



LLM Gateway: The One Decision That Removes 100 AI Engineering Decisions
One of the simplest and high ROI decisions in AI Engineering
Sponsorships and the Agents Engineering track for AIE Summit NYC are sold out. Speakers and schedule is up. Last calls for AI Leadership track for CTOs/VP’s of AI!
Dear AI Engineer,
We get it. You want to keep things simple. At first you built your GPT wrapper with the openai SDK/API, then shipped it, got a million users. Awesome!
Model Routing…
Then Claude Sonnet ships with incredible coding ability and vibes. DeepSeek comes along with incredibly cheap reasoning. Amazon Nova comes out 1000x cheaper than GPT4. Gemini 2 launches with the highest intelligence-for-cost ratio in the world. Their APIs don’t quite match.
Okay, no problem, keep it simple. Cursor is the fastest growing SaaS in the history of SaaS, with a few prompts you’ve got an abstract ModelProvider interface that unifies all the things, if you just add the right environment variables.

Look familiar? Or maybe not, you’re smarter than this, you use LangChain or LlamaIndex or Pydantic AI and they’ve done it for you! Just pip install and RTFM.
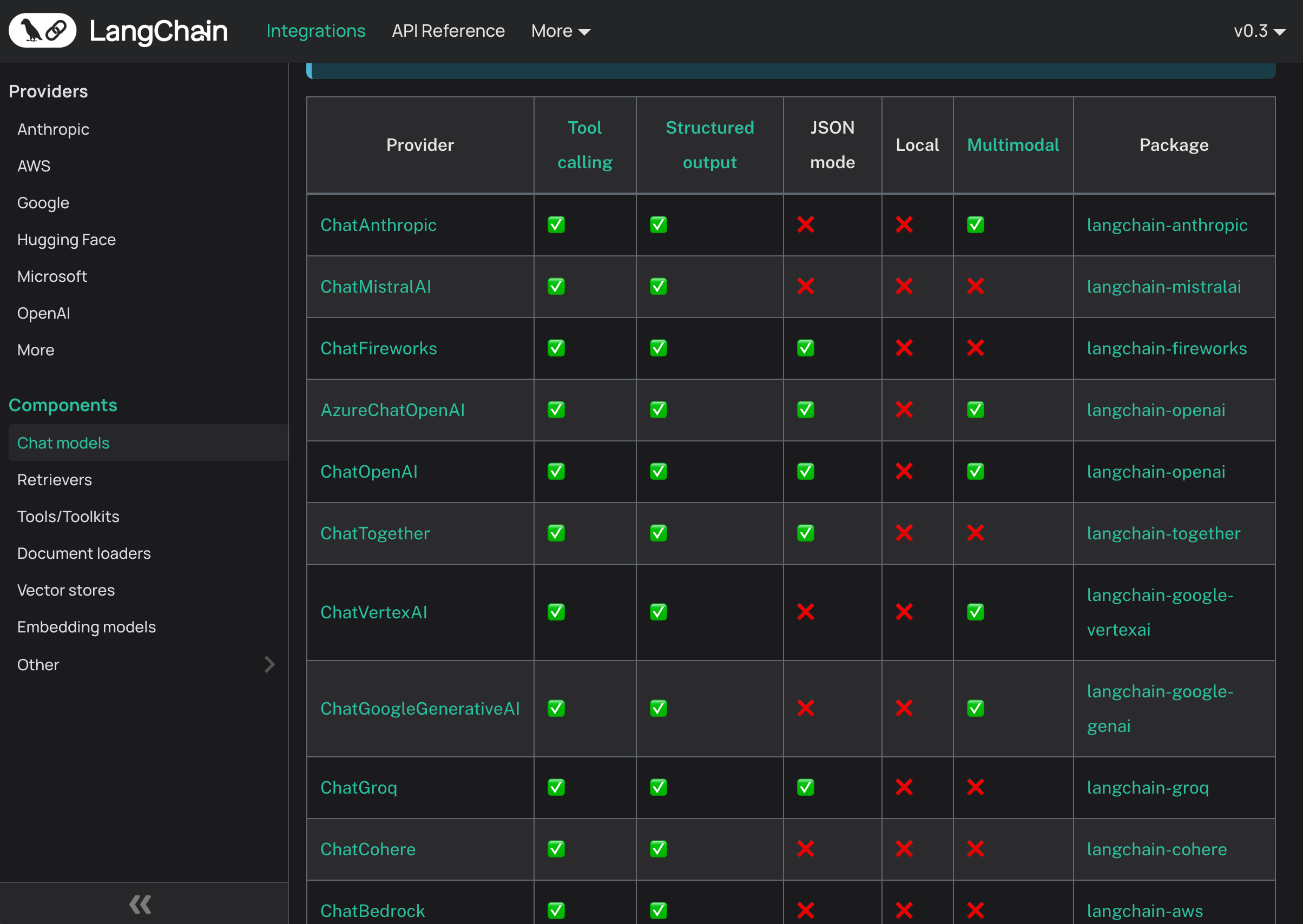
Of course, you have to learn their specific abstractions, and they don’t support everything you want, but that’s okay, it’s open source, better than nothing, keep it simple.
… and Observability…
Then you wanted to add some logging. Just to track down bugs and p99 latency, understand your user behavior, get a handle on costs, any number of reasons. No problem, you kept it simple. You already use Datadog, Mixpanel, Honeycomb et al. OpenTelemetry already added Semantic Conventions for GenAI. Log a few events, you’re good. Maybe use “AI native” players like HumanLoop, LangSmith, or Braintrust:
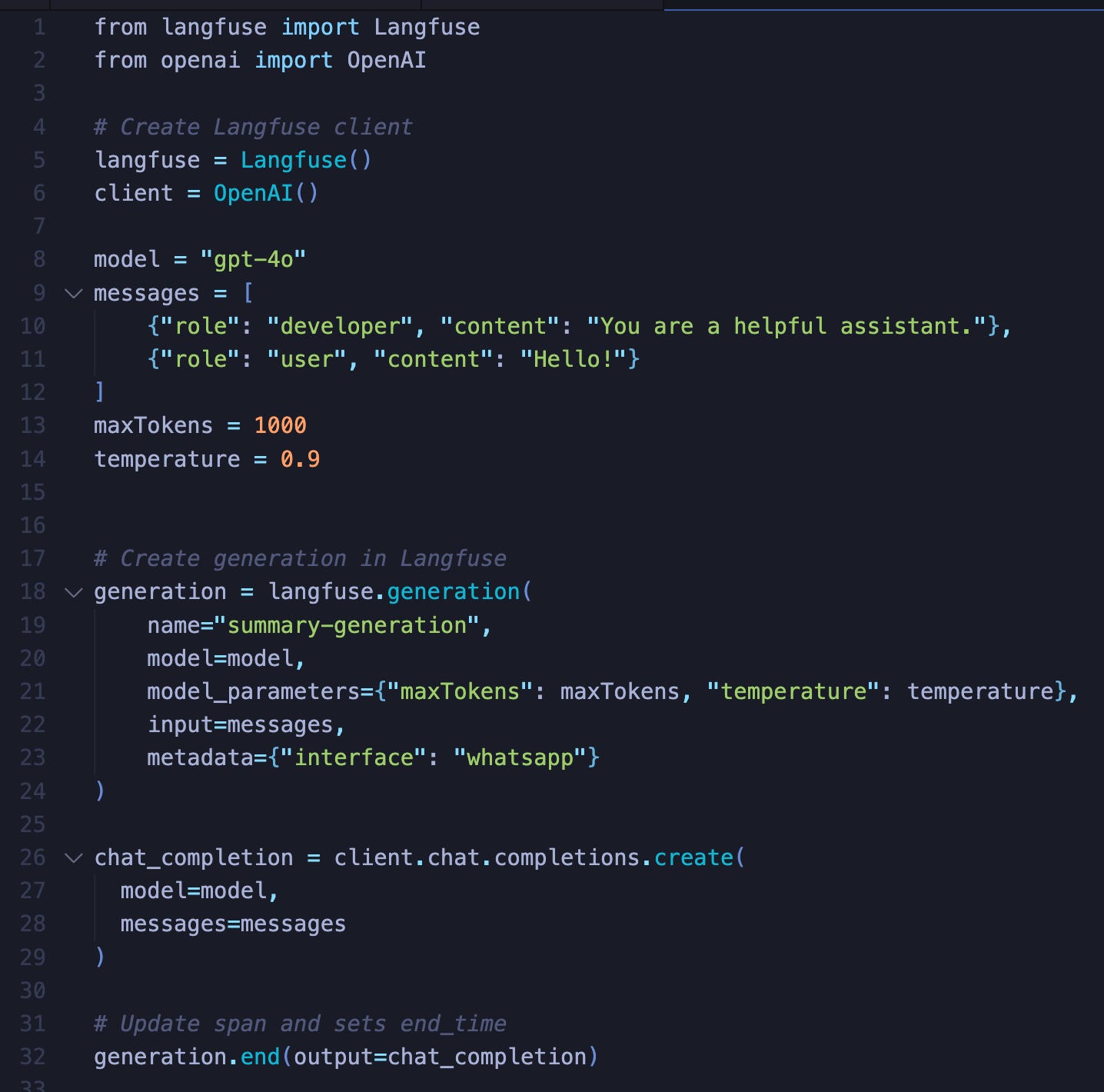
That’s at least a 7 LOC overhead on every single LLM call. This is a problem as old as observability with a standard library of solutions: Decorator approaches can sweep it under the rug, or you can monkey patch the SDK, and auto-instrumentation approaches exist.
At scale, the invoices for logging everything start being real. It’s a lot of money to pay for a wall of data that just sits there with nobody looking at it. Maybe you add a little if random.random() < sample_rate: in there. I hope you remembered to figure out how to log with retries and agent loops and tool calls and streaming and pair with human feedback and anomaly detection and…
… and Guardrails…
Speaking of retries: Everyone knows that AI Engineering involves building reliable systems atop non-deterministic LLMs. This is both simpler and bigger than Safety and Security, though those are important: There’s Guardrails AI and NeMo-Guardrails for the general problem, but even JSON/structured output needs Instructor (and we have found that naively-retried structured output can often outperform constrained-decoding structured output like the ones supported by OpenAI1).
We’re not just talking about removing PII or checking for embarrassing content, but also plain simple validations on output quality - for an auto-titler module I have had models generate three titles in one string when I just wanted one, or for formatted markdown output summary generation I’ve had models duplicate my desired **bolding** to cause ****unnecessary bolding****.
Sure, keep it simple, write some regex, or use a library.
… and 100 other simple decisions…
When working on a team of N people using M models, you have a few options:
Share M keys with the whole team, losing all control of who uses what and requiring everyone to change keys
Create N x M keys to send to everyone, causing an administrative hassle/nightmare when either N or M change
before we can even consider multiple environments (dev/staging/prod)
There’s a long tail of little problems, each of which are simple to do on their own…
prompt management and playground
human feedback tracking
eval execution
anomaly monitoring/mitigation
access control
… but all together it is madness to reinvent the same 100 wheels that everyone has in every app and every framework.
Short Term Simplicity, Long Term Complexity
I haven’t been very subtle about where we’re going here. I think all these decisions can be solved at origin by adopting the obvious software bundle that has emerged: The LLM Gateway, which we mentioned in the Humanloop writeup and developed in the Braintrust writeup:
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.