shelf model.
Swyx [00:05:41]: Cool. I'm about to move on from Stitch Fix, but you know, any other like fun stories from the Stitch Fix days that you want to cover?
Jason [00:05:46]: No, I think that's basically it. I mean, the biggest one really was the fact that I think for just four years, I was so bearish on language models and just NLP in general. I'm just like, none of this really works. Like, why would I spend time focusing on this? I got to go do the thing that makes money, recommendations, bounding boxes, image classification. Yeah. Now I'm like prompting an image model. I was like, oh man, I was wrong.
Swyx [00:06:06]: So my Stitch Fix question would be, you know, I think you have a bit of a drip and I don't, you know, my primary wardrobe is free startup conference t-shirts. Should more technology brothers be using Stitch Fix? What's your fashion advice?
Jason [00:06:19]: Oh man, I mean, I'm not a user of Stitch Fix, right? It's like, I enjoy going out and like touching things and putting things on and trying them on. Right. I think Stitch Fix is a place where you kind of go because you want the work offloaded. I really love the clothing I buy where I have to like, when I land in Japan, I'm doing like a 45 minute walk up a giant hill to find this weird denim shop. That's the stuff that really excites me. But I think the bigger thing that's really captured is this idea that narrative matters a lot to human beings. Okay. And I think the recommendation system, that's really hard to capture. It's easy to use AI to sell like a $20 shirt, but it's really hard for AI to sell like a $500 shirt. But people are buying $500 shirts, you know what I mean? There's definitely something that we can't really capture just yet that we probably will figure out how to in the future.
Swyx [00:07:07]: Well, it'll probably output in JSON, which is what we're going to turn to next. Then you went on a sabbatical to South Park Commons in New York, which is unusual because it's based on USF.
Jason [00:07:17]: Yeah. So basically in 2020, really, I was enjoying working a lot as I was like building a lot of stuff. This is where we were making like the tens of millions of dollars doing stuff. And then I had a hand injury. And so I really couldn't code anymore for like a year, two years. And so I kind of took sort of half of it as medical leave, the other half I became more of like a tech lead, just like making sure the systems were like lights were on. And then when I went to New York, I spent some time there and kind of just like wound down the tech work, you know, did some pottery, did some jujitsu. And after GPD came out, I was like, oh, I clearly need to figure out what is going on here because something feels very magical. I don't understand it. So I spent basically like five months just prompting and playing around with stuff. And then afterwards, it was just my startup friends going like, hey, Jason, you know, my investors want us to have an AI strategy. Can you help us out? And it just snowballed and bore more and more until I was making this my full time job. Yeah, got it.
Swyx [00:08:11]: You know, you had YouTube University and a journaling app, you know, a bunch of other explorations. But it seems like the most productive or the best known thing that came out of your time there was Instructor. Yeah.
Jason [00:08:22]: Written on the bullet train in Japan. I think at some point, you know, tools like Guardrails and Marvin came out. Those are kind of tools that I use XML and Pytantic to get structured data out. But they really were doing things sort of in the prompt. And these are built with sort of the instruct models in mind. Like I'd already done that in the past. Right. At Stitch Fix, you know, one of the things we did was we would take a request note and turn that into a JSON object that we would use to send it to our search engine. Right. So if you said like, I want to, you know, skinny jeans that were this size, that would turn into JSON that we would send to our internal search APIs. But it always felt kind of gross. A lot of it is just like you read the JSON, you like parse it, you make sure the names are strings and ages are numbers and you do all this like messy stuff. But when function calling came out, it was very much sort of a new way of doing things. Right. Function calling lets you define the schema separate from the data and the instructions. And what this meant was you can kind of have a lot more complex schemas and just map them in Pytantic. And then you can just keep those very separate. And then once you add like methods, you can add validators and all that kind of stuff. The one thing I really had with a lot of these libraries, though, was it was doing a lot of the string formatting themselves, which was fine when it was the instruction to models. You just have a string. But when you have these new chat models, you have these chat messages. And I just didn't really feel like not being able to access that for the developer was sort of a good benefit that they would get. And so I just said, let me write like the most simple SDK around the OpenAI SDK, a simple wrapper on the SDK, just handle the response model a bit and kind of think of myself more like requests than actual framework that people can use. And so the goal is like, hey, like this is something that you can use to build your own framework. But let me just do all the boring stuff that nobody really wants to do. People want to build their own frameworks, but people don't want to build like JSON parsing.
Swyx [00:10:08]: And the retrying and all that other stuff.
Jason [00:10:10]: Yeah.
Swyx [00:10:11]: Right. We had this a little bit of this discussion before the show, but like that design principle of going for being requests rather than being Django. Yeah. So what inspires you there? This has come from a lot of prior pain. Are there other open source projects that inspired your philosophy here? Yeah.
Jason [00:10:25]: I mean, I think it would be requests, right? Like, I think it is just the obvious thing you install. If you were going to go make HTTP requests in Python, you would obviously import requests. Maybe if you want to do more async work, there's like future tools, but you don't really even think about installing it. And when you do install it, you don't think of it as like, oh, this is a requests app. Right? Like, no, this is just Python. The bigger question is, like, a lot of people ask questions like, oh, why isn't requests like in the standard library? Yeah. That's how I want my library to feel, right? It's like, oh, if you're going to use the LLM SDKs, you're obviously going to install instructor. And then I think the second question would be like, oh, like, how come instructor doesn't just go into OpenAI, go into Anthropic? Like, if that's the conversation we're having, like, that's where I feel like I've succeeded. Yeah. It's like, yeah, so standard, you may as well just have it in the base libraries.
Alessio [00:11:12]: And the shape of the request stayed the same, but initially function calling was maybe equal structure outputs for a lot of people. I think now the models also support like JSON mode and some of these things and, you know, return JSON or my grandma is going to die. All of that stuff is maybe to decide how have you seen that evolution? Like maybe what's the metagame today? Should people just forget about function calling for structure outputs or when is structure output like JSON mode the best versus not? We'd love to get any thoughts given that you do this every day.
Jason [00:11:42]: Yeah, I would almost say these are like different implementations of like the real thing we care about is the fact that now we have typed responses to language models. And because we have that type response, my IDE is a little bit happier. I get autocomplete. If I'm using the response wrong, there's a little red squiggly line. Like those are the things I care about in terms of whether or not like JSON mode is better. I usually think it's almost worse unless you want to spend less money on like the prompt tokens that the function call represents, primarily because with JSON mode, you don't actually specify the schema. So sure, like JSON load works, but really, I care a lot more than just the fact that it is JSON, right? I think function calling gives you a tool to specify the fact like, okay, this is a list of objects that I want and each object has a name or an age and I want the age to be above zero and I want to make sure it's parsed correctly. That's where kind of function calling really shines.
Alessio [00:12:30]: Any thoughts on single versus parallel function calling? So I did a presentation at our AI in Action Discord channel, and obviously showcase instructor. One of the big things that we have before with single function calling is like when you're trying to extract lists, you have to make these funky like properties that are lists to then actually return all the objects. How do you see the hack being put on the developer's plate versus like more of this stuff just getting better in the model? And I know you tweeted recently about Anthropic, for example, you know, some lists are not lists or strings and there's like all of these discrepancies.
Jason [00:13:04]: I almost would prefer it if it was always a single function call. Obviously, there is like the agents workflows that, you know, Instructor doesn't really support that well, but are things that, you know, ought to be done, right? Like you could define, I think maybe like 50 or 60 different functions in a single API call. And, you know, if it was like get the weather or turn the lights on or do something else, it makes a lot of sense to have these parallel function calls. But in terms of an extraction workflow, I definitely think it's probably more helpful to have everything be a single schema, right? Just because you can sort of specify relationships between these entities that you can't do in a parallel function calling, you can have a single chain of thought before you generate a list of results. Like there's like small like API differences, right? Where if it's for parallel function calling, if you do one, like again, really, I really care about how the SDK looks and says, okay, do I always return a list of functions or do you just want to have the actual object back out and you want to have like auto complete over that object? Interesting.
Alessio [00:14:00]: What's kind of the cap for like how many function definitions you can put in where it still works well? Do you have any sense on that?
Jason [00:14:07]: I mean, for the most part, I haven't really had a need to do anything that's more than six or seven different functions. I think in the documentation, they support way more. I don't even know if there's any good evals that have over like two dozen function calls. I think if you're running into issues where you have like 20 or 50 or 60 function calls, I think you're much better having those specifications saved in a vector database and then have them be retrieved, right? So if there are 30 tools, like you should basically be like ranking them and then using the top K to do selection a little bit better rather than just like shoving like 60 functions into a single. Yeah.
Swyx [00:14:40]: Yeah. Well, I mean, so I think this is relevant now because previously I think context limits prevented you from having more than a dozen tools anyway. And now that we have million token context windows, you know, a cloud recently with their new function calling release said they can handle over 250 tools, which is insane to me. That's, that's a lot. You're saying like, you know, you don't think there's many people doing that. I think anyone with a sort of agent like platform where you have a bunch of connectors, they wouldn't run into that problem. Probably you're right that they should use a vector database and kind of rag their tools. I know Zapier has like a few thousand, like 8,000, 9,000 connectors that, you know, obviously don't fit anywhere. So yeah, I mean, I think that would be it unless you need some kind of intelligence that chains things together, which is, I think what Alessio is coming back to, right? Like there's this trend about parallel function calling. I don't know what I think about that. Anthropic's version was, I think they use multiple tools in sequence, but they're not in parallel. I haven't explored this at all. I'm just like throwing this open to you as to like, what do you think about all these new things? Yeah.
Jason [00:15:40]: It's like, you know, do we assume that all function calls could happen in any order? In which case, like we either can assume that, or we can assume that like things need to happen in some kind of sequence as a DAG, right? But if it's a DAG, really that's just like one JSON object that is the entire DAG rather than going like, okay, the order of the function that return don't matter. That's definitely just not true in practice, right? Like if I have a thing that's like turn the lights on, like unplug the power, and then like turn the toaster on or something like the order doesn't matter. And it's unclear how well you can describe the importance of that reasoning to a language model yet. I mean, I'm sure you can do it with like good enough prompting, but I just haven't any use cases where the function sequence really matters. Yeah.
Alessio [00:16:18]: To me, the most interesting thing is the models are better at picking than your ranking is usually. Like I'm incubating a company around system integration. For example, with one system, there are like 780 endpoints. And if you're actually trying to do vector similarity, it's not that good because the people that wrote the specs didn't have in mind making them like semantically apart. You know, they're kind of like, oh, create this, create this, create this. Versus when you give it to a model, like in Opus, you put them all, it's quite good at picking which ones you should actually run. And I'm curious to see if the model providers actually care about some of those workflows or if the agent companies are actually going to build very good rankers to kind of fill that gap.
Jason [00:16:58]: Yeah. My money is on the rankers because you can do those so easily, right? You could just say, well, given the embeddings of my search query and the embeddings of the description, I can just train XGBoost and just make sure that I have very high like MRR, which is like mean reciprocal rank. And so the only objective is to make sure that the tools you use are in the top end filtered. Like that feels super straightforward and you don't have to actually figure out how to fine tune a language model to do tool selection anymore. Yeah. I definitely think that's the case because for the most part, I imagine you either have like less than three tools or more than a thousand. I don't know what kind of company said, oh, thank God we only have like 185 tools and this works perfectly, right? That's right.
Alessio [00:17:39]: And before we maybe move on just from this, it was interesting to me, you retweeted this thing about Anthropic function calling and it was Joshua Brown's retweeting some benchmark that it's like, oh my God, Anthropic function calling so good. And then you retweeted it and then you tweeted it later and it's like, it's actually not that good. What's your flow? How do you actually test these things? Because obviously the benchmarks are lying, right? Because the benchmarks say it's good and you said it's bad and I trust you more than the benchmark. How do you think about that? And then how do you evolve it over time?
Jason [00:18:09]: It's mostly just client data. I actually have been mostly busy with enough client work that I haven't been able to reproduce public benchmarks. And so I can't even share some of the results in Anthropic. I would just say like in production, we have some pretty interesting schemas where it's like iteratively building lists where we're doing like updates of lists, like we're doing in place updates. So like upserts and inserts. And in those situations we're like, oh yeah, we have a bunch of different parsing errors. Numbers are being returned to strings. We were expecting lists of objects, but we're getting strings that are like the strings of JSON, right? So we had to call JSON parse on individual elements. Overall, I'm like super happy with the Anthropic models compared to the OpenAI models. Sonnet is very cost effective. Haiku is in function calling, it's actually better, but I think they just had to sort of file down the edges a little bit where like our tests pass, but then we actually deployed a production. We got half a percent of traffic having issues where if you ask for JSON, it'll try to talk to you. Or if you use function calling, you know, we'll have like a parse error. And so I think that definitely gonna be things that are fixed in like the upcoming weeks. But in terms of like the reasoning capabilities, man, it's hard to beat like 70% cost reduction, especially when you're building consumer applications, right? If you're building something for consultants or private equity, like you're charging $400, it doesn't really matter if it's a dollar or $2. But for consumer apps, it makes products viable. If you can go from four to Sonnet, you might actually be able to price it better. Yeah.
Swyx [00:19:31]: I had this chart about the ELO versus the cost of all the models. And you could put trend graphs on each of those things about like, you know, higher ELO equals higher cost, except for Haiku. Haiku kind of just broke the lines, or the ISO ELOs, if you want to call it. Cool. Before we go too far into your opinions on just the overall ecosystem, I want to make sure that we map out the surface area of Instructor. I would say that most people would be familiar with Instructor from your talks and your tweets and all that. You had the number one talk from the AI Engineer Summit.
Jason [00:20:03]: Two Liu. Jason Liu and Jerry Liu. Yeah.
Swyx [00:20:06]: Yeah. Until I actually went through your cookbook, I didn't realize the surface area. How would you categorize the use cases? You have LLM self-critique, you have knowledge graphs in here, you have PII data sanitation. How do you characterize to people what is the surface area of Instructor? Yeah.
Jason [00:20:23]: This is the part that feels crazy because really the difference is LLMs give you strings and Instructor gives you data structures. And once you get data structures, again, you can do every lead code problem you ever thought of. Right. And so I think there's a couple of really common applications. The first one obviously is extracting structured data. This is just be, okay, well, like I want to put in an image of a receipt. I want to give it back out a list of checkout items with a price and a fee and a coupon code or whatever. That's one application. Another application really is around extracting graphs out. So one of the things we found out about these language models is that not only can you define nodes, it's really good at figuring out what are nodes and what are edges. And so we have a bunch of examples where, you know, not only do I extract that, you know, this happens after that, but also like, okay, these two are dependencies of another task. And you can do, you know, extracting complex entities that have relationships. Given a story, for example, you could extract relationships of families across different characters. This can all be done by defining a graph. The last really big application really is just around query understanding. The idea is that like any API call has some schema and if you can define that schema ahead of time, you can use a language model to resolve a request into a much more complex request. One that an embedding could not do. So for example, I have a really popular post called like rag is more than embeddings. And effectively, you know, if I have a question like this, what was the latest thing that happened this week? That embeds to nothing, right? But really like that query should just be like select all data where the date time is between today and today minus seven days, right? What if I said, how did my writing change between this month and last month? Again, embeddings would do nothing. But really, if you could do like a group by over the month and a summarize, then you could again like do something much more interesting. And so this really just calls out the fact that embeddings really is kind of like the lowest hanging fruit. And using something like instructor can really help produce a data structure. And then you can just use your computer science and reason about the data structure. Maybe you say, okay, well, I'm going to produce a graph where I want to group by each month and then summarize them jointly. You can do that if you know how to define this data structure. Yeah.
Swyx [00:22:29]: So you kind of run up against like the LangChains of the world that used to have that. They still do have like the self querying, I think they used to call it when we had Harrison on in our episode. How do you see yourself interacting with the other LLM frameworks in the ecosystem? Yeah.
Jason [00:22:42]: I mean, if they use instructor, I think that's totally cool. Again, it's like, it's just Python, right? It's like asking like, oh, how does like Django interact with requests? Well, you just might make a request.get in a Django app, right? But no one would say, I like went off of Django because I'm using requests now. They should be ideally like sort of the wrong comparison in terms of especially like the agent workflows. I think the real goal for me is to go down like the LLM compiler route, which is instead of doing like a react type reasoning loop. I think my belief is that we should be using like workflows. If we do this, then we always have a request and a complete workflow. We can fine tune a model that has a better workflow. Whereas it's hard to think about like, how do you fine tune a better react loop? Yeah. You always train it to have less looping, in which case like you wanted to get the right answer the first time, in which case it was a workflow to begin with, right?
Swyx [00:23:31]: Can you define workflow? Because I used to work at a workflow company, but I'm not sure this is a good term for everybody.
Jason [00:23:36]: I'm thinking workflow in terms of like the prefect Zapier workflow. Like I want to build a DAG, I want you to tell me what the nodes and edges are. And then maybe the edges are also put in with AI. But the idea is that like, I want to be able to present you the entire plan and then ask you to fix things as I execute it, rather than going like, hey, I couldn't parse the JSON, so I'm going to try again. I couldn't parse the JSON, I'm going to try again. And then next thing you know, you spent like $2 on opening AI credits, right? Yeah. Whereas with the plan, you can just say, oh, the edge between node like X and Y does not run. Let me just iteratively try to fix that, fix the one that sticks, go on to the next component. And obviously you can get into a world where if you have enough examples of the nodes X and Y, maybe you can use like a vector database to find a good few shot examples. You can do a lot if you sort of break down the problem into that workflow and executing that workflow, rather than looping and hoping the reasoning is good enough to generate the correct output. Yeah.
Swyx [00:24:35]: You know, I've been hammering on Devon a lot. I got access a couple of weeks ago. And obviously for simple tasks, it does well. For the complicated, like more than 10, 20 hour tasks, I can see- That's a crazy comparison.
Jason [00:24:47]: We used to talk about like three, four loops. Only once it gets to like hour tasks, it's hard.
Swyx [00:24:54]: Yeah. Less than an hour, there's nothing.
Jason [00:24:57]: That's crazy.
Swyx [00:24:58]: I mean, okay. Maybe my goalposts have shifted. I don't know. That's incredible.
Jason [00:25:02]: Yeah. No, no. I'm like sub one minute executions. Like the fact that you're talking about 10 hours is incredible.
Swyx [00:25:08]: I think it's a spectrum. I think I'm going to say this every single time I bring up Devon. Let's not reward them for taking longer to do things. Do you know what I mean? I think that's a metric that is easily abusable.
Jason [00:25:18]: Sure. Yeah. You know what I mean? But I think if you can monotonically increase the success probability over an hour, that's winning to me. Right? Like obviously if you run an hour and you've made no progress. Like I think when we were in like auto GBT land, there was that one example where it's like, I wanted it to like buy me a bicycle overnight. I spent $7 on credit and I never found the bicycle. Yeah.
Swyx [00:25:41]: Yeah. Right. I wonder if you'll be able to purchase a bicycle. Because it actually can do things in real world. It just needs to suspend to you for off and stuff. The point I was trying to make was that I can see it turning plans. I think one of the agents loopholes or one of the things that is a real barrier for agents is LLMs really like to get stuck into a lane. And you know what you're talking about, what I've seen Devon do is it gets stuck in a lane and it will just kind of change plans based on the performance of the plan itself. And it's kind of cool.
Jason [00:26:05]: I feel like we've gone too much in the looping route and I think a lot of more plans and like DAGs and data structures are probably going to come back to help fill in some holes. Yeah.
Alessio [00:26:14]: What do you think of the interface to that? Do you see it's like an existing state machine kind of thing that connects to the LLMs, the traditional DAG players? Do you think we need something new for like AI DAGs?
Jason [00:26:25]: Yeah. I mean, I think that the hard part is going to be describing visually the fact that this DAG can also change over time and it should still be allowed to be fuzzy. I think in like mathematics, we have like plate diagrams and like Markov chain diagrams and like recurrent states and all that. Some of that might come into this workflow world. But to be honest, I'm not too sure. I think right now, the first steps are just how do we take this DAG idea and break it down to modular components that we can like prompt better, have few shot examples for and ultimately like fine tune against. But in terms of even the UI, it's hard to say what it will likely win. I think, you know, people like Prefect and Zapier have a pretty good shot at doing a good job.
Swyx [00:27:03]: Yeah. You seem to use Prefect a lot. I actually worked at a Prefect competitor at Temporal and I'm also very familiar with Dagster. What else would you call out as like particularly interesting in the AI engineering stack?
Jason [00:27:13]: Man, I almost use nothing. I just use Cursor and like PyTests. Okay. I think that's basically it. You know, a lot of the observability companies have... The more observability companies I've tried, the more I just use Postgres.
Swyx [00:27:29]: Really? Okay. Postgres for observability?
Jason [00:27:32]: But the issue really is the fact that these observability companies isn't actually doing observability for the system. It's just doing the LLM thing. Like I still end up using like Datadog or like, you know, Sentry to do like latency. And so I just have those systems handle it. And then the like prompt in, prompt out, latency, token costs. I just put that in like a Postgres table now.
Swyx [00:27:51]: So you don't need like 20 funded startups building LLM ops? Yeah.
Jason [00:27:55]: But I'm also like an old, tired guy. You know what I mean? Like I think because of my background, it's like, yeah, like the Python stuff, I'll write myself. But you know, I will also just use Vercel happily. Yeah. Yeah. So I'm not really into that world of tooling, whereas I think, you know, I spent three good years building observability tools for recommendation systems. And I was like, oh, compared to that, Instructor is just one call. I just have to put time star, time and then count the prompt token, right? Because I'm not doing a very complex looping behavior. I'm doing mostly workflows and extraction. Yeah.
Swyx [00:28:26]: I mean, while we're on this topic, we'll just kind of get this out of the way. You famously have decided to not be a venture backed company. You want to do the consulting route. The obvious route for someone as successful as Instructor is like, oh, here's hosted Instructor with all tooling. Yeah. You just said you had a whole bunch of experience building observability tooling. You have the perfect background to do this and you're not.
Jason [00:28:43]: Yeah. Isn't that sick? I think that's sick.
Swyx [00:28:44]: I mean, I know why, because you want to go free dive.
Jason [00:28:47]: Yeah. Yeah. Because I think there's two things. Right. Well, one, if I tell myself I want to build requests, requests is not a venture backed startup. Right. I mean, one could argue whether or not Postman is, but I think for the most part, it's like having worked so much, I'm more interested in looking at how systems are being applied and just having access to the most interesting data. And I think I can do that more through a consulting business where I can come in and go, oh, you want to build perfect memory. You want to build an agent. You want to build like automations over construction or like insurance and supply chain, or like you want to handle writing private equity, mergers and acquisitions reports based off of user interviews. Those things are super fun. Whereas like maintaining the library, I think is mostly just kind of like a utility that I try to keep up, especially because if it's not venture backed, I have no reason to sort of go down the route of like trying to get a thousand integrations. In my mind, I just go like, okay, 98% of the people use open AI. I'll support that. And if someone contributes another platform, that's great. I'll merge it in. Yeah.
Swyx [00:29:45]: I mean, you only added Anthropic support this year. Yeah.
Jason [00:29:47]: Yeah. You couldn't even get an API key until like this year, right? That's true. Okay. If I add it like last year, I was trying to like double the code base to service, you know, half a percent of all downloads.
Swyx [00:29:58]: Do you think the market share will shift a lot now that Anthropic has like a very, very competitive offering?
Jason [00:30:02]: I think it's still hard to get API access. I don't know if it's fully GA now, if it's GA, if you can get a commercial access really easily.
Alessio [00:30:12]: I got commercial after like two weeks to reach out to their sales team.
Jason [00:30:14]: Okay.
Alessio [00:30:15]: Yeah.
Swyx [00:30:16]: Two weeks. It's not too bad. There's a call list here. And then anytime you run into rate limits, just like ping one of the Anthropic staff members.
Jason [00:30:21]: Yeah. Then maybe we need to like cut that part out. So I don't need to like, you know, spread false news.
Swyx [00:30:25]: No, it's cool. It's cool.
Jason [00:30:26]: But it's a common question. Yeah. Surely just from the price perspective, it's going to make a lot of sense. Like if you are a business, you should totally consider like Sonnet, right? Like the cost savings is just going to justify it if you actually are doing things at volume. And yeah, I think the SDK is like pretty good. Back to the instructor thing. I just don't think it's a billion dollar company. And I think if I raise money, the first question is going to be like, how are you going to get a billion dollar company? And I would just go like, man, like if I make a million dollars as a consultant, I'm super happy. I'm like more than ecstatic. I can have like a small staff of like three people. It's fun. And I think a lot of my happiest founder friends are those who like raised a tiny seed round, became profitable. They're making like 70, 60, 70, like MRR, 70,000 MRR and they're like, we don't even need to raise the seed round. Let's just keep it like between me and my co-founder, we'll go traveling and it'll be a great time. I think it's a lot of fun.
Alessio [00:31:15]: Yeah. like say LLMs / AI and they build some open source stuff and it's like I should just raise money and do this and I tell people a lot it's like look you can make a lot more money doing something else than doing a startup like most people that do a company could make a lot more money just working somewhere else than the company itself do you have any advice for folks that are maybe in a similar situation they're trying to decide oh should I stay in my like high paid FAANG job and just tweet this on the side and do this on github should I go be a consultant like being a consultant seems like a lot of work so you got to talk to all these people you know there's a lot to unpack
Jason [00:31:54]: I think the open source thing is just like well I'm just doing it purely for fun and I'm doing it because I think I'm right but part of being right is the fact that it's not a venture backed startup like I think I'm right because this is all you need right so I think a part of the philosophy is the fact that all you need is a very sharp blade to sort of do your work and you don't actually need to build like a big enterprise so that's one thing I think the other thing too that I've kind of been thinking around just because I have a lot of friends at google that want to leave right now it's like man like what we lack is not money or skill like what we lack is courage you should like you just have to do this a hard thing and you have to do it scared anyways right in terms of like whether or not you do want to do a founder I think that's just a matter of optionality but I definitely recognize that the like expected value of being a founder is still quite low it is right I know as many founder breakups and as I know friends who raised a seed round this year right like that is like the reality and like you know even in from that perspective it's been tough where it's like oh man like a lot of incubators want you to have co-founders now you spend half the time like fundraising and then trying to like meet co-founders and find co-founders rather than building the thing this is a lot of time spent out doing uh things I'm not really good at. I do think there's a rising trend in solo founding yeah.
Swyx [00:33:06]: You know I am a solo I think that something like 30 percent of like I forget what the exact status something like 30 percent of starters that make it to like series B or something actually are solo founder I feel like this must have co-founder idea mostly comes from YC and most everyone else copies it and then plenty of companies break up over co-founder
Jason [00:33:27]: Yeah and I bet it would be like I wonder how much of it is the people who don't have that much like and I hope this is not a diss to anybody but it's like you sort of you go through the incubator route because you don't have like the social equity you would need is just sort of like send an email to Sequoia and be like hey I'm going on this ride you want a ticket on the rocket ship right like that's very hard to sell my message if I was to raise money is like you've seen my twitter my life is sick I've decided to make it much worse by being a founder because this is something I have to do so do you want to come along otherwise I want to fund it myself like if I can't say that like I don't need the money because I can like handle payroll and like hire an intern and get an assistant like that's all fine but I really don't want to go back to meta I want to like get two years to like try to find a problem we're solving that feels like a bad time
Alessio [00:34:12]: Yeah Jason is like I wear a YSL jacket on stage at AI Engineer Summit I don't need your accelerator money
Jason [00:34:18]: And boots, you don't forget the boots. But I think that is a part of it right I think it is just like optionality and also just like I'm a lot older now I think 22 year old Jason would have been probably too scared and now I'm like too wise but I think it's a matter of like oh if you raise money you have to have a plan of spending it and I'm just not that creative with spending that much money yeah I mean to be clear you just celebrated your 30th birthday happy birthday yeah it's awesome so next week a lot older is relative to some some of the folks I think seeing on the career tips
Alessio [00:34:48]: I think Swix had a great post about are you too old to get into AI I saw one of your tweets in January 23 you applied to like Figma, Notion, Cohere, Anthropic and all of them rejected you because you didn't have enough LLM experience I think at that time it would be easy for a lot of people to say oh I kind of missed the boat you know I'm too late not gonna make it you know any advice for people that feel like that
Jason [00:35:14]: Like the biggest learning here is actually from a lot of folks in jiu-jitsu they're like oh man like is it too late to start jiu-jitsu like I'll join jiu-jitsu once I get in more shape right it's like there's a lot of like excuses and then you say oh like why should I start now I'll be like 45 by the time I'm any good and say well you'll be 45 anyways like time is passing like if you don't start now you start tomorrow you're just like one more day behind if you're worried about being behind like today is like the soonest you can start right and so you got to recognize that like maybe you just don't want it and that's fine too like if you wanted you would have started I think a lot of these people again probably think of things on a too short time horizon but again you know you're gonna be old anyways you may as well just start now you know
Swyx [00:35:55]: One more thing on I guess the um career advice slash sort of vlogging you always go viral for this post that you wrote on advice to young people and the lies you tell yourself oh yeah yeah you said you were writing it for your sister.
Jason [00:36:05]: She was like bummed out about going to college and like stressing about jobs and I was like oh and I really want to hear okay and I just kind of like text-to-sweep the whole thing it's crazy it's got like 50,000 views like I'm mind I mean your average tweet has more but that thing is like a 30-minute read now
Swyx [00:36:26]: So there's lots of stuff here which I agree with I you know I'm also of occasionally indulge in the sort of life reflection phase there's the how to be lucky there's the how to have high agency I feel like the agency thing is always a trend in sf or just in tech circles how do you define having high agency
Jason [00:36:42]: I'm almost like past the high agency phase now now my biggest concern is like okay the agency is just like the norm of the vector what also matters is the direction right it's like how pure is the shot yeah I mean I think agency is just a matter of like having courage and doing the thing that's scary right you know if people want to go rock climbing it's like do you decide you want to go rock climbing then you show up to the gym you rent some shoes and you just fall 40 times or do you go like oh like I'm actually more intelligent let me go research the kind of shoes that I want okay like there's flatter shoes and more inclined shoes like which one should I get okay let me go order the shoes on Amazon I'll come back in three days like oh it's a little bit too tight maybe it's too aggressive I'm only a beginner let me go change no I think the higher agent person just like goes and like falls down 20 times right yeah I think the higher agency person is more focused on like process metrics versus outcome metrics right like from pottery like one thing I learned was if you want to be good at pottery you shouldn't count like the number of cups or bowls you make you should just weigh the amount of clay you use right like the successful person says oh I went through 100 pounds of clay right the less agency was like oh I've made six cups and then after I made six cups like there's not really what are you what do you do next no just pounds of clay pounds of clay same with the work here right so you just got to write the tweets like make the commits contribute open source like write the documentation there's no real outcome it's just a process and if you love that process you just get really good at the thing you're doing
Swyx [00:38:04]: yeah so just to push back on this because obviously I mostly agree how would you design performance review systems because you were effectively saying we can count lines of code for developers right
Jason [00:38:15]: I don't think that would be the actual like I think if you make that an outcome like I can just expand a for loop right I think okay so for performance review this is interesting because I've mostly thought of it from the perspective of science and not engineering I've been running a lot of engineering stand-ups primarily because there's not really that many machine learning folks the process outcome is like experiments and ideas right like if you think about outcome is what you might want to think about an outcome is oh I want to improve the revenue or whatnot but that's really hard but if you're someone who is going out like okay like this week I want to come up with like three or four experiments I might move the needle okay nothing worked to them they might think oh nothing worked like I suck but to me it's like wow you've closed off all these other possible avenues for like research like you're gonna get to the place that you're gonna figure out that direction really soon there's no way you try 30 different things and none of them work usually like 10 of them work five of them work really well two of them work really really well and one thing was like the nail in the head so agency lets you sort of capture the volume of experiments and like experience lets you figure out like oh that other half it's not worth doing right I think experience is going like half these prompting papers don't make any sense just use chain of thought and just you know use a for loop that's basically right it's like usually performance for me is around like how many experiments are you running how oftentimes are you trying.
Alessio [00:39:32]: When do you give up on an experiment because a StitchFix you kind of give up on language models I guess in a way as a tool to use and then maybe the tools got better you were right at the time and then the tool improved I think there are similar paths in my engineering career where I try one approach and at the time it doesn't work and then the thing changes but then I kind of soured on that approach and I don't go back to it soon
Jason [00:39:51]: I see yeah how do you think about that loop so usually when I'm coaching folks and as they say like oh these things don't work I'm not going to pursue them in the future like one of the big things like hey the negative result is a result and this is something worth documenting like this is an academia like if it's negative you don't just like not publish right but then like what do you actually write down like what you should write down is like here are the conditions this is the inputs and the outputs we tried the experiment on and then one thing that's really valuable is basically writing down under what conditions would I revisit these experiments these things don't work because of what we had at the time if someone is reading this two years from now under what conditions will we try again that's really hard but again that's like another skill you kind of learn right it's like you do go back and you do experiments you figure out why it works now I think a lot of it here is just like scaling worked yeah rap lyrics you know that was because I did not have high enough quality data if we phase shift and say okay you don't even need training data oh great then it might just work a different domain
Alessio [00:40:48]: Do you have anything in your list that is like it doesn't work now but I want to try it again later? Something that people should maybe keep in mind you know people always like agi when you know when are you going to know the agi is here maybe it's less than that but any stuff that you tried recently that didn't work that
Jason [00:41:01]: You think will get there I mean I think the personal assistance and the writing I've shown to myself it's just not good enough yet so I hired a writer and I hired a personal assistant so now I'm gonna basically like work with these people until I figure out like what I can actually like automate and what are like the reproducible steps but like I think the experiment for me is like I'm gonna go pay a person like thousand dollars a month that helped me improve my life and then let me get them to help me figure like what are the components and how do I actually modularize something to get it to work because it's not just like a lot gmail calendar and like notion it's a little bit more complicated than that but we just don't know what that is yet those are two sort of systems that I wish gb4 or opus was actually good enough to just write me an essay but most of the essays are still pretty bad
Swyx [00:41:44]: yeah I would say you know on the personal assistance side Lindy is probably the one I've seen the most flow was at a speaker at the summit I don't know if you've checked it out or any other sort of agents assistant startup
Jason [00:41:54]: Not recently I haven't tried lindy they were not ga last time I was considering it yeah yeah a lot of it now it's like oh like really what I want you to do is take a look at all of my meetings and like write like a really good weekly summary email for my clients to remind them that I'm like you know thinking of them and like working for them right or it's like I want you to notice that like my monday is like way too packed and like block out more time and also like email the people to do the reschedule and then try to opt in to move them around and then I want you to say oh jason should have like a 15 minute prep break after form back to back those are things that now I know I can prompt them in but can it do it well like before I didn't even know that's what I wanted to prompt for us defragging a calendar and adding break so I can like eat lunch yeah that's the AGI test yeah exactly compassion right I think one thing that yeah we didn't touch on it before but
Alessio [00:42:44]: I think was interesting you had this tweet a while ago about prompts should be code and then there were a lot of companies trying to build prompt engineering tooling kind of trying to turn the prompt into a more structured thing what's your thought today now you want to turn the thinking into DAGs like do prompts should still be code any updated ideas
Jason [00:43:04]: It's the same thing right I think you know with Instructor it is very much like the output model is defined as a code object that code object is sent to the LLM and in return you get a data structure so the outputs of these models I think should also be code objects and the inputs somewhat should be code objects but I think the one thing that instructor tries to do is separate instruction data and the types of the output and beyond that I really just think that most of it should be still like managed pretty closely to the developer like so much of is changing that if you give control of these systems away too early you end up ultimately wanting them back like many companies I know that I reach out or ones were like oh we're going off of the frameworks because now that we know what the business outcomes we're trying to optimize for these frameworks don't work yeah because we do rag but we want to do rag to like sell you supplements or to have you like schedule the fitness appointment the prompts are kind of too baked into the systems to really pull them back out and like start doing upselling or something it's really funny but a lot of it ends up being like once you understand the business outcomes you care way more about the prompt
Swyx [00:44:07]: Actually this is fun in our prep for this call we were trying to say like what can you as an independent person say that maybe me and Alessio cannot say or me you know someone at a company say what do you think is the market share of the frameworks the LangChain, the LlamaIndex, the everything...
Jason [00:44:20]: Oh massive because not everyone wants to care about the code yeah right I think that's a different question to like what is the business model and are they going to be like massively profitable businesses right making hundreds of millions of dollars that feels like so straightforward right because not everyone is a prompt engineer like there's so much productivity to be captured in like back office optim automations right it's not because they care about the prompts that they care about managing these things yeah but those would be sort of low code experiences you yeah I think the bigger challenge is like okay hundred million dollars probably pretty easy it's just time and effort and they have the manpower and the money to sort of solve those problems again if you go the vc route then it's like you're talking about billions and that's really the goal that stuff for me it's like pretty unclear but again that is to say that like I sort of am building things for developers who want to use infrastructure to build their own tooling in terms of the amount of developers there are in the world versus downstream consumers of these things or even just think of how many companies will use like the adobes and the ibms right because they want something that's fully managed and they want something that they know will work and if the incremental 10% requires you to hire another team of 20 people you might not want to do it and I think that kind of organization is really good for uh those are bigger companies
Swyx [00:45:32]: I just want to capture your thoughts on one more thing which is you said you wanted most of the prompts to stay close to the developer and Hamel Husain wrote this post which I really love called f you show me the prompt yeah I think he cites you in one of those part of the blog post and I think ds pi is kind of like the complete antithesis of that which is I think it's interesting because I also hold the strong view that AI is a better prompt engineer than you are and I don't know how to square that wondering if you have thoughts
Jason [00:45:58]: I think something like DSPy can work because there are like very short-term metrics to measure success right it is like did you find the pii or like did you write the multi-hop question the correct way but in these workflows that I've been managing a lot of it are we minimizing churn and maximizing retention yeah that's a very long loop it's not really like a uptuna like training loop right like those things are much more harder to capture so we don't actually have those metrics for that right and obviously we can figure out like okay is the summary good but like how do you measure the quality of the summary it's like that feedback loop it ends up being a lot longer and then again when something changes it's really hard to make sure that it works across these like newer models or again like changes to work for the current process like when we migrate from like anthropic to open ai like there's just a ton of change that are like infrastructure related not necessarily around the prompt itself yeah cool any other ai engineering startups that you think should not exist before we wrap up i mean oh my gosh i mean a lot of it again it's just like every time of investors like how does this make a billion dollars like it doesn't i'm gonna go back to just like tweeting and holding my breath underwater yeah like i don't really pay attention too much to most of this like most of the stuff i'm doing is around like the consumer of like llm calls yep i think people just want to move really fast and they will end up pick these vendors but i don't really know if anything has really like blown me out the water like i only trust myself but that's also a function of just being an old man like i think you know many companies are definitely very happy with using most of these tools anyways but i definitely think i occupy a very small space in the engineering ecosystem.
Swyx [00:47:41]: Yeah i would say one of the challenges here you know you call about the dealing in the consumer of llm's space i think that's what ai engineering differs from ml engineering and i think a constant disconnect or cognitive dissonance in this field in the ai engineers that have sprung up is that they are not as good as the ml engineers they are not as qualified i think that you know you are someone who has credibility in the mle space and you are also a very authoritative figure in the ai space and i think so and you know i think you've built the de facto leading library i think yours i think instructors should be part of the standard lib even though i try to not use it like i basically also end up rebuilding instructor right like that's a lot of the back and forth that we had over the past two days i think that's the fundamental thing that we're trying to figure out like there's very small supply of MLEs not everyone's going to have that experience that you had but the global demand for AI is going to far outstrip the existing MLEs.
Jason [00:48:36]: So what do we do do we force everyone to go through the standard MLE curriculum or do we make a new one? I've got some takes go i think a lot of these app layer startups should not be hiring MLEs because they end up churning yeah they want to work at opening high they're just like hey guys i joined and you have no data and like all i did this week was take some typescript build errors and like figure out why we don't have any tests and like what is this framework x and y like how do you measure success what are your business outcomes oh no okay let's not focus on that great i'll focus on these typescript build errors and then you're just like what am i doing and then you kind of sort of feel really frustrated and i already recognize that because i've made offers to machine learning engineers they've joined and they've left in like two months and the response is like yeah i think i'm gonna join a research lab so i think it's not even that like i don't even think you should be hiring these mles on the other hand what i also see a lot of is the really motivated engineer that's doing more engineering is not being allowed to actually like fully pursue the ai engineering so they're the guy who built the demo it got traction now it's working but they're still being pulled back to figure out why google calendar integrations are not working or like how to make sure that you know the button is loading on the page and so i'm sort of like in a very interesting position where the companies want to hire an ml they don't need to hire but they won't let the excited people who've caught the ai engineering bug could go do that work more full-time this is something i'm literally wrestling with this week as i just wrote something about it this is one of the things i'm probably going to be recommending in the future is really thinking about like where is the talent coming from how much of it is internal and do you really need to hire someone who's like writing pytorch code yeah exactly most of the time you're not you're gonna need someone to write instructor code and like i feel goofy all the time just like prompting it's like oh man like i wish i just had a target data set that i could like train a model against yes and i can just say it's right or wrong yeah.
Swyx [00:50:32]: You know i guess what Latent Space is, what the AI Engineer world's fair is is that we're trying to create and elevate this industry of ai engineers where it's legitimate to actually take these motivated software engineers who want to build more in ai and do creative things in ai to actually say you have the blessing like and this is legitimate sub-specialty of software engineering
Jason [00:50:50]: Yeah i think there's been a mix of that product engineering i think a lot more data science is going to come in versus machine learning engineering because a lot of it now is just quantifying like what does the business actually want as an outcome the outcome is not rag app yeah the outcome is like reduced churn people need to figure out what that actually is and how to measure it yeah all the data engineering tools still apply
Swyx [00:51:09]: bi layers semantic layers whatever yeah cool we'll have you back again for the world's fair we don't know what you're going to talk about but i'm sure it's going to be amazing you're a very polished speaker
Jason [00:51:19]: The title is written it's just uh Pydantic is still all you need
Swyx [00:51:26]: I'm worried about having too many all you need titles because that's obviously very trendy so yeah you have one of them but i need to keep a lid on like you know everyone's saying their
Jason [00:51:34]: thing is all you need but yeah we'll figure it out i think it's not my thing it's someone else
Swyx [00:51:38]: i think that's why it works it's true cool well it's a real pleasure to have you on of course everyone should go follow you on twitter and check out instructor there's also instructor js which i'm very happy to see.

Share this post