



Eigenquestions for the AI Red Wedding
What the next great AI-enabled product will answer

The response to OpenAI’s Whisper this week (useful breakdowns here) have been overwhelming - perhaps not unleashing as much creativity, but notable in that my developer friends were actually trying it out for very pragmatic reasons: to transcribe their podcasts and YouTube channels to save on transcription costs.
This led me to try tackling the holy grail of AI products questions1:
What are the most likely AI products to be successful?
The AI Red Wedding
Before this week, you had to use an opaque API like Amazon Transcribe (2.4 cents/minute), Google Cloud (3.6 cents/minute) and Rev.ai (3.5 cents/minute) (good comparison article here).
Now you can run Whisper on commodity devices (an EC2 t3.medium is 4.2 cents per hour, and there is lots of near free compute for infrequent/async use cases) and customize/further train it to your heart’s content.
With August’s Stable Diffusion, people were speculating that stock image companies would go out of business (why settle for a limited inventory of stock images when you can pluck the exact image for you from the multiverse at ~no cost?).
With September’s OpenAI Whisper, my friends were actively exploring replacing their existing bills for transcription services.
This situation reminded me of an old Byran Cantrill joke about AWS Re:invent:

Every month, a new industry coming under AI fire. If you are working in a sleepy, legacy industry, opening up Hacker News or your social media poison of choice every day comes with a looming sense of doom: When will AI come for me?
Prospective AI product founders and VCs should flip this question: What industries are next to be AI’ed?
Traversing The Idea Maze
Every entrepreneur going top-down (aka not merely “scratching your own itch” and improvising, but genuinely trying to find the global optimal product to create from the start) needs to go through the Idea Maze (cdixon writeup) - having run the business idea through a gauntlet of all the first- and second-order questions that necessarily arise. Jeff Bezos put his maze on the record all the way back in 1997:
Jeff made a list of 20 products to sell online, and out of them he chose books to start with because:
More items in this category than any other - 3m books vs 200k CDs (taking advantage of infinite shelf space online)
Product doesn’t spoil if arrived late (giving himself allowance for primitive logistics, and delays from having asset-light on-demand network for long tail books)
Extremely logical, top down, not scratching his own itch but rather solving for global optimal starting point based on the fact that the Internet was going to be A Thing.
A decade later, Elon Musk also published his idea maze in 2006:
As you know, the initial product of Tesla Motors is a high performance electric sports car called the Tesla Roadster. However, some readers may not be aware of the fact that our long term plan is to build a wide range of models, including affordably priced family cars. This is because the overarching purpose of Tesla Motors (and the reason I am funding the company) is to help expedite the move from a mine-and-burn hydrocarbon economy towards a solar electric economy.
This is another non-obvious result of having the long term vision, and working backward all the way to the first product:
In short, the master plan is:
Build sports car
Use that money to build an affordable car
Use that money to build an even more affordable car
While doing above, also provide zero emission electric power generation options
Both Bezos and Musk did their mazes starting from a basic ground truth about the future (the Internet will consume the world, and humanity will move to a solar electric economy) and worked their way backwards to a non-obvious first product (books, and sports cars) to go to market with.
The generational AI product entrepreneurs may also benefit from going through this kind of exercise. Most founders and VCs vaguely believe AI will transform software and transform most industries, but the exercise of working that backwards to the non-obvious first product is the real billion dollar question.
So here’s my attempt - not an answer, but a framework for arriving at possible answers.
What AI can do
First thing to answer is to take inventory of current capabilities. This is hard because much research doesn’t fit into neat MECE boxes, and we often move the goalposts of what AI is after it becomes “boring” and we come up with a more mundane name for it.
Still, one must try.
My current favorite way to do this is to take the categories from Eugene Yan’s ApplyingML.com list, and then whittle it down from there.
This is my current working taxonomy of AI capabilities:
Small input → Large output: Generative AI (Image, Text, Code)
More examples: https://thisxdoesnotexist.com/
Smart Reply (very constrained text generation)
Inpainting (very constrained image generation)
Large input → Small output: Search/Information Retrieval/Information Extraction, Summarization
Human in the Loop Optimization: Forecasting, Ranking, and Recommendation
Autonomous Optimization: Game playing (including Deep Blue, AlphaGo, Self Driving)
Unstructured input → Structured output: Classification (Clustering, Vision, Spam/Fraud/Abuse/Anomaly Detection), productizable as DocQuery or Snorkel
Specialized transformations
These capabilities seem to have little to do with each other, except that they are largely only made superhuman by training on large quantities of data (the Software 2.0 thesis), and excludes smaller usecases like Learned Bloom Filters.
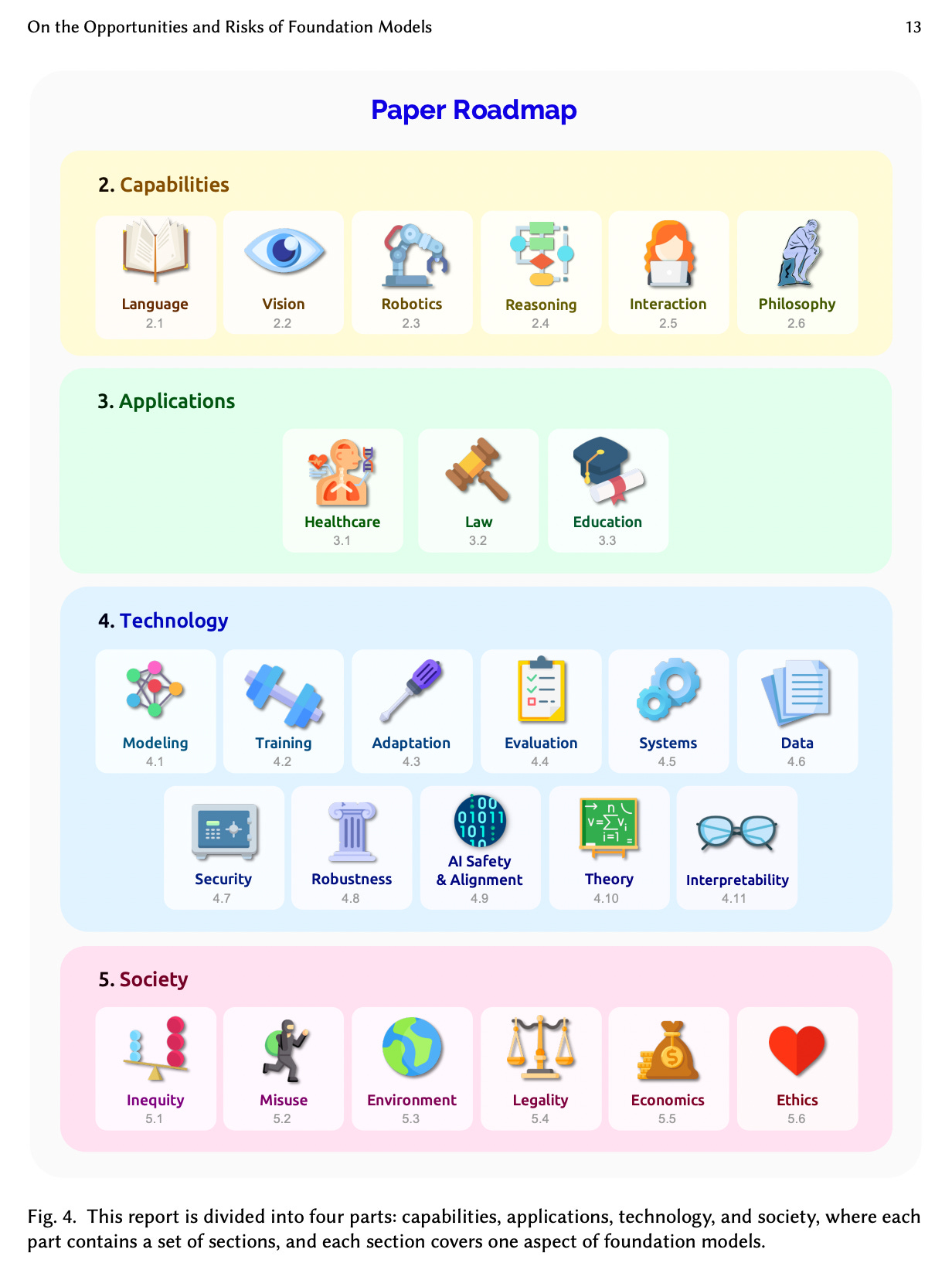
A longer list of applications and use cases might be derived from the 170 page Foundation Models paper.
Moravec’s Paradox and Superhuman AI capabilities
Why the emphasis on superhuman? Any script kiddie can code up a bunch of if statements and call it AI, but Software 2.0 type AI will have better-than-humanly-possible capabilities through a lot of data and training.
There’s also a more pragmatic reason for why to focus on superhuman capabilities - Moravec’s paradox guarantees that there will always be domains where humans are more efficient than machines. There is no point trying to compete with humans on home turf (conceptual understanding, intentional creativity, deep empathy…); machines should focus on doing things humans are bad at (storage, search, scheduling…).
We’ve started with “What AI Can Do” and refined it to “What AI Can Do Better Than Humans”. Interesting questions for AI founders. What other questions can help to narrow down the product space like this?

AI Eigenquestions
Shishir Mehrotra (YouTube, Coda) has been calling these Eigenquestions, a pseudointellectual name for the smallest set of questions that have a good branching factor that prescribe all future questions because they dominate product strategy2. See timestamped interview (59mins):
Here is my current list of eigenquestions:
Practical/Focusing Eigenquestions
Safety and Tolerance.
What are the consequences of bad results for your given product?
Conversely, what usecase benefits from 10x randomness? aka Brute Forcing Creativity.
AI hallucinates. As Sam Altman puts it, the applicability of AI depends on “how many 9’s” you need. Generative AI is best in usecases where at most one 9 is still fine. Spam/Fraud probably require at least three 9’s. Healthcare usecases may require more, which is why AI still has not replaced radiologists despite a decade of premature proclamations.
However you can smooth this path by presenting AI as an assisting factor rather than sole decision maker.
Arguable effectiveness though; Tesla Autopilot requires hands-on-driving-wheel, yet driver attention definitely decreases.
Unethical to deploy AI without considering all the ways it has already gone wrong: https://github.com/daviddao/awful-ai
Two forms of the human-machine contract: “bicycle for the mind” is more humanizing and more antifragile/hallucination-tolerant
Stagnant industries and roles.
What are humans doing today that we don’t really like to do?
What industries and jobs are low NPS/haven’t changed in a long time?
Strong clues lie in company org charts: lots of resistance replacing jobs at the top, but no resistance replacing jobs at the bottom. There is money at the bottom of the org chart.
Much harder to get people to pay for something new (like this one) they are not used to paying for, particularly if AI - feels indulgent, like a toy. Of course, it could be possible, but new behaviors are rare.
Benefits of Automation.
What types of information have a very high inbound volume?
This is great for Classification/Information Retrieval AI products, e.g. Panther Labs
What processes take a long turnaround time?
e.g. PM to Designer communication taking 1 day by human, could be shortened to 1 minute by AI, for at least the first 80% of ideation
100x improvement in OODA loop more than compensates for 10% decline in output quality
What jobs have a low branching factor?
Why is it that it feels programming is more safe from Codex than transcription services are from Whisper?
Because the variety of objective functions for programming is much larger and harder to measure than for transcription.

Abstract/Strategy Eigenquestions
How defensible is the business?
Common view of Jasper is that it is a thin layer of prompts on top of GPT3. Of course they’ve put a lot of effort into making the product usable for their audience, but how easily is a GPT3 based business cloned?
Prompt injection is essentially unsolvable with present LLM architecture; need fundamental innovation to templatize/secure. OpenAI Instruct might show the way.
A “thin” AI product can bootstrap a thick layer of user data that becomes a moat: A textual inversion bank, or other few shot personalized learning methods as the “last mile” of AI, becomes very sticky particularly if human-in-the-loop feedback is incorporated as part of the training/prediction data.
Who captures the value?
Inspired by the Fat Protocols thesis in crypto and the Smiling Curve from Stan Shih - some parts of the value chain get disproportionately more profits than others, and it pays to understand which
Surprisingly, the researchers into Foundational Models don’t view them as the value capture layer, despite them taking the most money to train. StabilityAI, and now OpenAI, are even giving away their models.
What is the “Fat” layer in AI? Horizontal AI Infra, Vertical AI Products, or something else?
Possibly a waste of time to try to answer, if the answer is “literally everyone gets rich anyway who cares”. When joining a rocketship, don’t ask which seat.
You can of course look at existing AI product businesses like Jasper.ai (went from 2.5m to >40m ARR in 2021), RunwayML (just… watch this), UIzard or Omneky or Copilot. Sam Altman really really wants someone to kill Google, Emad Mostaque really really wants to kill Powerpoint. I could’ve written a whole blogpost breaking each down but that would limit your creativity rather than prompt it.
Warning: Don’t get overexcited
There have been many AI Winters and Summers and Winter is coming.
Other Lists of AI Product Ideas
Greylock talk better than the other one with Sama
Good thread of Legal AI product ideas (my thoughts on AI for paralegals)

AI Products (vertical products built with AI as differentiator and humans/businesses as end users) as opposed to AI infrastructure (horizontal platforms offering services and primitives to AI Product companies as customers)
Nothing more that techbros love to do than invent new names for minmaxing. See also “80-20”, “Pareto Principle”, “Highest order bit”. Mixed feelings on this.
Great post! How do you find all these links and blogs around AI? Is it all from Twitter?