



Why Every Agent needs Open Source Cloud Sandboxes
Manus, Mistral, Perplexity, HuggingFace, LMArena, Gumloop and more all build agents with one secret weapon: every agent has their own computer.

Expo slots are sold out, and speaker CFPs are coming together! We’re really excited to bring you a great show. Super Early Bird tix for AI Engineer World’s Fair sell out this week, so get your tickets now and have your voice heard in the 2025 survey!
In our Winds of AI Winter in July ‘24 we first introduced the “LLM OS” as one of the new battlegrounds of the Four Wars of AI. Everything that is a tool in ChatGPT, can (and will) turn into a startup. After having Exa (Search) and Browserbase (Browser) on the pod, it’s time for E2B (Code Interpreter).
If you’ve followed us for a while, you might be familiar with them as they first released in 2023 as a cloud for AI agents, and were one of the first places you could use swyx’s smol-developer!
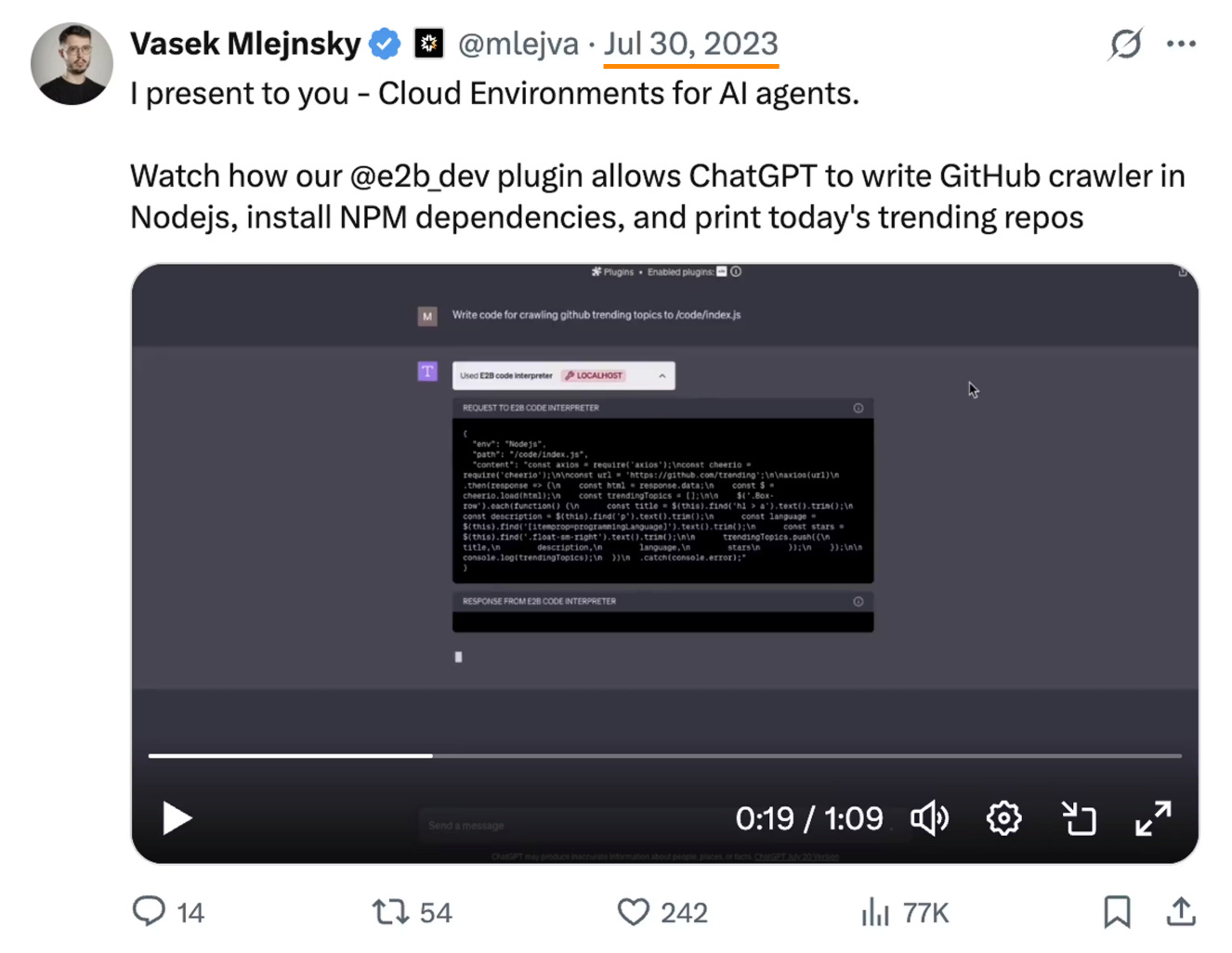
In the last 2 years, they have grown from a handful of users to being used by ~50% of the Fortune 500 and generating millions of sandboxes each week for their customers. As the “death of chat completions” approaches, LLMs workflows and agents are relying more and more on tool usage and multi-modality.
The most common use cases for their sandboxes:
Run data analysis and charting (like Perplexity)
Execute arbitrary code generated by the model (like Manus does)
Running evals on code generation (see LMArena Web)
Doing reinforcement learning for code capabilities (like HuggingFace)
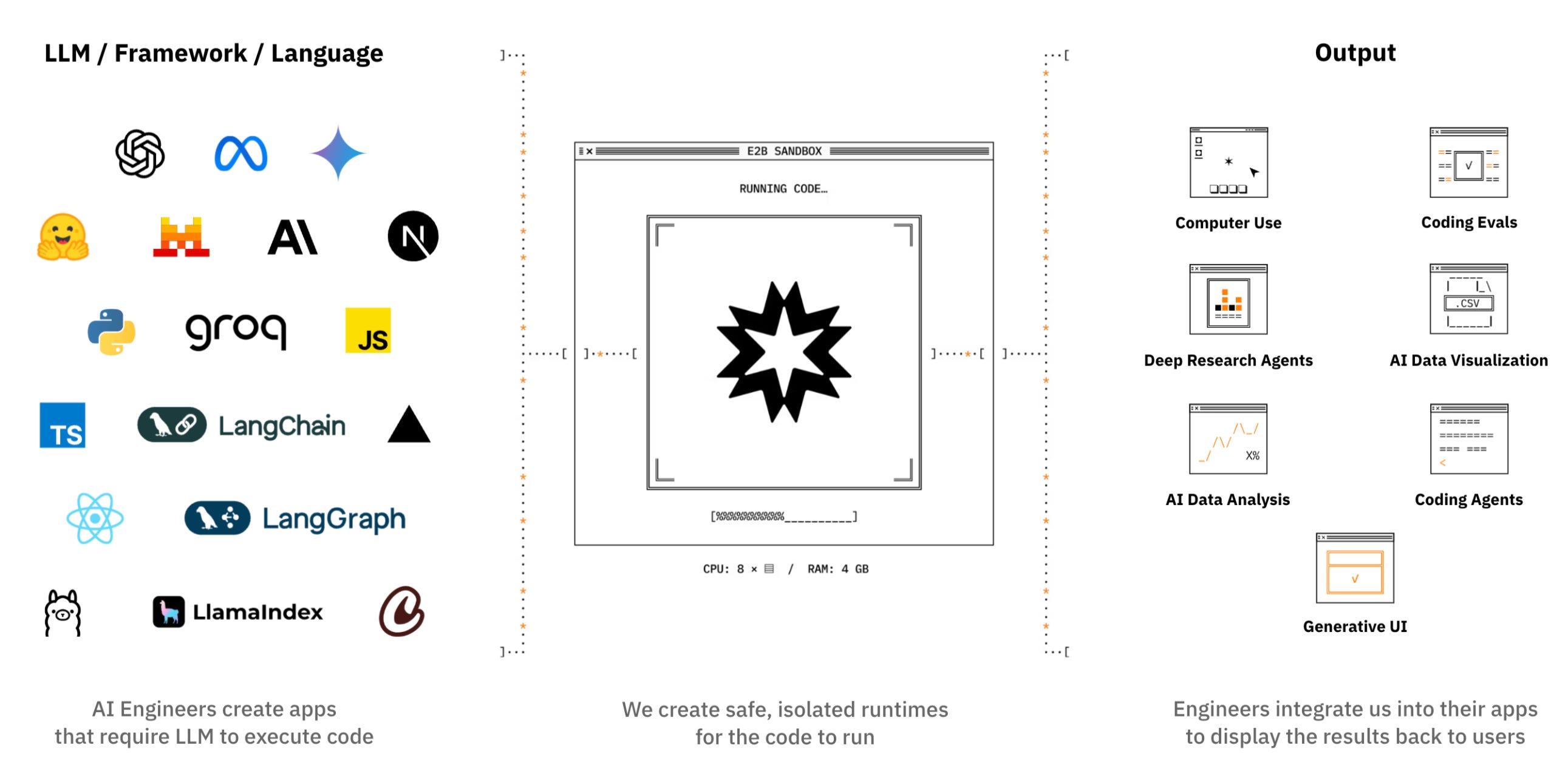
The big trend that E2B is building on is that infrastructure management is moving away from devs to AI:
2023: AI Engineers use E2B to build code interpreter into their product
2024: E2B powers generative UIs and vibe coded apps
2025: AI agents use E2B to manage a virtual computer, run code and serve results back to the users
The amount of time each sandbox ran for went up >10x from 2024 to 2025, mostly driven by new long-running agents experiences like Manus that their customers are building.
If you missed, you can check out Vasek’s full workshop from AIE World’s Fair (and signup for our next one!)
Show Notes
Timestamps
[00:00:00] Introductions
[00:00:37] Origin of DevBook -> E2B
[00:02:35] Early Experiments with GPT-3.5 and Building AI Agents
[00:05:19] Building an Agent Cloud
[00:07:27] Challenges of Building with Early LLMs
[00:10:35] E2B Use Cases
[00:13:52] E2B Growth vs Models Capabilities
[00:15:03] The LLM Operating System (LLMOS) Landscape
[00:20:12] Breakdown of JavaScript vs Python Usage on E2B
[00:21:50] AI VMs vs Traditional Cloud
[00:26:28] Technical Specifications of E2B Sandboxes
[00:29:43] Usage-based billing infrastructure
[00:34:08] Pricing AI on Value Delivered vs Token Usage
[00:36:24] Forking, Checkpoints, and Parallel Execution in Sandboxes
[00:39:18] Future Plans for Toolkit and Higher-Level Agent Frameworks
[00:42:35] Limitations of Chat-Based Interfaces and the Future of Agents
[00:44:00] MCPs and Remote Agent Capabilities
[00:49:22] LLMs.txt, scrapers, and bad AI bots
[00:53:00] Manus and Computer Use on E2B
[00:55:03] E2B for RL with Hugging Face
[00:56:58] E2B for Agent Evaluation on LMArena
[00:58:12] Long-Term Vision: E2B as Full Lifecycle Infrastructure for LLMs
[01:00:45] Future Plans for Hosting and Deployment of LLM-Generated Apps
[01:01:15] Why E2B Moved to San Francisco
[01:05:49] Open Roles and Hiring Plans at E2B
Transcript
Alessio [00:00:03]: Hey everyone, welcome to the Latent Space podcast. This is Alessio, partner and CTO at Decibel, and I'm joined by my co-host Swyx, founder of Small AI.
swyx [00:00:11]: Hey, and this is a little bit of a Latent Space Discord reunion, because we have Vasek in the house from B2B, welcome. Hey, good to see you guys, thank you for having me. Help me with your last name, because I realize I've never had to pronounce it. Mlejski.
Vasek [00:00:25]: No, no, well, I guess close in, but Mlejski. Mlejski. Yeah, and my official legal first name is Václav, but everyone pronounces it as Václav, which I hate, so it's just Vasek.
Origin of DevBook -> E2B
swyx [00:00:37]: Okay, awesome. We're both invested in E2B in different ways, but you and I go back the furthest. I just realized three years ago when you were working on DevBook, and you were interested in that developer experience angle, and somehow you pivoted to E2B, maybe you want to tell that story.
Vasek [00:00:55]: Yeah, so Tomas, my co-founder, who's our CTO. We've been interested in DevTools for quite a long time, like six, eight years. And before DevBook, there was a bunch of iterations. There were different iterations and pivots of DevBook. We just stopped renaming things at some point and just went with DevBook. The one you are talking about was interactive documentation for developers. So basically the idea was, we wanted to, instead, you as a developer, when you come to a tools doc, a website, instead of reading about everything and then Googling it and trying it in your coding editor, the idea was to give you interactive experience in the browser. So you would have pre-made interactive guides, playgrounds, you could try things right away. And the company, the owner of the docs, would prepare the experience for you, because you would also be trying everything in the browser. They would now see if you get stuck anywhere, what you are doing. So you get it very valuable. So we started onboarding analytics. We actually built an interactive playground for Prisma. I think it's still up. They are still using it. The last time I checked, a couple of months ago. So it was like interactive guides and playground that you could try out Prisma without, you know, having to manually set up all the databases and everything. So you could just try Prisma right away. And that was like the very, very first version of actually our infrastructure that we are offering now. Basically sandboxes. It was sandboxes. It literally was sandboxes, the same technology, but just completely unskillable.
Early Experiments with GPT-3.5 and Building AI Agents
swyx [00:02:35]: So then did that somehow in 2024-ish turn to E2B? 2023, I think March 2023.
Vasek [00:02:43]: And we were pretty burned out. Tomas and I, we were working from Prague, from the Czech Republic, from my apartment. Like nothing was really moving, no growth. And GPT 3.5 came out, like really first model, kind of good-ish. So we took a like, let's take 10 days break, two weeks break from DevBook and because like everyone was trying things with AI, it was very clear, like this is something where the future might go. So we wanted to just like from out of curiosity, try things out. We wanted to build like a DevIn kind of like thing. The first idea we had was like, let's automate our work because with every project we were starting. There was a set of tools you always wanted, want to integrate in your back end, like Stripe, like for SaaS business, like Stripe, analytics, Slack notifications, emails, sending out emails. And so we gave the agent the tools to run code and we needed some kind of sandbox. We were like, yeah, that's a good coincidence. We have sandbox from DevBook and we posted about it on Twitter. Basically, the agent actually pulled GitHub repository. Wrote code, started the server, tested everything. And at that point, I think we deployed it to Railway. Railway had like the best DX and it was easiest to just plug it, plug it in into the agent. I tweeted about it and I think Greg Brockman like retweeted it like, hey, like I don't remember exactly what he said. I need to find a tweet. But it was around the time where OpenAI was retweeting or OpenAI co-founders were retweeting all the things that people are doing. Like to show like what you can do with GPT-3.5 and people like it had like half a million views after a few days. And so we were with Tomas, we were like, we got to do something like people are interested in. So we just open sourced it, the repository, and it was named, the organization was like the AI company. Like we had no name. I kind of wish like we could have like a stick, like a legal stick with it. We just came up with it. With a name, it was like E2B because you take English, you convert it to bits. That's how it started. We started building community around it. And like two days later, we were like, let's focus on the sandbox part, not on the agent part. And we actually had a bunch of hypothesis behind it, like why it might be more interesting than building the agent.
Building an Agent Cloud
Alessio [00:05:19]: Yeah. And then you had the small developer, run small developer on E2B.
swyx [00:05:23]: That was a little bit later. Yeah. What was the, what, what, so this is in 2020.
Alessio [00:05:28]: When you first launched. E2B was kind of like a AI agents cloud. What did you call it? 23.
Vasek [00:05:33]: The hypothesis was like agents, code gen agents especially will need some kind of environment to run the code. And the same way developer needs a laptop or something, you know. So, but we, we struggled a lot with how the product should actually look like and what's like a go to market, the first version. And so the high level idea was like, we will host your agent. Everything from actually deploying it to then monitoring it and, and it will also have this environment running the code. One of the first like test project was taking Sean's small agent project and deploying it inside our sandbox and just giving the agent tools to pull the GitHub repositories, work on that, do a PR and then post it on GitHub, the PR on GitHub, which was very, very popular. Like, like there was. It was clear, it was clear that like, um, there was something very interesting.
swyx [00:06:31]: It's amazing how, how much people went with that. It was literally not meant to do that. It was meant to do Chrome extensions. Yeah.
Vasek [00:06:37]: And I think like you really, you had good insight that you let the agent plan the work in, in Markdown file basically. And like right on the spec, which I think even now, when you look at deep research agents, like that's sort of oftentimes what they are doing, like they plan everything. Yeah.
swyx [00:06:55]: These days I would say they should do more structured output than Markdown. Um, but, uh, you know, that's, that's an implementation detail. Yeah.
Vasek [00:07:01]: So that was taking off, but it attracted a little bit different audience than we wanted. Um, so, uh, because it's, it's attracted a lot of people who nowadays would be using tools like lovable, for example, you know, they just wanted to build projects for them. And of course, like it wasn't really working at the time, like it worked for like one simple website, but the moment you wanted something more complex, like it was.
Challenges of Building with Early LLMs
swyx [00:07:27]: I've been also reflecting on why I stopped working on it and there was actually a, uh, so when I built it, it was with, uh, cloud three, the new cloud three launches was trying to utilize the a hundred K contexts of cloud three and I use the same project to do this, to try to repeat the demo that I made for myself a month afterwards. And it wasn't anywhere as smart. So cloud three got dumber, but it looks like I like made up the demo or something, but no, like literally I just reran the same code. Yeah. And it just, it just was not as capable. And I, I mean, I think to some extent, this is like, RN Jesus, you know, hurting me or like, it's the title, it's like a different month. So like the, the model is like different or something, but I think also like basically people had this vision of what they wanted and then they tried to do it in reality and they couldn't do it because the models are not ready.
Vasek [00:08:16]: So a lot of feedback we got, um, at some point people thought like small agents is, is from us because like we had a website, like deploy small agent, but we were no, no, like that's, that's like Sean's where he should, he should go to his repository, uh, submit an issue.
swyx [00:08:32]: No, they could, they could clone it.
Vasek [00:08:34]: It was like, you know, I did it however you want for, for, for us, it was more like a test. If the environment, the sandbox is useful for the agent, if it can sort of scale and, and I can work, which worked well, but then it took us another, I would say six months to actually find the right, you know, go to market strategy, which was. Code interpreting for us. So typically AI data analysis, uh, data visualization inside like a headless Jupiter type of, uh, notebook and environment. Specifically Jupiter? It doesn't need to be Jupiter. The important part is that, um, you don't need to explain the model and the model doesn't need to care about how to keep the state of the program running. So it was, it was, especially with our earlier models, I think the models are now smarter, but they kept producing like code snippets and thought like. Yeah. They can reference to previous, uh, you know, variables and, and, and functions, definitions, uh, which if you had only normal code execution, like you run the code snippet and then you finish, it wouldn't work. So you need some kind of rebel environment. And, um, what was, I think, especially early on, like Python was the language that the models were probably the best or one of the first languages where the models were working very well. Looking back at it, there was like a really strong pool from people just wanting to visualize data and talk with their data. Python was really good at it and it makes this well with Jupiter type of environment because you get charts out of the box and you can also support interactive charts. Jupiter itself isn't the right environment to actually do it because like, uh, because all the technical problems that you will run into once you are start doing, once you start doing it on scale. So it's, it, it gets slower and slower and actually like what we are coming into is like, we are building our own thing, uh, internally, just like to support all of them specifically, it's got like your own runtime.
E2B Use Cases
Alessio [00:10:35]: At what point did you start going from just code interpreter, run code to like expand? Because now you have, you know, people doing RFT, you have computer use and all of those things. Like when were the models ready for people to start using it? Just, you know, you demoed at one of our first events as well. And I think there's always this lag between the infrastructure. Structure that you build and like the capabilities of the model. When did you go from just code interpreter to start saying, okay, now it's time to do computer use. Now it's time to do RFT.
Vasek [00:11:04]: That was probably end of 24, uh, start of 25. So when you look even at our data, like use 24, we are growing, we are growing good, but 25 is like up to the right. And so it feels like at 24 people are like figuring out these agents, um, and, and building them and trying them. And 25 is everyone. Moving them into production and finding more and more use cases around end of 24, start of 25. We started seeing things like using sandbox for, uh, reinforcement learning type of use cases or using sandbox as a, for computer use, uh, which was very interesting when Anthropic launched their computer use. We had like a desktop version of a sandbox that was sitting like in our GitHub repository for six months. We were like, okay, this is probably interesting, but no model can actually use it. So, uh, when Anthropic announced it, it was like, oh, like we have something here, uh, we can show you using, uh, with, with like lovables and, and, and Blitz's type of products also like started using the sandbox for more than just like run code snippet, like data analysis and then deep research agents that, that has been something really big in the last few months.
swyx [00:12:19]: How does deep research agents, are you referring to Manus or?
Vasek [00:12:23]: Yeah, Manus.
swyx [00:12:24]: For example, um, one of the companies. Deep research, I typically think of as like a, uh, uh, search, like a web search heavy task. Doesn't really use a code interpreter in any way. I have some idea that Manus uses E2B in an interesting code, code interpretive way to do deep research. What's the difference?
Vasek [00:12:42]: Yeah, I think it's a good idea to stop thinking about the sandbox just for code interpreting and more about like a runtime, code runtime for the LLM or the agent. But the use case for the. Sandbox, it's a very horizontal in a sense that it can cover everything from the agent needs to create a file, make a to-do list. It uses a browser, not inside the center where that's like separate, you have browser use, uh, run, uh, use being used for research on the website, but then you download the data somewhere you need to transform the data. You want to do data analysis, you want to actually write a small app, you want to create a, uh, Excel sheet. So it's, uh, the same way you are using, you know, your laptop as a human, that is the same useful for the agent. So you can think about it as more like a dev box. And at the same time, the agent that's using it is also like a very, very, uh, good developer, good accountant, good, uh, like slides, greater researcher. And so you are just basically giving it tools to let it do the job even better and faster.
E2B Growth vs Models Capabilities
Alessio [00:13:52]: Yeah. Um, yeah. And when you say up into the right, I just want to share some numbers from the investor updates. So March 24, which we're talking about, I don't know, you shared this, you shared these, you shared these publicly, but yeah, March 24, you were doing 40,000 sandboxes. You want to say how many you've done last month, March 20, 25?
Vasek [00:14:15]: Uh, I 15 million around that.
Alessio [00:14:20]: So in one year you've gone from 40,000 to 50,000. So in one year you've gone from 40,000 to 50,000. And yeah, I think you can kind of see the slope, especially from like the summit, three point seven release. And I think this is like an interesting model versus infrastructure. I think there's this usual, like VCO, we should invest in like the tools, you know, the picks and shovels instead of the application layer. But I think it's, this is like the first time where like the infrastructure is lagging the applications.
Vasek [00:14:45]: That's a good point. Like, I think 24 was all about like the agent couldn't use the whole sandbox. And now, uh, yeah, sometimes we are actually like catching up on, with some features for the, for the LMS, uh, that they need more than what we have, uh, at the moment. Yeah.
The LLM Operating System (LLMOS) Landscape
swyx [00:15:03]: I guess like what we're doing here, you know, you are another one of the LLMOS companies that we are talking to. We also did one with browser base and, um, I'm not sure who else would qualify under that, that term. Exa. Exa. Yeah. Yeah. Uh, so like, basically like you don't specifically yourself use LLMs. Internally in your products, but you enable others to work, to augment their LLMs with your infrastructure. Yeah. Um, I don't know any reflections on just the general LLMOS landscape. You have other competitors, like, you know, how, how is this evolving? How do you, how do you position in it?
Vasek [00:15:38]: A lot of people are saying like, if you are a GPT wrapper in 23, you were really bad positioned, uh, because like all the value will be captured by the AI labs. It's a good to be GPT wrapper because you get all the advantages from a new model. You just switch it. I mean, the just is like not so simple, probably have evals, um, need to change your prompt a little bit, but I would say it's increasingly easier to switch models. So, uh, we need to think about it the same way. Like you, our users are switching models a lot. We need to be agnostic, uh, to the, to the LLMs. Oftentimes, like people want to deploy us in their cloud or on-prem, on-premise. So that's also something very important. I think a good analogy here. It's sort of like technologically, it's kind of, you want to be the Kubernetes of the world for the agent, but with much better DX, uh, and, and easier, easier to use.
swyx [00:16:32]: One thing I'm thinking about also is like, what is valuable real estate to occupy in the LMOS? Um, and I have this spectrum, I think on the browser based episode I was talking about, like either you can focus on browser emulation or you can focus on the VM, or you can do like a custom Python sandbox, like a model does. You know, like, uh, would you say that you are the most general of all of them?
Vasek [00:16:56]: Yes, it's very general, but that's not really historically how you want to market it because people don't know what to do with it. Okay. Um, so that, like we, we started as, when we had our website, uh, in 24, it said something like computer, like cloud computer for AI. People didn't just understand like what to do with it. So we had to like literally show them, like first you change it to code. Interpreting, because that's something people knew from open AI. And then you just show them very, very specific use case. And you use that to get an early traction and early set of users. And we spent a lot of time, I mean, Teresa from our team spent a lot of time, especially her, uh, on educating the market, you know, and the developers. So, uh, and I think this is the space, the AI space is you sometimes have to like show developers what they might need. And you kinda have to like trust your gut. Like this might go in this direction, maybe like this could make sense and show them like what they can build with it, because it's very hard to imagine what you can build with things that you don't even have. Right. So like, why would you need forking sandboxes or checkpointing sandboxes? Like, how is that useful? Well, it turns out if you are building some Monte Carlo type of a thing, uh, search, uh, for our agent, like it's very useful. Uh, but like to actually go for a developer who might not be like in the AI deep research type of thing. Like, it's not. It's not obvious. So, uh, you want to be agnostic, you want to be general, but you want to also show people like very clear use cases, how they can use you. And over the time they didn't get educated and realize, okay, there's more use cases. I understand the platform. Uh, they start coming up with their own ideas, but onboard people with general use cases is very hard for that's at least that's what we learned hard way. Yeah.
Alessio [00:18:47]: And you also don't really tailor to like the more DevOps infrastructure. Yeah. Person, which I think a lot of the other sandboxes are like, oh, we have a G visor runtime and we have all these like different terms that you don't really know if you're like the AI engineer type.
Vasek [00:19:01]: Yeah, that's exactly true that, um, our user, uh, isn't like an infra engineer. Um, even ML engineer usually isn't our type of a user. It's like AI engineer, you know, like the front definition you have, uh, I still remain very bullish web developers and JavaScript world, TypeScript world. Even though we have like a ton of usage from Python, um, but there's so many web developers and it's easier and easier to use LMS. I really think that you need to cater to these type of developers and make it like things simple for them. And if they want to dive in, they can, chances are like, they don't even want to, they want to focus on building. Yeah. Yeah.
swyx [00:19:41]: Product developers, not infrastructure developers. It's very interesting. Yeah. I mean, like this, this whole GPT wrapper versus model lab thing is not like, you know, it's better to work on wrapper. Over, over model labs, because you know, the model as people are making a lot of money, it's just that there is room for wrappers and the wrappers also do make money. And I think people were not seeing that in 2023. Yeah. And this is what we saw.
Vasek [00:20:02]: It's not, you know, binary. It's not either or.
swyx [00:20:05]: Yeah. Yeah. I think, uh, and then, uh, just a quick check, uh, do you know, like the rough percentage between JavaScript and Python?
Breakdown of JavaScript vs Python Usage on E2B
Vasek [00:20:12]: A slightly less JavaScript, uh, so like from number of downloads of our SDK. per month, it's like 250,000 JavaScript, close to around half a million Python. Yeah. Something around that. Two to one. Yeah. Yeah.
swyx [00:20:27]: Interesting. I mean, if, if the use case is really for code interpreting, generating charts and all these, then Python wins. Yeah.
Vasek [00:20:34]: Yeah. Exactly. Python wins for that. But once you go into more like, for example, building apps, I generated apps, then it's JavaScript winning, right? Because you probably have, you have frameworks, all the Svelte, Next.js. It's Vue.js, it's frameworks, which is like, um, JavaScript thing. It's interesting because I was thinking that it doesn't really matter what code you want the LM to produce. Like it wouldn't dictate what kind of user is using us. Right. But if you think about it, when developers are building like AI data analysis, it's typically Python developer. When developers building like a type of, um, V zero, like a use case level, like a use case is web developer. It's a product developer. So I don't know. I think this is like super obvious, um, that I wouldn't think that that would be the case.
swyx [00:21:23]: There's all sorts. I mean, both, um, argument is that you should, you should want to use something like a web container where it's like run on your own browser and it's all, it's all, you know, free and very fast. I guess what the one more critical question, like, let's say I do know my infra, well, what is the point of an, uh, cloud for AI, like computer for AI? Like, like, so basically why can I use existing tools like railway? A railway wants to go after your customers, right?
AI VMs vs Traditional Cloud
Vasek [00:21:50]: So like, why does there need to be an AI focused, you know, virtual machine, you know, sandbox or execution environment, whatever you call it. What we offer is sort of orthogonal to cloud. So beforehand, you don't know what kind of code you will be running in our cloud. So you can't really optimize it. Right. So there's no like a built deploy step, uh, per se, everything happens ad hoc during runtime. So you need to solve problems. Like you want to install dependencies. Right. You want to be able to pull GitHub repositories very, very fast. So then, uh, how do you, the work workloads we are running can go from five seconds to five hours. So that also like changes even the pricing model a lot. Uh, how do you make sure that everything makes sense for you and for the user? Like, uh, uh, from the pricing point of view, from the like unit economics and also from like just the infrastructure, uh, point of view where the, uh, you know, the sandboxes are getting placed inside your cluster, the security model is, uh, is also different usually because also comes down to, you don't know beforehand what code you will run. So by default, it's untrusted code and you need to have complete isolation between these sandboxes to make sure that you're running the right code. So you need to make sure first that like, if something happens in one sandbox, it doesn't affect other sandboxes, but also you want to know about security inside the sandbox. So as the LLMs are getting better, you want to know what's happening inside the sandbox. There's like a fun story from HuggingFace, uh, when they are using, when they were using us and are using us for their, uh, open R1 model. And one of the developers, uh, he shared it online. So I think it's okay to say that. So he lost access to their cluster because the LLMs are not working. So the LLM decided to change permissions. If that happens with us, we just like kill the sandbox and get, get a new one. Uh, he, uh, it takes like, I don't know, 150 milliseconds for them. Like they had to take down the whole cluster, set up everything. Didn't even know that this happened. So it's like, like the model, the compute model, uh, TLDR is the compute model security model is different from the current cloud providers. And you need to think from the first days about it differently. And then people use.
Alessio [00:24:09]: Depending on the, because the difference that maybe people don't think about is like, you can generate the code with the Python SDK, but it can still run Lua code or like R code. Like it's not always matched to the runtime of the SDK.
Vasek [00:24:23]: Yeah, you can, it's a general machine. So whatever you can run on a Linux, you can run inside a sandbox. And, uh, we had users like running, of course, like Python code, but a C++, we had, um, Fortran, uh, someone running Fortran. Which is like, why they were doing some, some like using very old API for like banking or something like that, but you can also start a server, uh, inside a sandbox. And then you want it to be accessible from the internet. It's a very general machine. And the challenge is like, how do you make everything fast? For example, how do you make everything secure at the same time? You need to make it accessible enough and controllable by the LM and observable for the human. So you're kind of building for two personas for a human developer, the AI engineer. Yeah. And for the LM who's like using the sandbox. Yeah.
Alessio [00:25:12]: The composability thing is something I had not thought about before, but later, like you mentioned, it's like, you know, you might need to run Fortran to access one API. And then in the next step, you'll need to take that data and run it in a Python, uh, script. And then you're going to expose that through JavaScript to something else. And like you guys can switch the runtime. Yeah. Halfway. Yeah.
Vasek [00:25:32]: And, and in idle world, you don't want to kill the sandbox, start a new one, uh, or maybe. Like create a new sandbox template. You just want to keep using the computer. And because we are in cloud, we can do it in a way that you can get more Ram. You can get more CPU, you can get less CPU. So you are really paying only for what you need. And as the LLM is doing more and more, uh, you can have very elastic sandbox and keep adding features. And the goal where we think this is getting going is the LLM, like decides what they want to do and how it wants to have. The sandbox configured. So it's basically starts controlling the infrastructure itself and creating sandboxes themselves.
swyx [00:26:15]: While we're talking about the technical details, I just wanted to let you tell people about any other technical details. Like what is the box where we get, what kind of Linux, uh, what size of whatever, what details matter here?
Technical Specifications of E2B Sandboxes
Vasek [00:26:28]: So you get Ubuntu box, you can customize it and anything Debian based is going to work. You can even add, you know, graphical interface. So if you want. To, you can run like legit, not headless, but like legit Ubuntu computer on it.
swyx [00:26:45]: So that you can do this sort of take out like an old operator type experience. Like you take over control.
Vasek [00:26:50]: We have SDK called desktop SDK that does this for you out of the box and it supports, uh, VNC. Uh, so you can also have like a human in the loop type of a thing and control everything and stream and see what's happening. So by default, you get two CPUs and half a gig of. RAM on the free tier and you can customize it on our landing page. We say up to eight gigs, but if you tell us what's your use case, you can go to 64 gigs of RAM. We have users, uh, using such a buffet sandboxes. You can go to 16 CPUs. I think, uh, if I'm not mistaken, and storage is free. Storage is free. Um, I think there's like a lot of things that are free that we probably need to think about a you know, with the dev tools, especially infra. I always see this pattern. And I had this like naive idea idea as well that founder says like, oh, this AWS pricing, it's terrible. Like you are GCP. Like you have no idea what you are paying for. There's so many like small items you need to pay for. We will start a new infrastructure company. You just were, you're just going to pay $200 per month. And then you just pay for like pure compute that works until you start scaling and you figure out, okay. Like actually like people are doing like weird stuff that I didn't expect. Like, okay. Having lots of traffic producing. We have a customer that proposed petabyte of data. Uh, I mean, it's not free to host petabyte of data and that's growing. So then you start introducing, okay, probably they should pay some amount for ingress, egress, for storage and the pricing gets increasingly complex. So I just think it's very interesting like phenomenon that, uh, you start with this brave idea that everything will be super simple, but.
swyx [00:28:38]: And we only do code interpreting, so we only need to price for compute, right?
Vasek [00:28:42]: Yeah, exactly.
swyx [00:28:44]: And then you wake up in the real world and it's messy. Yeah, so I know about this from my career in cloud. And so the common refrain is that, I call this the first principle of technology, everything can be broken down into some combo of compute, storage, and networking. If you fail to price one of them, you will get abused.
Vasek [00:29:03]: Because you're essentially offering free storage or compute or something, right?
swyx [00:29:08]: Yeah. For those interested in this idea, there's a fourth one, which is basically the control plane, or like the off layer, the IAM policies and all that. And maybe you can call that security as well. It's like the fourth layer that people kind of pay for as its own independent thing. For those also interested, HashiCorp has more breakdowns from this, like David McJanet, which I think is very interesting. If you're just in the business of running a cloud infrastructure company, you should know these things. Many hundreds of businesses have run into the exact same problems. You should just not repeat them and just learn whatever the best practice is.
Usage-based billing infrastructure
Vasek [00:29:43]: Yeah, I think the billing model has been figured out many times. So I don't think it's like the challenge is not figuring it out. The challenge is, I think, is introducing it sometimes quick enough. You actually need to do changes on your infrastructure to make sure you know about all this data that's happening and moving one way or another. But yeah, I completely agree with you. Like this problem, we are not the first one that are having it. Yeah. Do you use one of the usage-based billing providers? Orb. We are talking with Orb right now. So we are... Orbin? Meter? Open meter is another one, I think. Or meter. Yeah, metronome.
Alessio [00:30:23]: Metronome, yeah, metronome is the other one.
Vasek [00:30:25]: We have been using Stripe, Stripe's usage, which has been a little bit sometimes rougher around the edges. Yeah, this is the thing, like, we shouldn't spend so much engineering on it. Like, I want to outsource it because that's not our product. Someone else should be, like, focusing on this full time. And it's actually pretty non-trivial, like, to make sure you have everything right. And you really don't want to make mistakes here.
swyx [00:30:48]: Is there anything that you're really looking for that would say, like, OK, that's really what we want? That maybe Orb or Metronome haven't really adjusted for AI yet?
Vasek [00:30:56]: I don't think this is an AI-specific problem. This is infrastructure as you know it. For us, some things that didn't work, when we look at some of the providers where, like, the cut they took from the revenue, for example, they take from you. So some of the pricings, I don't know what's the latest, but, like, I don't remember which one was it, honestly, but I knew that pricing was basically they take a small cut from the revenue each month, which is basically, like, what Stripe does when you are processing payments. It's just like the value was really high. And then it's a lot about how hard it would be to... integrate it, like, how much time we are spending on it, because we know we don't want to build this in-house. It's more like, is the switch worth it, basically?
Alessio [00:31:41]: I'm curious your updated takes. I know you had the why isn't usage-based building a bigger category. I'm curious now with AI, with, like, token-based pricing, if you have updated thoughts.
swyx [00:31:51]: So for people who don't know context, at Netlify, we went from relatively flat tier-based pricing to usage-based billing. Because that's basically how all infrastructure companies should eventually go, because you have some whales who use a lot of infrastructure and some who don't use that much, and you shouldn't charge the same for both of them. The fun insight was that you would think that at an IS, PaaS company, that revenue is, like, the most important problem to work on, and directly impacts the company's revenue and valuation and all that. No engineers wanted to do it. And I was like, why? Like, it's... It's... We actually looked around for a long time, we tried to hire, and then we couldn't hire, so we ended up putting one of our most senior engineers on it, and she took a year to ship the whole billing project that was presumably a board-level objective, which was like, hey, let's change from this pricing plan to this pricing plan. How hard can that be? Turns out very hard, because you have to instrument everything, even the things that you're, like, I don't know if we'll ever use this.
Vasek [00:32:56]: Yeah, that's exactly what I meant. That's why storage is free. Yeah, but the first thing is, like, you need to know about everything that's happening inside of Stanford, inside of the cluster. Yeah, even your logs. How big are your logs? Yeah. It's crazy hard. The pricing is, like, actually the, not the figuring out the business model, but the integration of it and implementation is actually a lot of engineering.
swyx [00:33:18]: Yeah, soft limits, like, hard limits, like, do you cut off people when, once they bust the limits? Probably not, because they get pissed at you. Yeah. And then they also get pissed at you if you don't cut them off, because then you send them a big bill. Yeah. So you just, there's no winning.
Vasek [00:33:29]: Yeah, exactly. Um... Also, additional problem that people are asking us, like, I want to run the agent for five hours, and you can do that, and you might be a very early startup, so, like, our goal isn't to, like, cash you out, our goal is, like, you can use as much of E2B as you can and just grow, but the more, the longer you run the sandboxes, the larger is going to be your bill. So I think that's, like, it doesn't really need to correlate with how much product market fit you have, for example, how much users you have. Because with these agents, they can work for a long time, even if you are, like, a pretty early-stage company, if you have a few users, so...
Pricing AI on Value Delivered vs Token Usage
swyx [00:34:08]: Sure. I mean, yeah, I think, but there's still a question of soft limit, hard limit, that kind of stuff. Yeah, yeah, yeah. So just to answer your question on, like, billing, and for those who are interested, we actually had the CTO of Orb send in a talk for a remote track for the New York summit on, like, what he thinks pricing for agents looks like, and I think, basically, you are reselling tokens, right? The base layer is coming from either your open model cloud provider or your closed model lab API, and you resell them, and a lot of them, some people have a lot of markup on them, like, certain unnamed AI builders, and some people have negative markup on them. Like, they are basically selling you at a discount, you should buy as much as you want, because they are using VC monies to subsidize your thing. And I think that seems fine. People often, Simon Wilson often asks for, like, bring your own key solution, where, like, you know, I will have my control over, like, my relationship with them. I will have my relationships and my pricing and my credits with my LLM providers, and I will, but I want to use your app, so I'll give you my keys, and then you use the keys on behalf of me. That doesn't seem to be as popular as I think, as I understand it. I don't know if you've had that request.
Vasek [00:35:14]: It's sort of like in crypto, use your own hardware wallet. Always going to be, like, less popular than just going with the thing that's...
swyx [00:35:21]: Yeah, yeah. So literally, Alex from OpenRouter is the only person who has implemented this, and it's fine for, you know, individual use cases, because there's a lot of free tiers for it. For individuals. But yeah, I mean, I think pricing-wise, people are trying to move that discussion on, like, you know, are you positive margin on your tokens or are you negative margin on your tokens? And there's some economic reality there, but they're trying to move that to the agent work, which is, what is the value of the human labor you're replacing? Which is a whole different thing, right? So, like, instead of comparing on cost of goods sold, you're comparing on value delivered, and that is much higher.
Alessio [00:36:00]: Yeah, I feel like if we could get to a good market on, like, bid-ask of, like, work being done, and then you can kind of arbitrage how many tokens you need. But I think today the agents are so unreliable and unpredictable that, like, it's hard to price ahead of time. Because you could price any software engineering task per task, right? It's like, do a new button, it's like $500, and then I can arbitrage that. But today there's no certainty of that, and I'm curious.
Forking, Checkpoints, and Parallel Execution in Sandboxes
swyx [00:36:24]: Yeah, you would think, like... Also, this is why I was very excited about Replit when they first launched their marketplace. The marketplace credit thing. I'm not...
Alessio [00:36:32]: If Replit can't do it, then I don't know if anyone can. Right. The other technical thing we talked about before is forking. You also mentioned it before, and sandbox checkpoints and things like that. Is it something you have today, and then what are people using that for? Like, our example was the Cloud Place Pokemon hackathon. Are there more enterprise use cases where you see people request forking and checkpoints?
Vasek [00:36:56]: Yeah, we don't have this publicly now yet. But that's something we are working on to release somewhat soon. We have persistence, which is like the prerequisite to the core. You mount a volume. Yeah, and well, mount a volume, but also memory persistence, which is very interesting. So you basically can pause the whole sandbox while even when all the code is, you know, with all the context of the code execution and resume to it, resume it later and come back to it, I don't know, like two weeks later. And it's still going to be there. But the continuous session time is limited to 24 hours, right? No, that's limited in the beta in 30 days. Okay. Do you mean, are you asking about...
swyx [00:37:35]: I don't know, I was looking at your pricing pages.
Vasek [00:37:36]: Are you asking about like when the sandbox is running? The sandbox can run up to 24 hours, but when it's paused, it can be paused for like a month. I personally think this is like one of the cases where you kind of need to show the developers why it's useful. And this is something I think is going to be very useful as the agents are getting better and LMs are getting better. Because you will be able to parallelize problem solving, essentially. So you will, instead of having a single agent doing one thing, you might have multiple agents trying different paths. And if you imagine like a tree or a graph, every node is like a snapshot sandbox, like a checkpoint sandbox. And then from that node, you fork the sandbox and go to the next state. Eventually you find the right path, right? It's kind of like a, it's a tree search. So the forking and checkpointing solves the problem. It solves the local state problem. It doesn't solve the remote state because that's something you can't really control. But it solves a local state for the agent and can then come back to a state and you don't need to replay the whole session or trying to force the LM to do the same thing again. You just have, you have the chat history and you have even all the steps inside the sandbox that went to it.
Alessio [00:38:55]: Do you feel like you want to help? With like the forking and then the re-merging, because I think people understand the forking, but then it's like, okay, how do I monitor which of the leaves is successful and then how do I merge them back in the thing? Do you think that's something that you want to help people do? Like kind of spread out, parallelize and then find the winner? Or is that something people should do on their own?
Future Plans for Toolkit and Higher-Level Agent Frameworks
Vasek [00:39:18]: I think this is a sort of like a framework discussion on top of E2B. So this is like, we are looking at it. I think eventually like. Okay. We should go more higher level and I don't know if like framework is the right type of a thing. We like to, in the team, think about it as a toolkit, like instead of like building opinionated framework, how to build agents, we give you sort of like a wrapper around E2B that makes it really easy for the LMS to, for example, merge these states or navigate these three. So I think it will eventually move there. I think it's a good question to ask, like how it's going to look like. I still think like building a framework is very hard in the AI as things are moving very, very fast.
swyx [00:40:04]: Curious about frameworks. Do you see any rise in popular frameworks that we should be keeping tabs on?
Vasek [00:40:10]: Well, I have a, I have, I don't know if this is an unpopular opinion, but like people keep telling me, uh, LinkedIn isn't popular, but if you look at the stats, like it has 20 million downloads per month. How can you have not popular framework when it does, it has like 20 million downloads and it's growing, I think. Um, I think there's, there's a slight bubble, uh, in, I don't know if it's like people in SF, but like developers thinking Langchain isn't popular or used. There's one framework that's interesting. I think it's called, uh, Mastra, um, from the, one of the founders of Sam Bagwad. Yeah. He's in the discord. So that I, I like, which looks very promising. I also like it's like TypeScript first, uh, which I thought like is the right decision because as, as we talked about, like, being more bullish on the product developers instead of like a Python machine learning type of a developer, I've seen a lot of more like a toolkits or I don't know how to call them. Like for example, Composio has been one that like gives you all the tools at once. There's been more tools, more tools like that, which is interesting approach. I think also browser base is stagehand is super exciting because in my head, it's not a framework. It's like, it doesn't necessarily. Like dictate how the agent should behave. It just gives it a good tools to navigate a website. And it's very elegant, uh, like it has like, I think they added like three methods by act, see, and, and something.
swyx [00:41:40]: Yeah.
Vasek [00:41:40]: There's three APIs. Yeah.
swyx [00:41:41]: Three is observe. Yeah. Observe. Yeah. Yeah. We talked about it in that episode. No, it's cool. Uh, actually I wasn't expecting that many names to come out, but these are good names for people to know. I would agree with most of them as, as, uh, they're in the conversation of, of tooling. If, and a lot of people listen to us for like. Oh, what's going on in SF, right? Like, yeah.
Vasek [00:41:58]: Actually, it's a good question because like when you ask it, I would expect to be like bigger framework boom out is because like it would make more sense to build more sense to build a framework now instead of 23, because things are a little bit more stable. Big problem with frameworks is that the idea of framework should probably be that things aren't changing underneath your hands, which if you launch your framework in 23, uh, it was, uh, so that's not a fun thing to be at as a developer. Who's using the framework. I think some things are still changing. I mean, things are a hundred percent still changing, but I'll slightly, I would say like some things are clearer than in 23.
Limitations of Chat-Based Interfaces and the Future of Agents
swyx [00:42:35]: Like, I don't think people realize, but like, I'll just say it out here. Like chat competitions is dying. So like any framework that was built in that era with like no conception of real time, no conception of omni-modal or multimodal native things, they will probably not age very well. Yeah.
Vasek [00:42:52]: Yeah. Probably as we like, what's the next after chat based. Yeah. Yeah. Probably as we like, what's the next after chat based. Yeah. Probably as we like, what's the next after chat based interaction with LM.
swyx [00:42:57]: Yeah. You need chat competitions and you also need reasoning with streaming and the streaming interactions of agents is also not mapped out very well, but like all agent frameworks will have to adjust to that basically.
Vasek [00:43:09]: Good question to ask when thinking all about dev tools with LM, is my dev tool more relevant as the LMs are getting smarter and as people need less prompting? I'm, I'm, for example, like really bad at prompting, but like I can get more work done over the years because the LMs are getting better. So that means like there's less need for prompt management type of a thing. Yeah.
swyx [00:43:30]: The talk from Ramp at our New York conference was basically about this, like how do you set up your, your architecture so that you benefit from 10,000 X improvements in models rather than every time you, you know, model improves, you have to kind of throw out your existing workflows. Yeah.
Vasek [00:43:47]: The question we ask very often when thinking about the features and like how to position ourselves in the ecosystem.
Alessio [00:43:55]: We have gone 51 minutes without talking about MCPs, which is tragic. Yeah. How do you do that?
swyx [00:44:02]: How do you talk about AI infrastructure and no MCP?
Alessio [00:44:04]: Right? It's kind of crazy. But since you mentioned the prompts that we just had the episode with the MCP creators and they were, I wouldn't say not frustrated, but maybe they hope more people will use the prompts and resources and MCP servers instead of just the, the tool costs. I'm curious if you've seen any fun use cases with like remote MCPs on, on E2B or. Yeah. Any other things like that?
Vasek [00:44:26]: Yeah.
swyx [00:44:27]: MCPs watching it very closely, but like still undecided, but actually not what it is, but kind of like what to do with it. There's no MCP on your docs, bro.
Vasek [00:44:37]: Uh, go to, if you go to a GitHub, we have like MCP server. Um, but yeah, we, we seen people using E2B to, uh, host MCPs. Like, but then I would say like, I don't think you need E2B for that. You can just. Probably you can run it. It's not like even like optimized for it probably. It's not like the, there are probably better ways to do that. I think people are a little bit too much focused on the protocol side of it. I even like calling it a protocol. I don't know. It's just like a server. Uh, and there's like a. A server end client. Yeah. Server end client. And there's some agreed. So I guess like in a sense it is a protocol, but like, uh, I see a lot of people like comparing it to email protocols and such, which is like, I don't know. It seems a little bit far stretch to me, uh, at this current moment, but maybe I'm missing something. Like I'm, I think it's super interesting idea. I just haven't had direct, I guess the right insight about it yet. One last thing I wanted to add, like, because we have a bunch of users that added E2B our MCP server to their like registries. Uh, so I think at least at the moment, like what's more useful is like higher order MCPs. I was talking with Henry from Smith area around it. Uh, about it, uh, that, that, you know, and he was saying exactly this, uh, telling me exactly this concept, like it's unclear who's using the MCP at the moment. Is it a developer? Is it a like end user or is it another agent? If it's a developer, then it might be like, makes sense to have like a sandbox creation of sandbox in the MCP. But if it's an end user, probably like it's too low level primitive. So he wants some kind of higher order MCP. Like instead of us offering like a sandbox. We would be offering like a way to build a cogen agent with MCP or something like that. Or run a cogen agent that's using E2B MCP like in the background. So I have more like a, like these type of unanswered questions in my head about MCPs.
Alessio [00:46:39]: I mean, they are all running locally right now. Mostly. I don't think there's many remote MCP servers yet. I know that people are pushing for it.
Vasek [00:46:47]: It looks like there's more remotely actually. I don't know. That's what I heard from people like managing these registries of MCPs.
swyx [00:46:55]: Well, they're incentivized to tell you that. Yeah.
swyx [00:46:59]: I fully agree with that confusion about what to do. I do think that every dev tools company needs some kind of MCP strategy for better or worse. It's annoying as it is. I think it does start with having an API though, rather than like a SDK first experience. Because then you, people can just wrap in whatever. Language that they want. And then you also, for you particularly, you might want to have a distinction in your strategy for MCP clients versus MCP servers. Because those might be different things. And particularly, I liked what you said about the higher order MCP for the end user who doesn't really care about implementation detail. I think that is fantastic for E2B where like the agents can just spin up an E2B instance in the background and they don't even know about it. Yeah.
Vasek [00:47:48]: In the ideal world, we have like mcp.e2b.dev. First, it needs to have figured out authentication. So the agent should just ask to have, I guess, an account created for it or whatever it is it's going to be. And then it can just like launch a sandbox, do the execution there, and you can come back to it a month later and the state is still there. So that I think makes a ton of sense. Then you can start building higher order things on top of that, which could be very interesting. Yeah. I like what you said about having API first versus SDK first approach. I think this is very, very important for the LLMs. And that's how we are building our whole new dashboard, the infrastructure. So everything needs to be API controllable from like public APIs for users because eventually the LLMs will want to control and gather this data. Okay. So that's a big shift for E2B because you're SDK first. It has been like underneath API base all the time. But now we will go more into it. And it was more like in terms of prioritization. So we needed to start with humans to get to LLMs and first build for human developer and then now building for like a LLM developer first. Yeah.
swyx [00:49:03]: I'll just call out that since we did the MCP episode, they announced their update to the spec that they added an off component to the spec itself. It seems to be just based on OAuth 2.1. And I assume like, you know, that's the first easy step. That's the easiest thing to do. But there's no effective distinction between an agent and an user. We never had that.
LLMs.txt, scrapers, and bad AI bots
Vasek [00:49:22]: I think this is more like a broader question of you have like all the websites that has optimized everything for humans. But now you will have like agents visiting those websites. Like what are the incentives there? You know, like probably you as a website owner, you want to know it's an agent because you spend so much time and money optimizing everything for humans. So I think like the dynamics on the internet might get really weird if you don't have a distinction. This is a human, this is an agent. Yeah.
Alessio [00:49:52]: We tried to record an episode with Matthew Prince, CEO of Cloudflare yesterday. And then we had technical difficulties, but they're building a lot of that.
swyx [00:49:58]: You can see the stats. Yeah.
Alessio [00:50:00]: They mentioned, for example, used to be, you know, Google will be a two to one crawl to referral ratio. So for every two pages they will read, they will send you one visitor. Yeah. He said OpenAI is 250 to one. So they'll read 250 of your pages and send you one visitor. And then Throbic was like 6,000 to one. Wow. So they'll read 6,000 pages before they send one person back to your website. So obviously we have Jeremy Howard who's been working on LLMs.txt to kind of have a separate interface for that. I think today people don't really curate the LLM experience. I think a lot of the LLM TXT that people are making is like automated, take a website and turn it into LLM.txt. But like, that's not really what you want to do. It's like, how do you separate completely the two things? You know, like if you're an e-commerce store, the LLM TXT should have your own inventory and like one thing, you know, shouldn't have a search button.
swyx [00:50:51]: I feel like obviously LLMs.txt is a good movement that improves the legibility of these doc sites for LLMs. But I feel like it's kind of like a halfway measure. Like, I think we've failed with agents if we are reshaping the human environment for agents. Like there must be two of everything. What's your human side and what's your agent side? Like, no, like agents should just be the human side. Yeah. Why are we making any special dispensation for these things?
Alessio [00:51:17]: Yeah, I think the monetization is the only thing. Like too many websites are like ads driven, kind of like... You need to look at it, right? Yeah, I think you need to change. Once we figure that out, you know, I think you can use the same interface. But I think today just like all these pop-ups, it's like, fuck man, stop popping. Okay, so Bitcoin solves this. Yeah.
swyx [00:51:34]: I'm just kidding. But anyway, yeah. I don't know if you have a take on all this.
Vasek [00:51:39]: I have like a general rule that there's a... Usually when something new comes out, people have this tendency to recreate the thing that already exists for the new thing. Like that's like the internet for agents versus you already have all the infrastructure for the old thing and probably might be easier to teach the new thing to use the old thing. I think it's very common coming from developers that it will be a perfect world when you have nice, clear distinction between these two. But actually the world is super messy. So nothing comes to my mind that they would like end up that... You have clear distinction between like two type of sort of entities or we created like a new internet for just mobile phones. You actually have both desktop website version and mobile phone version, right? It's much more always complicated and messy in the real world than having a nice, clear distinction, which is something I think developers strive for just from working with code because you want this nice, clear distinction. But humans are more complicated than that. So I think like... Everything ends up being sort of mixed and you need to adapt to it. For sure. Yeah.
swyx [00:52:48]: I think we'll do this for 20 years and then we'll figure out the... Yeah.
Vasek [00:52:51]: And probably it will be somewhere in between that you have like a world where agents are using human internet, but the internet changed because you have agents or something like that.
Manus and Computer Use on E2B
swyx [00:53:00]: This reminds me of some conversation that I think... I don't know who was making this analogy. Like in the mobile era, we had m.yourdomain.com and then we had www.yourdomain.com. And now we might have like just llm.yourdomain.com. And that's just the LLM experience. mcp. Oh, yeah. Way better. Yeah. Consumes everything. Cool. We're just going to go through all the rest of the use cases. We can refer people to your website. But I always want people to have a good mental map of when they should go to E2B and what other people are using E2B so that they don't miss out, right? So it's AI data analysis, data visualization, coding agents, generative UI, code gen evals, and computer use. Do you think that's like the sequence of most popular data analysis, least popular is computer use?
Vasek [00:53:47]: Most experimental is computer use, I would say. It still gets a lot of traction when you share the demos of it. It's just Manus.
swyx [00:53:56]: Who else is doing this? I basically don't see anyone else.
Vasek [00:53:59]: When you say computer use, I imagine like a graphical interface. Manus, as far as I know, isn't running that. So what do you also call a kind of computer use but without graphical interface? Because you are using the full computer, but more from like code point of view. But that's a different discussion. I would say like computer use is very exciting, but experimental from what I've seen. Yeah, okay. I think for real computer use, you really want to support more platforms than just Linux.
swyx [00:54:29]: Yeah, Windows, right?
Vasek [00:54:31]: And then it gets, it might be more licensing battle than technical battle.
swyx [00:54:37]: Yeah, lawyers always win. Yeah. We'll probably have Erik for the next question. We'll probably have Erik from PIG at some point talk about his movements on Windows. So that was going to go into evals, right? And also how that links to RFT. Yeah, just like, can you tell more stories about the Open R1 projects, how you work with them and any other like academics that are working with E2B that you think could be possible for like the researcher model training use case or fine-tuning use case?
E2B for RL with Hugging Face
Vasek [00:55:03]: Yeah, the way Hugging Face will build the Open R1 project is using us is during like the reinforcement learn, CodeGen reinforcement learning step where the R1 model, the Open R1 model has a training step where they give it a code problem and the model needs to generate and run code somewhere. Then you have reward function basically giving you zero or one telling you if that was a good solution or bad solution, then you improve the model. So kind of like the feedback loop. They are using the E2B sandboxes to run many hundreds of these sandboxes, thousands of these sandboxes per training step. So they can achieve like big parallelization. We started very fast. You don't need to use your GPU cluster for that, which is like very expensive to use for this type of workloads. And also, and that goes with the story that I mentioned in the beginning is that you don't need to worry about like the LLM actually like changing permissions in your cluster and then you can access the cluster because everything is isolated and secure from each other. So I think that's very, very interesting use case because we've had a few other companies like reaching out and started using us this way, building models, foundation models. It's like when we started E2B, that wasn't the use case that we had in mind. So, but it's like makes total sense if you also, if you think about like life cycle of an AI agent. Like if you, it makes a lot of sense for us to be like from the earliest stage possible and the earliest stage is probably model training. So this fits very, very, very nicely in that, in the use case. We actually released a case study with Hugging Face that's on our website that people can read.
Alessio [00:56:53]: Have you seen people also use that to evaluate agents they want to use or is it mostly people doing training?
E2B for Agent Evaluation on LMArena
swyx [00:56:58]: We've seen people using E2B for evals. Yeah, that's what I'm thinking. Like it should be very easy to run like suites. We've seen people using E2B bench and all these on E2B. Yeah.
Vasek [00:57:07]: This is more foreshadowing, but we will be launching in the next couple of months, like a startup and research program for people and universities and researchers like doing exactly these type of things. Different use case, but we, for example, work with LM Arena folks from Berkeley that are using us to compare models in AI app generation and we run the AI generated app. He wrote that in the equation, right? Yes. I did. I did. I think that's only possible thanks to Alessio. And I'm not joking because first he connected it and then he actually wrote it.
swyx [00:57:41]: Man, the things you have to do to win deals these days. Full stack value add.
Vasek [00:57:46]: He was already our investor. So I think that also shows it even in a better light because you clearly see the person is not interested just to win the deal, but actually, you know. To increase the value of the investment. Exactly. Like how many VCs are actually fixing your bug in your code base?
Alessio [00:58:03]: Let's make a YouTube short of this part so I can share it. You should put it on our landing page. Yeah, exactly.
Long-Term Vision: E2B as Full Lifecycle Infrastructure for LLMs
Alessio [00:58:12]: Awesome, man. So let's talk about, since you mentioned VCs, a lot of VCs that passed on you before because you only do code execution, it's kind of like a small market. I would love for you to maybe also paint the picture, you know. So you just mentioned it's cheaper than the GPU cluster than Hugging Face has. Do you want to do GPUs in the future? You mentioned Railway. That was easy to do. Do you want to compete with Railway down the line? Like where do you see E2P going?
Vasek [00:58:37]: So GPU question is an interesting one. The GPU market is hard. Like you are competing on the compute internal, I think it's hard because eventually you will have competitors and everyone will be like pricing it a little lower and no one is making any margin. So that's like, but it just opens new use cases for you. And for example, even with the data analysis, if you just run, I think it's Pandas code from, there's a recent update, like recent update. If you just run it on GPU, it's like twice as much faster. If we want to like do really big AI data analysis, you need that. So I think like GPUs for us, and also if you want to like have LLM train small machine learning models, maybe you want to like build full games, you really want to offer the full cloud computer, but in cloud, that's very elastic. So I think GPUs are there on the roadmap. I wouldn't say it's like the thing that we are immediately working on, but eventually it makes like a lot of sense for us to offer this. And so what was the other question? On the, do you want to host the apps that you are building too? We are very well positioned that the LLM is doing all the development work with us. Then you need to deploy it somewhere. So it's like very next natural next step. Eventually, like we want the LLMs to work. We want the LLMs to deploy these services, apps that are building and have them manage it. And developer is more like in the backseat, like looking at things, if everything is working correctly. If your swarm of agents is working correctly. It also requires a slightly different infrastructure for deploying. But I think there's a big advantage in knowing what developers are building on our platform. And then, because then you can see like what's the ideal, even from technical point of view, you have all the insights that you need to actually affect your business. So you can effectively deploy it and kind of then cover the full lifecycle of building the app. But now it's not built by the human developer. It's built by the AI. So TLDR, yes, probably down the road somewhere. We want to build essentially like the new AWS, but for LLMs.
Why E2B Moved to San Francisco
Swyx [01:00:45]: So we're just going to move out and just to wrap up. One of the interesting things that I saw you do was you were originally check-based. And I'll be very honest. When I first invested in the early round that you did, I was like, these guys know how to recruit in Czech Republic. It's like a competitive advantage. And then the next thing I know, you're moving to SF with your You show up to our office.
Vasek [01:01:15]: That's hilarious. Actually, I think you offered even your place to live for.
swyx [01:01:23]: So why move to SF? Do you think that everybody in your kind of similar situation should? Any pros and cons that you have?
Vasek [01:01:31]: I think it's you can definitely build a DevTool company from Europe. I think it's a lot about question of how easy you want it to be in the earlier days. Especially if you are building like a, you know, kind of like red ocean versus blue ocean waters. If you are building in a field that already exists and you have like large competitors, you're building something that's 10 times, 100 times better. It's probably, you probably don't need to be NSF. Eventually, you probably will need some kind of US base because for sales and customers. But you can very well build this from Europe. I know great companies doing that because all it's the knowledge is already among all the developers. But I would maybe argue that it might be harder to find people that are comfortable with fast iteration loop and changing things early on. You know, almost we are pivoting every week, every month. But the main motivation for us was we just wanted to be very close to our users. And it was clear after a few weeks that SF is becoming this AI hub. And what we used to do and we still do it sometimes, but slightly less because of like not having that much time and resources. But we just met with the customers that had problems, our users. And we just like implemented it to be for them, like next to them. Like we made a PR.
swyx [01:03:02]: I call this the Collison installation.
Vasek [01:03:05]: By the way, I don't know if this is like a known thing, but do you know how many times they did that? 200? Twice, three times. Oh, lol. I asked about like three years ago when I had a chance to ask a question from Patrick Collison. Like how many times you did the Collison installation? And he was like three times. But then after that, you probably don't want to do that because you want to automate things and focus on other stuff. Nice. But it's exactly like do the things that don't scale. Three times. Are you kidding? Exactly three.
Vasek [01:03:40]: But my whole point was that how many such users I can meet in Prague in a week versus in San Francisco in a week. In Prague, it's going to be probably one. And then I can't meet anyone else for the next half of the year because I just don't have users in Prague. But all of my users, our users were here. So we could just keep repeating doing that again and again. I would even argue we did it too much. We could have automated slightly faster. But it's very useful feedback that you can get. And you can then start moving much, much, much faster. So that was important. And I think also eventually you are in like you are in the B2B business even from the early days. And it's good to have good relationship with people. And just like meeting in person is just better than meeting over Zoom. Well, I mean, that's why we do this in person.
swyx [01:04:32]: But yeah. I mean. You know, obviously I run a conference. I'm very sympathetic to people meeting in person. Right. But I also want there to be some hope for people who are who are never going to come to SF that like they can still get involved. That's partially why we do this podcast is to get them involved in the community.
Vasek [01:04:48]: And I mean, we started a new office in Prague. Yes. You're hiring again in Prague. Yeah. And I think that there's really good talent in Europe, in Czech Republic, for example. I don't know. I can't speak for other countries, but I can imagine it's very similar. Once you have like a clear idea of what your product looks like, then you can find really good expert on certain part of your infrastructure on database and things like that. And just like have a top talent, get top talent for that. The reason we didn't want to do it early on was because we kind of didn't know ourselves what we were building. And we had to figure it out in person with users here. But now we feel much more strong about like knowing the roadmap for the company and for a product. And so it's much easier to hire people that have our difference from us and explain them what they are building even remotely. Sometimes if you are not there and you're just communicating through Slack.
Open Roles and Hiring Plans at E2B
Alessio [01:05:49]: Just to wrap, what are the roles that you're hiring for?
Vasek [01:05:52]: So we are hiring distributed systems engineers. We are hiring platform engineers, AI engineers. We are also hiring account manager and customer success engineer. So kind of all over the place, we see a lot of market pool and momentum being built up. So we want to double down and move even faster because we see all the potential of what we can do. And just want to kind of like you want to pour the gas on the fire on the spark. And that's how I feel where we are now at E2B.
Alessio [01:06:25]: Awesome, man. Thank you so much for coming on. Yeah.
Vasek [01:06:27]: Thank you for having me. It's great.