


We have a full slate of upcoming events: AI Engineer London, AWS Re:Invent in Las Vegas, and now Latent Space LIVE! at NeurIPS in Vancouver and online. Sign up to join and speak!
We are still taking questions for our next big recap episode! Submit questions and messages on Speakpipe here for a chance to appear on the show!
We try to stay close to the inference providers as part of our coverage, as our podcasts with Together AI and Replicate will attest:
Cloud Intelligence at the speed of 5000 tok/s - with Ce Zhang and Vipul Ved Prakash of Together AI

Our first ever demo day aimed for 15-20 people and ended up ballooning to >200 and covered in the news. We are now running the 2024 edition in SF on Feb 23: Latent Space Final Frontiers, a startup and research competition in “The Autonomous Workforce”, ”Beyond Transformers & GPUs”, and “Embodied AI”.
A Brief History of the Open Source AI Hacker - with Ben Firshman of Replicate

This Friday we’re doing a special crossover event in SF with Dylan Patel of SemiAnalysis (previous guest!), and we will do a live podcast on site. RSVP here.
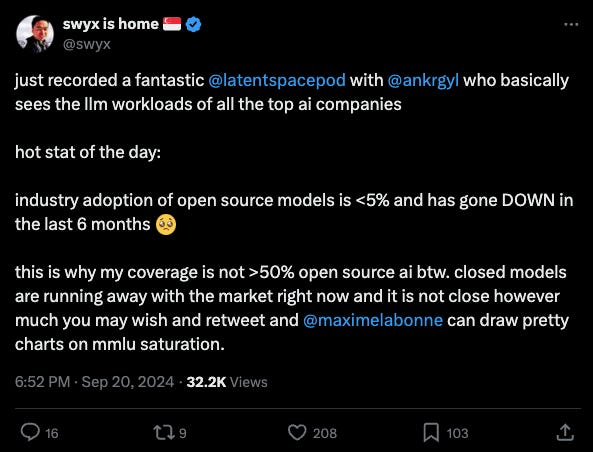
However one of the most notable pull quotes from our very well received Braintrust episode was his opinion that open source model adoption has NOT gone very well and is actually declining in relative market share terms (it is of course increasing in absolute terms):
Today’s guest, Lin Qiao, would wholly disagree. Her team of Pytorch/GPU experts are wholly dedicated toward helping you serve and finetune the full stack of open source models from Meta and others, across all modalities (Text, Audio, Image, Embedding, Vision-understanding), helping customers like Cursor and Hubspot scale up open source model inference both rapidly and affordably.
Fireworks has emerged after its successive funding rounds with top tier VCs as one of the leaders of the Compound AI movement, a term first coined by the Databricks/Mosaic gang at Berkeley AI and adapted as “Composite AI” by Gartner:

Replicating o1
We are the first podcast to discuss Fireworks’ f1, their proprietary replication of OpenAI’s o1. This has become a surprisingly hot area of competition in the past week as both Nous Forge and Deepseek r1 have launched competitive models.

Full Video Podcast
Timestamps
00:00:00 Introductions
00:02:08 Pre-history of Fireworks and PyTorch at Meta
00:09:49 Product Strategy: From Framework to Model Library
00:13:01 Compound AI Concept and Industry Dynamics
00:20:07 Fireworks' Distributed Inference Engine
00:22:58 OSS Model Support and Competitive Strategy
00:29:46 Declarative System Approach in AI
00:31:00 Can OSS replicate o1?
00:36:51 Fireworks f1
00:41:03 Collaboration with Cursor and Speculative Decoding
00:46:44 Fireworks quantization (and drama around it)
00:49:38 Pricing Strategy
00:51:51 Underrated Features of Fireworks Platform
00:55:17 Hiring
Transcript
Alessio [00:00:00]: Hey everyone, welcome to the Latent Space Podcast. This is Alessio, partner at CTO at Danceable Partners, and I'm joined by my co-host, Swyx founder, Osmalayar.
Swyx [00:00:11]: Hey, and today we're in a very special studio inside the Fireworks office with Lin Qiang, CEO of Fireworks. Welcome. Yeah.
Lin [00:00:20]: Oh, you should welcome us.
Swyx [00:00:21]: Yeah, welcome. Yeah, thanks for having us. It's unusual to be in the home of a startup, but it's also, I think our relationship is a bit unusual compared to all our normal guests. Definitely.
Lin [00:00:34]: Yeah. I'm super excited to talk about very interesting topics in that space with both of you.
Swyx [00:00:41]: You just celebrated your two-year anniversary yesterday.
Lin [00:00:43]: Yeah, it's quite a crazy journey. We circle around and share all the crazy stories across these two years, and it has been super fun. All the way from we experienced Silicon Valley bank run to we delete some data that shouldn't be deleted operationally. We went through a massive scale where we actually are busy getting capacity to, yeah, we learned to kind of work with it as a team with a lot of brilliant people across different places to join a company. It has really been a fun journey.
Alessio [00:01:24]: When you started, did you think the technical stuff will be harder or the bank run and then the people side? I think there's a lot of amazing researchers that want to do companies and it's like the hardest thing is going to be building the product and then you have all these different other things. So, were you surprised by what has been your experience the most?
Lin [00:01:42]: Yeah, to be honest with you, my focus has always been on the product side and then after the product goes to market. And I didn't realize the rest has been so complicated, operating a company and so on. But because I don't think about it, I just kind of manage it. So it's done. I think I just somehow don't think about it too much and solve whatever problem coming our way and it worked.
Swyx [00:02:08]: So let's, I guess, let's start at the pre-history, the initial history of Fireworks. You ran the PyTorch team at Meta for a number of years and we previously had Sumit Chintal on and I think we were just all very interested in the history of GenEI. Maybe not that many people know how deeply involved Faire and Meta were prior to the current GenEI revolution.
Lin [00:02:35]: My background is deep in distributed system, database management system. And I joined Meta from the data side and I saw this tremendous amount of data growth, which cost a lot of money and we're analyzing what's going on. And it's clear that AI is driving all this data generation. So it's a very interesting time because when I joined Meta, Meta is going through ramping down mobile-first, finishing the mobile-first transition and then starting AI-first. And there's a fundamental reason about that sequence because mobile-first gave a full range of user engagement that has never existed before. And all this user engagement generated a lot of data and this data power AI. So then the whole entire industry is also going through, falling through this same transition. When I see, oh, okay, this AI is powering all this data generation and look at where's our AI stack. There's no software, there's no hardware, there's no people, there's no team. I want to dive up there and help this movement. So when I started, it's very interesting industry landscape. There are a lot of AI frameworks. It's a kind of proliferation of AI frameworks happening in the industry. But all the AI frameworks focus on production and they use a very certain way of defining the graph of neural network and then use that to drive the model iteration and productionization. And PyTorch is completely different. So they could also assume that he was the user of his product. And he basically says, researchers face so much pain using existing AI frameworks, this is really hard to use and I'm going to do something different for myself. And that's the origin story of PyTorch. PyTorch actually started as the framework for researchers. They don't care about production at all. And as they grow in terms of adoption, so the interesting part of AI is research is the top of our normal production. There are so many researchers across academic, across industry, they innovate and they put their results out there in open source and that power the downstream productionization. So it's brilliant for MATA to establish PyTorch as a strategy to drive massive adoption in open source because MATA internally is a PyTorch shop. So it creates a flying wheel effect. So that's kind of a strategy behind PyTorch. But when I took on PyTorch, it's kind of at Caspo, MATA established PyTorch as the framework for both research and production. So no one has done that before. And we have to kind of rethink how to architect PyTorch so we can really sustain production workload, the stability, reliability, low latency, all this production concern was never a concern before. Now it's a concern. And we actually have to adjust its design and make it work for both sides. And that took us five years because MATA has so many AI use cases, all the way from ranking recommendation as powering the business top line or as ranking newsfeed, video ranking to site integrity detect bad content automatically using AI to all kinds of effects, translation, image classification, object detection, all this. And also across AI running on the server side, on mobile phones, on AI VR devices, the wide spectrum. So by the time we actually basically managed to support AI across ubiquitous everywhere across MATA. But interestingly, through open source engagement, we work with a lot of companies. It is clear to us like this industry is starting to take on AI first transition. And of course, MATA's hyperscale always go ahead of industry. And it feels like when we start this AI journey at MATA, there's no software, no hardware, no team. For many companies we engage with through PyTorch, we feel the pain. That's the genesis why we feel like, hey, if we create fireworks and support industry going through this transition, it will be a huge amount of impact. Of course, the problem that the industry is facing will not be the same as MATA. MATA is so big, right? So it's kind of skewed towards extreme scale and extreme optimization in the industry will be different. But we feel like we have the technical chop and we've seen a lot. We'll look to kind of drive that. So yeah, so that's how we started.
Swyx [00:06:58]: When you and I chatted about the origins of fireworks, it was originally envisioned more as a PyTorch platform, and then later became much more focused on generative AI. Is that fair to say? What was the customer discovery here?
Lin [00:07:13]: Right. So I would say our initial blueprint is we should build a PyTorch cloud because a PyTorch library and there's no SaaS platform to enable AI workloads.
Swyx [00:07:26]: Even in 2022, it's interesting.
Lin [00:07:28]: I would not say absolutely no, but cloud providers have some of those, but it's not first class citizen, right? At 2022, there's still like TensorFlow is massively in production. And this is all pre-gen AI, and PyTorch is kind of getting more and more adoption. But there's no PyTorch-first SaaS platform existing. At the same time, we are also a very pragmatic set of people. We really want to make sure from the get-go, we get really, really close to customers. We understand their use case, we understand their pain points, we understand the value we deliver to them. So we want to take a different approach instead of building a horizontal PyTorch cloud. We want to build a verticalized platform first. And then we talk with many customers. And interestingly, we started the company in September 2022, and in October, November, the OpenAI announced ChatGPT. And then boom, when we talked with many customers, they were like, can you help us work on the JNS aspect? So of course, there are some open source models. It's not as good at that time, but people are already putting a lot of attention there. Then we decided that if we're going to pick a vertical, we're going to pick JNI. The other reason is all JNI models are PyTorch models. So that's another reason. We believe that because of the nature of JNI, it's going to generate a lot of human consumable content. It will drive a lot of consumer, customer-developer-facing application and product innovation. Guaranteed. We're just at the beginning of this. Our prediction is for those kind of applications, the inference is much more important than training because inference scale is proportional to the up-limit award population. And training scale is proportional to the number of researchers. Of course, each training round could be very expensive. Although PyTorch supports both inference and training, we decided to laser focus on inference. So yeah, so that's how we got started. And we launched our public platform August last year. When we launched, it was a single product. It's a distributed inference engine with a simple API, open AI compatible API with many models. We started with LM and then we added a lot of models. Fast forward to now, we are a full platform with multiple product lines. So we love to kind of dive deep into what we offer. But that's a very fun journey in the past two years.
Alessio [00:09:49]: What was the transition from you start to focus on PyTorch and people want to understand the framework, get it live. And now say maybe most people that use you don't even really know much about PyTorch at all. You know, they're just trying to consume a model. From a product perspective, like what were some of the decisions early on? Like right in October, November, you were just like, hey, most people just care about the model, not about the framework. We're going to make it super easy or was it more a gradual transition to the model library
Swyx [00:10:16]: you have today?
Lin [00:10:17]: Yeah. So our product decision is all based on who is our ICP. And one thing I want to acknowledge here is the generic technology is disruptive. It's very different from AI before GNI. So it's a clear leap forward. Because before GNI, the companies that want to invest in AI, they have to train from scratch. There's no other way. There's no foundation model. It doesn't exist. So that means then to start a team, first hire a team who is capable of crunch data. There's a lot of data to crunch, right? Because training from scratch, you have to prepare a lot of data. And then they need to have GPUs to train, and then you start to manage GPUs. So then it becomes a very complex project. It takes a long time and not many companies can afford it, actually. And the GNI is a very different game right now, because it is a foundation model. So you don't have to train anymore. That makes AI much more accessible as a technology. As an app developer or product manager, even, not a developer, they can interact with GNI models directly. So our goal is to make AI accessible to all app developers and product engineers. That's our goal. So then getting them into the building model doesn't make any sense anymore with this new technology. And then building easy, accessible APIs is the most important. Early on, when we got started, we decided we're going to be open AI compatible. It's just kind of very easy for developers to adopt this new technology, and we will manage the underlying complexity of serving all these models.
Swyx [00:11:56]: Yeah, open AI has become the standard. Even as we're recording today, Gemini announced that they have open AI compatible APIs. Interesting. So we just need to drop it all in line, and then we have everyone popping in line.
Lin [00:12:09]: That's interesting, because we are working very closely with Meta as one of the partners. Meta, of course, is kind of very generous to donate many very, very strong open source models, expecting more to come. But also they have announced LamaStack, which is basically standardized, the upper level stack built on top of Lama models. So they don't just want to give out models and you figure out what the upper stack is. They instead want to build a community around the stack and build a new standard. I think there's an interesting dynamics in play in the industry right now, when it's more standardized across open AI, because they are kind of creating the top of the funnel, or standardized across Lama, because this is the most used open source model. So I think it's a lot of fun working at this time.
Swyx [00:13:01]: I've been a little bit more doubtful on LamaStack, I think you've been more positive. Basically it's just like the meta version of whatever Hugging Face offers, you know, or TensorRT, or BLM, or whatever the open source opportunity is. But to me, it's not clear that just because Meta open sources Lama, that the rest of LamaStack will be adopted. And it's not clear why I should adopt it. So I don't know if you agree.
Lin [00:13:27]: It's very early right now. That's why I kind of work very closely with them and give them feedback. The feedback to the meta team is very important. So then they can use that to continue to improve the model and also improve the higher level I think the success of LamaStack heavily depends on the community adoption. And there's no way around it. And I know the meta team would like to kind of work with a broader set of community. But it's very early.
Swyx [00:13:52]: One thing that after your Series B, so you raced for Benchmark, and then Sequoia. I remember being close to you for at least your Series B announcements, you started betting heavily on this term of Compound AI. It's not a term that we've covered very much in the podcast, but I think it's definitely getting a lot of adoption from Databricks and Berkeley people and all that. What's your take on Compound AI? Why is it resonating with people?
Lin [00:14:16]: Right. So let me give a little bit of context why we even consider that space.
Swyx [00:14:22]: Because like pre-Series B, there was no message, and now it's like on your landing page.
Lin [00:14:27]: So it's kind of very organic evolution from when we first launched our public platform, we are a single product. We are a distributed inference engine, where we do a lot of innovation, customized KUDA kernels, raw kernel kernels, running on different kinds of hardware, and build distributed disaggregated execution, inference execution, build all kinds of caching. So that is one. So that's kind of one product line, is the fast, most cost-efficient inference platform. Because we wrote PyTorch code, we know we basically have a special PyTorch build for that, together with a custom kernel we wrote. And then we worked with many more customers, we realized, oh, the distributed inference engine, our design is one size fits all. We want to have this inference endpoint, then everyone come in, and no matter what kind of form and shape or workload they have, it will just work for them. So that's great. But the reality is, we realized all customers have different kinds of use cases. The use cases come in all different forms and shapes. And the end result is the data distribution in their inference workload doesn't align with the data distribution in the training data for the model. It's a given, actually. If you think about it, because researchers have to guesstimate what is important, what's not important in preparing data for training. So because of that misalignment, then we leave a lot of quality, latency, cost improvement on the table. So then we're saying, OK, we want to heavily invest in a customization engine. And we actually announced it called FHIR Optimizer. So FHIR Optimizer basically helps users navigate a three-dimensional optimization space across quality, latency, and cost. So it's a three-dimensional curve. And even for one company, for different use cases, they want to land in different spots. So we automate that process for our customers. It's very simple. You have your inference workload. You inject into the optimizer along with the objective function. And then we spit out inference deployment config and the model setup. So it's your customized setup. So that is a completely different product. So that product thinking is one size fits all. And now on top of that, we provide a huge variety of state-of-the-art models, hundreds of them, varying from text to large state-of-the-art English models. That's where we started. And as we talk with many customers, we realize, oh, audio and text are very, very close. Many of our customers start to build assistants, all kinds of assistants using text. And they immediately want to add audio, audio in, audio out. So we support transcription, translation, speech synthesis, text, audio alignment, all different kinds of audio features. It's a big announcement. You should have heard by the time this is out. And the other areas of vision and text are very close with each other. Because a lot of information doesn't live in plain text. A lot of information lives in multimedia format, images, PDFs, screenshots, and many other different formats. So oftentimes to solve a problem, we need to put the vision model first to extract information and then use language model to process and then send out results. So vision is important. We also support vision model, various different kinds of vision models specialized in processing different kinds of source and extraction. And we're also going to have another announcement of a new API endpoint we'll support for people to upload various different kinds of multimedia content and then get the extract very accurate information out and feed that into LM. And of course, we support embedding because embedding is very important for semantic search, for RAG, and all this. And in addition to that, we also support text-to-image, image generation models, text-to-image, image-to-image, and we're adding text-to-video as well in our portfolio. So it's a very comprehensive set of model catalog that built on top of File Optimizer and Distributed Inference Engine. But then we talk with more customers, they solve business use case, and then we realize one model is not sufficient to solve their problem. And it's very clear because one is the model hallucinates. Many customers, when they onboard this JNI journey, they thought this is magical. JNI is going to solve all my problems magically. But then they realize, oh, this model hallucinates. It hallucinates because it's not deterministic, it's probabilistic. So it's designed to always give you an answer, but based on probabilities, so it hallucinates. And that's actually sometimes a feature for creative writing, for example. Sometimes it's a bug because, hey, you don't want to give misinformation. And different models also have different specialties. To solve a problem, you want to ask different special models to kind of decompose your task into multiple small tasks, narrow tasks, and then have an expert model solve that task really well. And of course, the model doesn't have all the information. It has limited knowledge because the training data is finite, not infinite. So the model oftentimes doesn't have real-time information. It doesn't know any proprietary information within the enterprise. It's clear that in order to really build a compiling application on top of JNI, we need a compound AI system. Compound AI system basically is going to have multiple models across modalities, along with APIs, whether it's public APIs, internal proprietary APIs, storage systems, database systems, knowledge to work together to deliver the best answer.
Swyx [00:20:07]: Are you going to offer a vector database?
Lin [00:20:09]: We actually heavily partner with several big vector database providers. Which is your favorite? They are all great in different ways. But it's public information, like MongoDB is our investor. And we have been working closely with them for a while.
Alessio [00:20:26]: When you say distributed inference engine, what do you mean exactly? Because when I hear your explanation, it's almost like you're centralizing a lot of the decisions through the Fireworks platform on the quality and whatnot. What do you mean distributed? It's like you have GPUs in a lot of different clusters, so you're sharding the inference across the same model.
Lin [00:20:45]: So first of all, we run across multiple GPUs. But the way we distribute across multiple GPUs is unique. We don't distribute the whole model monolithically across multiple GPUs. We chop them into pieces and scale them completely differently based on what's the bottleneck. We also are distributed across regions. We have been running in North America, EMEA, and Asia. We have regional affinity to applications because latency is extremely important. We are also doing global load balancing because a lot of applications there, they quickly scale to global population. And then at that scale, different content wakes up at a different time. And you want to kind of load balancing across. So all the way, and we also have, we manage various different kinds of hardware skew from different hardware vendors. And different hardware design is best for different types of workload, whether it's long context, short context, long generation. So all these different types of workload is best fitted for different kinds of hardware skew. And then we can even distribute across different hardware for a workload. So the distribution actually is all around in the full stack.
Swyx [00:22:02]: At some point, we'll show on the YouTube, the image that Ray, I think, has been working on with all the different modalities that you offer. To me, it's basically you offer the open source version of everything that OpenAI typically offers. I don't think there is. Actually, if you do text to video, you will be a superset of what OpenAI offers because they don't have Sora. Is that Mochi, by the way? Mochi. Mochi, right?
Lin [00:22:27]: Mochi. And there are a few others. I will say, the interesting thing is, I think we're betting on the open source community is going to proliferate. This is literally what we're seeing. And there's amazing video generation companies. There is amazing audio companies. Like cross-border, the innovation is off the chart, and we are building on top of that. I think that's the advantage we have compared with a closed source company.
Swyx [00:22:58]: I think I want to restate the value proposition of Fireworks for people who are comparing you versus a raw GPU provider like a RunPod or Lambda or anything like those, which is like you create the developer experience layer and you also make it easily scalable or serverless or as an endpoint. And then, I think for some models, you have custom kernels, but not all models.
Lin [00:23:25]: Almost for all models. For all large language models, all your models, and the VRMs. Almost for all models we serve.
Swyx [00:23:35]: And so that is called Fire Attention. I don't remember the speed numbers, but apparently much better than VLM, especially on a concurrency basis.
Lin [00:23:44]: So Fire Attention is specific mostly for language models, but for other modalities, we'll also have a customized kernel.
Swyx [00:23:51]: And I think the typical challenge for people is understanding that has value, and then there are other people who are also offering open-source models. Your mode is your ability to offer a good experience for all these customers. But if your existence is entirely reliant on people releasing nice open-source models, other people can also do the same thing.
Lin [00:24:14]: So I would say we build on top of open-source model foundation. So that's the kind of foundation we build on top of. But we look at the value prop from the lens of application developers and product engineers. So they want to create new UX. So what's happening in the industry right now is people are thinking about a completely new way of designing products. And I'm talking to so many founders, it's just mind-blowing. They help me understand existing way of doing PowerPoint, existing way of coding, existing way of managing customer service. It's actually putting a box in our head. For example, PowerPoint. So PowerPoint generation is we always need to think about how to fit into my storytelling into this format of slide one after another. And I'm going to juggle through design together with what story to tell. But the most important thing is what's our storytelling lines, right? And why don't we create a space that is not limited to any format? And those kind of new product UX design combined with automated content generation through Gen AI is the new thing that many founders are doing. What are the challenges they're facing? Let's go from there. One is, again, because a lot of products built on top of Gen AI, they are consumer-personal developer facing, and they require interactive experience. It's just a kind of product experience we all get used to. And our desire is to actually get faster and faster interaction. Otherwise, nobody wants to spend time, right? And then that requires low latency. And the other thing is the nature of consumer-personal developer facing is your audience is very big. You want to scale up to product market fit quickly. But if you lose money at a small scale, you're going to bankrupt quickly. So it's actually a big contrast. I actually have product market fit, but when I scale, I scale out of my business. So that's kind of a very funny way to think about it. So then having low latency and low cost is essential for those new applications and products to survive and really become a generation company. So that's the design point for our distributed inference engine and the file optimizer. File optimizer, you can think about that as a feedback loop. The more you feed your inference workload to our inference engine, the more we help you improve quality, lower latency further, lower your cost. It basically becomes better. And we automate that because we don't want you as an app developer or product engineer to think about how to figure out all these low-level details. It's impossible because you're not trained to do that at all. You should kind of keep your focus on the product innovation. And then the compound AI, we actually feel a lot of pain as the app developers, engineers, there are so many models. Every week, there's at least a new model coming out.
Swyx [00:27:09]: Tencent had a giant model this week. Yeah, yeah.
Lin [00:27:13]: I saw that. I saw that.
Swyx [00:27:15]: It's like $500 billion.
Lin [00:27:18]: So they're like, should I keep chasing this or should I forget about it? And which model should I pick to solve what kind of sub-problem? How do I even decompose my problem into those smaller problems and fit the model into it? I have no idea. And then there are two ways to think about this design. I think I talked about that in the past. One is imperative, as in you figure out how to do it. You give developer tools to dictate how to do it. Or you build a declarative system where a developer tells what they want to do, not how. So these are completely two different designs. So the analogy I want to draw is, in the data world, the database management system is a declarative system because people use database, use SQL. SQL is a way you say, what do you want to extract out of a database? What kind of result do you want? But you don't figure out which node is going to, how many nodes you're going to run on top of, how you redefine your disk, which index you use, which project. You don't need to worry about any of those. And database management system will figure out, generate a new best plan, and execute on that. So database is declarative. And it makes it super easy. You just learn SQL, which is learn a semantic meaning of SQL, and you can use it. Imperative side is there are a lot of ETL pipelines. And people design this DAG system with triggers, with actions, and you dictate exactly what to do. And if it fails, then how to recover. So that's an imperative system. We have seen a range of systems in the ecosystem go different ways. I think there's value of both. There's value of both. I don't think one is going to subsume the other. But we are leaning more into the philosophy of the declarative system. Because from the lens of app developer and product engineer, that would be easiest for them to integrate.
Swyx [00:29:07]: I understand that's also why PyTorch won as well, right? This is one of the reasons. Ease of use.
Lin [00:29:14]: Focus on ease of use, and then let the system take on the hard challenges and complexities. So we follow, we extend that thinking into current system design. So another announcement is we will also announce our next declarative system is going to appear as a model that has extremely high quality. And this model is inspired by Owen's announcement for OpenAI. You should see that by the time we announce this or soon.
Alessio [00:29:46]: Trained by you.
Lin [00:29:47]: Yes.
Alessio [00:29:48]: Is this the first model that you trained? It's not the first.
Lin [00:29:52]: We actually have trained a model called FireFunction. It's a function calling model. It's our first step into compound AI system. Because function calling model can dispatch a request into multiple APIs. We have pre-baked set of APIs the model learned. You can also add additional APIs through the configuration to let model dispatch accordingly. So we have a very high quality function calling model that's already released. We have actually three versions. The latest version is very high quality. But now we take a further step that you don't even need to use function calling model. You use our new model we're going to release. It will solve a lot of problems approaching very high OpenAI quality. So I'm very excited about that.
Swyx [00:30:41]: Do you have any benchmarks yet?
Lin [00:30:43]: We have a benchmark. We're going to release it hopefully next week. We just put our model to LMSYS and people are guessing. Is this the next Gemini model or a MADIS model? People are guessing. That's very interesting. We're watching the Reddit discussion right now.
Swyx [00:31:00]: I have to ask more questions about this. When OpenAI released o1, a lot of people asked about whether or not it's a single model or whether it's a chain of models. Noam and basically everyone on the Strawberry team was very insistent that what they did for reinforcement learning, chain of thought, cannot be replicated by a whole bunch of open source model calls. Do you think that that is wrong? Have you done the same amount of work on RL as they have or was it a different direction?
Lin [00:31:29]: I think they take a very specific approach where the caliber of team is very high. So I do think they are the domain expert in doing the things they are doing. I don't think there's only one way to achieve the same goal. We're on the same direction in the sense that the quality scaling law is shifting from training to inference. For that, I fully agree with them. But we're taking a completely different approach to the problem. All of that is because, of course, we didn't train the model from scratch. All of that is because we built on the show of giants. The current model available we have access to is getting better and better. The future trend is the gap between the open source model and the co-source model. It's just going to shrink to the point there's not much difference. And then we're on the same level field. That's why I think our early investment in inference and all the work we do around balancing across quality, latency, and cost pay off because we have accumulated a lot of experience and that empowers us to release this new model that is approaching open-ended quality.
Alessio [00:32:39]: I guess the question is, what do you think the gap to catch up will be? Because I think everybody agrees with open source models eventually will catch up. And I think with 4, then with Lama 3.2, 3.1, 4.5b, we close the gap. And then 0.1 just reopened the gap so much and it's unclear. Obviously, you're saying your model will have...
Swyx [00:32:57]: We're closing that gap.
Alessio [00:32:58]: But you think in the future, it's going to be months?
Lin [00:33:02]: So here's the thing that's happened. There's public benchmark. It is what it is. But in reality, open source models in certain dimensions are already on par or beat closed source models. So for example, in the coding space, open source models are really, really good. And in function calling, file function is also really, really good. So it's all a matter of whether you build one model to solve all the problems and you want to be the best of solving all the problems, or in the open source domain, it's going to specialize. All these different model builders specialize in certain narrow area. And it's logical that they can be really, really good in that very narrow area. And that's our prediction is with specialization, there will be a lot of expert models really, really good and even better than one-size-fits-all closed source models.
Swyx [00:33:55]: I think this is the core debate that I am still not 100% either way on in terms of compound AI versus normal AI. Because you're basically fighting the bitter lesson.
Lin [00:34:09]: Look at the human society, right? We specialize. And you feel really good about someone specializing doing something really well, right? And that's how our way evolved from ancient times. We're all journalists. We do everything. Now we heavily specialize in different domains. So my prediction is in the AI model space, it will happen also. Except for the bitter lesson.
Swyx [00:34:30]: You get short-term gains by having specialists, domain specialists, and then someone just needs to train like a 10x bigger model on 10x more inference, 10x more data, 10x more model perhaps, whatever the current scaling law is. And then it supersedes all the individual models because of some generalized intelligence slash world knowledge. I think that is the core insight of the GPTs, the GPT-123 networks. Right.
Lin [00:34:56]: But the training scaling law is because you have an increasing amount of data to train from. And you can do a lot of compute. So I think on the data side, we're approaching the limit. And the only data to increase that is synthetic generated data. And then there's like what is the secret sauce there, right? Because if you have a very good large model, you can generate very good synthetic data and then continue to improve quality. So that's why I think in OpenAI, they are shifting from the training scaling law into
Swyx [00:35:25]: inference scaling law.
Lin [00:35:25]: And it's the test time and all this. So I definitely believe that's the future direction. And that's where we are really good at, doing inference.
Swyx [00:35:34]: A couple of questions on that. Are you planning to share your reasoning choices?
Lin [00:35:39]: That's a very good question. We are still debating.
Swyx [00:35:43]: Yeah.
Lin [00:35:45]: We're still debating.
Swyx [00:35:46]: I would say, for example, it's interesting that, for example, SweetBench. If you want to be considered for ranking, you have to submit your reasoning choices. And that has actually disqualified some of our past guests. Cosign was doing well on SweetBench, but they didn't want to leak those results. So that's why you don't see O1 preview on SweetBench, because they don't submit their reasoning choices. And obviously, it's IP. But also, if you're going to be more open, then that's one way to be more open. So your model is not going to be open source, right? It's going to be an endpoint that you provide. Okay, cool. And then pricing, also the same as OpenAI, just kind of based on...
Lin [00:36:25]: Yeah, this is... I don't have, actually, information. Everything is going so fast, we haven't even thought about that yet. Yeah, I should be more prepared.
Swyx [00:36:33]: I mean, this is live. You know, it's nice to just talk about it as it goes live. Any other things that you want feedback on or you're thinking through? It's kind of nice to just talk about something when it's not decided yet. About this new model. It's going to be exciting. It's going to generate a lot of buzz. Right.
Lin [00:36:51]: I'm very excited to see how people are going to use this model. So there's already a Reddit discussion about it. And people are asking very deep, mathematical questions. And since the model got it right, surprising. And internally, we're also asking the model to generate what is AGI. And it generates a very complicated DAG thinking process. So we're having a lot of fun testing this internally. But I'm more curious, how will people use it? What kind of application they're going to try and test on it? And that's where we really like to hear feedback from the community. And also feedback to us. What works out well? What doesn't work out well? What works out well, but surprising them? And what kind of thing they think we should improve on? And those kind of feedback will be tremendously helpful.
Swyx [00:37:44]: Yeah. So I've been a production user of Preview and Mini since launch. I would say they're very, very obvious jobs in quality. So much so that they made clods on it. And they made the previous state-of-the-art look bad. It's really that stark, that difference. The number one thing, just feedback or feature requests, is people want control on the budget. Because right now, in 0.1, it kind of decides its own thinking budget. But sometimes you know how hard the problem is. And you want to actually tell the model, spend two minutes on this. Or spend some dollar amount. Maybe it's time you miss dollars. I don't know what the budget is. That makes a lot of sense.
Lin [00:38:27]: So we actually thought about that requirement. And it should be, at some point, we need to support that. Not initially. But that makes a lot of sense.
Swyx [00:38:38]: Okay. So that was a fascinating overview of just the things that you're working on. First of all, I realized that... I don't know if I've ever given you this feedback. But I think you guys are one of the reasons I agreed to advise you. Because I think when you first met me, I was kind of dubious. I was like... Who are you? There's Replicate. There's Together. There's Laptop. There's a whole bunch of other players. You're in very, very competitive fields. Like, why will you win? And the reason I actually changed my mind was I saw you guys shipping. I think your surface area is very big. The team is not that big. No. We're only 40 people. Yeah. And now here you are trying to compete with OpenAI and everyone else. What is the secret?
Lin [00:39:21]: I think the team. The team is the secret.
Swyx [00:39:23]: Oh boy. So there's no thing I can just copy. You just... No.
Lin [00:39:30]: I think we all come from a very aligned culture. Because most of our team came from meta.
Swyx [00:39:38]: Yeah.
Lin [00:39:38]: And many startups. So we really believe in results. One is result. And second is customer. We're very customer obsessed. And we don't want to drive adoption for the sake of adoption. We really want to make sure we understand we are delivering a lot of business values to the customer. And we really value their feedback. So we would wake up midnight and deploy some model for them. Shuffle some capacity for them. And yeah, over the weekend, no brainer.
Swyx [00:40:15]: So yeah.
Lin [00:40:15]: So that's just how we work as a team. And the caliber of the team is really, really high as well. So as plug-in, we're hiring. We're expanding very, very fast. So if we are passionate about working on the most cutting-edge technology in the general space, come talk with us. Yeah.
Swyx [00:40:38]: Let's talk a little bit about that customer journey. I think one of your more famous customers is Cursor. We were the first podcast to have Cursor on. And then obviously since then, they have blown up. Cause and effect are not related. But you guys especially worked on a fast supply model where you were one of the first people to work on speculative decoding in a production setting. Maybe just talk about what was the behind the scenes of working with Cursor?
Lin [00:41:03]: I will say Cursor is a very, very unique team. I think the unique part is the team has very high technical caliber. There's no question about it. But they have decided, although many companies building coding co-pilot, they will say, I'm going to build a whole entire stack because I can. And they are unique in the sense they seek partnership. Not because they cannot. They're fully capable, but they know where to focus. That to me is amazing. And of course, they want to find a bypass partner. So we spent some time working together. They are pushing us very aggressively because for them to deliver high caliber product experience, they need the latency. They need the interactive, but also high quality at the same time. So actually, we expanded our product feature quite a lot as we support Cursor. And they are growing so fast. And we massively scaled quickly across multiple regions. And we developed a pretty high intense inference stack, almost like similar to what we do for Meta. I think that's a very, very interesting engagement. And through that, there's a lot of trust being built. They realize, hey, this is a team they can really partner with. And they can go big with. That comes back to, hey, we're really customer obsessed. And all the engineers working with them, there's just enormous amount of time syncing together with them and discussing. And we're not big on meetings, but we are like stack channel always on. Yeah, so you almost feel like working as one team. So I think that's really highlighted.
Swyx [00:42:38]: Yeah. For those who don't know, so basically Cursor is a VS Code fork. But most of the time, people will be using closed models. Like I actually use a lot of SONET. So you're not involved there, right? It's not like you host SONET or you have any partnership with it. You're involved where Cursor is small, or like their house brand models are concerned, right?
Lin [00:42:58]: I don't know what I can say, but the things they haven't said.
Swyx [00:43:04]: Very obviously, the drop down is 4.0, but in Cursor, right? So I assume that the Cursor side is the Fireworks side. And then the other side, they're calling out the other. Just kind of curious. And then, do you see any more opportunity on the... You know, I think you made a big splash with 1,000 tokens per second. That was because of speculative decoding. Is there more to push there?
Lin [00:43:25]: We push a lot. Actually, when I mentioned Fire Optimizer, right? So as in, we have a unique automation stack that is one size fits one. We actually deployed to Cursor earlier on. Basically optimized for their specific workload. And that's a lot of juice to extract out of there. And we see success in that product. It actually can be widely adopted. So that's why we started a separate product line called Fire Optimizer. So speculative decoding is just one approach. And speculative decoding here is not static. We actually wrote a blog post about it. There's so many different ways to do speculative decoding. You can pair a small model with a large model in the same model family. Or you can have equal pads and so on. There are different trade-offs which approach you take. It really depends on your workload. And then with your workload, we can align the Eagle heads or Medusa heads or a small big model pair much better to extract the best latency reduction. So all of that is part of the Fire Optimizer offering.
Alessio [00:44:23]: I know you mentioned some of the other inference providers. I think the other question that people always have is around benchmarks. So you get different performance on different platforms. How should people think about... People are like, hey, Lama 3.2 is X on MMLU. But maybe using speculative decoding, you go down a different path. Maybe some providers run a quantized model. How should people think about how much they should care about how you're actually running the model? What's the delta between all the magic that you do and what a raw model...
Lin [00:44:57]: Okay, so there are two big development cycles. One is experimentation, where they need fast iteration. They don't want to think about quality, and they just want to experiment with product experience and so on. So that's one. And then it looks good, and they want to post-product market with scaling. And the quality is really important. And latency and all the other things are becoming important. During the experimentation phase, it's just pick a good model. Don't worry about anything else. Make sure you even generate the right solution to your product. And that's the focus. And then post-product market fit, then that's kind of the three-dimensional optimization curve start to kick in across quality, latency, cost, where you should land. And to me, it's purely a product decision. To many products, if you choose a lower quality, but better speed and lower cost, but it doesn't make a difference to the product experience, then you should do it. So that's why I think inference is part of the validation. The validation doesn't stop at offline eval. The validation will go through A-B testing, through inference. And that's where we offer various different configurations for you to test which is the best setting. So this is the traditional product evaluation. So product evaluation should also include your new model versions and different model setup into the consideration.
Swyx [00:46:22]: I want to specifically talk about what happens a few months ago with some of your major competitors. I mean, all of this is public. What is your take on what happens? And maybe you want to set the record straight on how Fireworks does quantization because I think a lot of people may have outdated perceptions or they didn't read the clarification post on your approach to quantization.
Lin [00:46:44]: First of all, it's always a surprise to us that without any notice, we got called out.
Swyx [00:46:51]: Specifically by name, which is normally not what...
Lin [00:46:54]: Yeah, in a public post. And have certain interpretation of our quality. So I was really surprised. And it's not a good way to compete, right? We want to compete fairly. And oftentimes when one vendor gives out results, the interpretation of another vendor is always extremely biased. So we actually refrain ourselves to do any of those. And we happily partner with third parties to do the most fair evaluation. So we're very surprised. And we don't think that's a good way to figure out the competition landscape. So then we react. I think when it comes to quantization, the interpretation, we wrote actually a very thorough blog post. Because again, no one says it's all. We have various different quantization schemes. We can quantize very different parts of the model from ways to activation to cross-TPU communication. They can use different quantization schemes or consistent across the board. And again, it's a trade-off. It's a trade-off across this three-dimensional quality, latency, and cost. And for our customer, we actually let them find the best optimized point. And we have a very thorough evaluation process to pick that point. But for self-serve, there's only one point to pick. There's no customization available. So of course, it depends on what we talk with many customers. We have to pick one point. And I think the end result, like AA published, later on AA published a quality measure. And we actually looked really good. So that's why what I mean is, I will leave the evaluation of quality or performance to third party and work with them to find the most fair benchmark. And I think that's a good approach, a methodology. But I'm not a part of an approach of calling out specific names
Swyx [00:48:55]: and critique other competitors in a very biased way. Databases happens as well. I think you're the more politically correct one. And then Dima is the more... Something like this. It's you on Twitter.
Lin [00:49:11]: It's like the Russian... We partner. We play different roles.
Swyx [00:49:20]: Another one that I wanted to... I'm just the last one on the competition side. There's a perception of price wars in hosting open source models. And we talked about the competitiveness in the market. Do you aim to make margin on open source models? Oh, absolutely, yes.
Lin [00:49:38]: So, but I think it really... When we think about pricing, it's really need to coordinate with the value we're delivering. If the value is limited, or there are a lot of people delivering the same value, there's no differentiation. There's only one way to go. It's going down. So through competition. If I take a big step back, there is pricing from... We're more compared with close model providers, APIs, right? The close model provider, their cost structure is even more interesting because we don't bear any training costs. And we focus on inference optimization, and that's kind of where we continue to add a lot of product value. So that's how we think about product. But for the close source API provider, model provider, they bear a lot of training costs. And they need to amortize the training costs into the inference. So that created very interesting dynamics of, yeah, if we match pricing there, and I think how they are going to make money is very, very interesting.
Swyx [00:50:37]: So for listeners, opening eyes 2024, $4 billion in revenue, $3 billion in compute training, $2 billion in compute inference, $1 billion in research compute amortization, and $700 million in salaries. So that is like...
Swyx [00:50:59]: I mean, a lot of R&D.
Lin [00:51:01]: Yeah, so I think matter is basically like, make it zero. So that's a very, very interesting dynamics we're operating within. But coming back to inference, so we are, again, as I mentioned, our product is, we are a platform. We're not just a single model as a service provider as many other inference providers, like they're providing a single model. We have our optimizer to highly customize towards your inference workload. We have a compound AI system where significantly simplify your interaction to high quality and low latency, low cost. So those are all very different from other providers.
Alessio [00:51:38]: What do people not know about the work that you do? I guess like people are like, okay, Fireworks, you run model very quickly. You have the function model. Is there any kind of like underrated part of Fireworks that more people should try?
Lin [00:51:51]: Yeah, actually, one user post on x.com, he mentioned, oh, actually, Fireworks can allow me to upload the LoRa adapter to the service model at the same cost and use it at same cost. Nobody has provided that. That's because we have a very special, like we rolled out multi-LoRa last year, actually. And we actually have this function for a long time. And many people has been using it, but it's not well known that, oh, if you find your model, you don't need to use on demand. If you find your model is LoRa, you can upload your LoRa adapter and we deploy it as if it's a new model. And then you use, you get your endpoint and you can use that directly, but at the same cost as the base model. So I'm happy that user is marketing it for us. He discovered that feature, but we have that for last year. So I think to feedback to me is, we have a lot of very, very good features, as Sean just mentioned. I'm the advisor to the company,
Swyx [00:52:57]: and I didn't know that you had speculative decoding released.
Lin [00:53:02]: We have prompt catching way back last year also. We have many, yeah. So I think that is one of the underrated feature. And if they're developers, you are using our self-serve platform, please try it out.
Swyx [00:53:16]: The LoRa thing is interesting because I think you also, the reason people add additional costs to it, it's not because they feel like charging people. Normally in normal LoRa serving setups, there is a cost to dedicating, loading those weights and dedicating a machine to that inference. How come you can't avoid it?
Lin [00:53:36]: Yeah, so this is kind of our technique called multi-LoRa. So we basically have many LoRa adapters share the same base model. And basically we significantly reduce the memory footprint of serving. And the one base model can sustain a hundred to a thousand LoRa adapters. And then basically all these different LoRa adapters can share the same, like direct the same traffic to the same base model where base model is dominating the cost. So that's how we advertise that way. And that's how we can manage the tokens per dollar, million token pricing, the same as base model.
Swyx [00:54:13]: Awesome. Is there anything that you think you want to request from the community or you're looking for model-wise or tooling-wise that you think like someone should be working on in this?
Lin [00:54:23]: Yeah, so we really want to get a lot of feedback from the application developers who are starting to build on JNN or on the already adopted or starting about thinking about new use cases and so on to try out Fireworks first. And let us know what works out really well for you and what is your wishlist and what sucks, right? So what is not working out for you and we would like to continue to improve. And for our new product launches, typically we want to launch to a small group of people. Usually we launch on our Discord first to have a set of people use that first. So please join our Discord channel. We have a lot of communication going on there. Again, you can also give us feedback. We'll have a starting office hour for you to directly talk with our DevRel and engineers to exchange more long notes.
Alessio [00:55:17]: And you're hiring across the board?
Lin [00:55:18]: We're hiring across the board. We're hiring front-end engineers, infrastructure cloud, infrastructure engineers, back-end system optimization engineers, applied researchers, like researchers who have done post-training, who have done a lot of fine-tuning and so on.
Swyx [00:55:34]: That's it. Thank you. Thanks for having us.
