




The most recent YCombinator W23 batch graduated 59 companies building with Generative AI for everything from sales, support, engineering, data, and more:
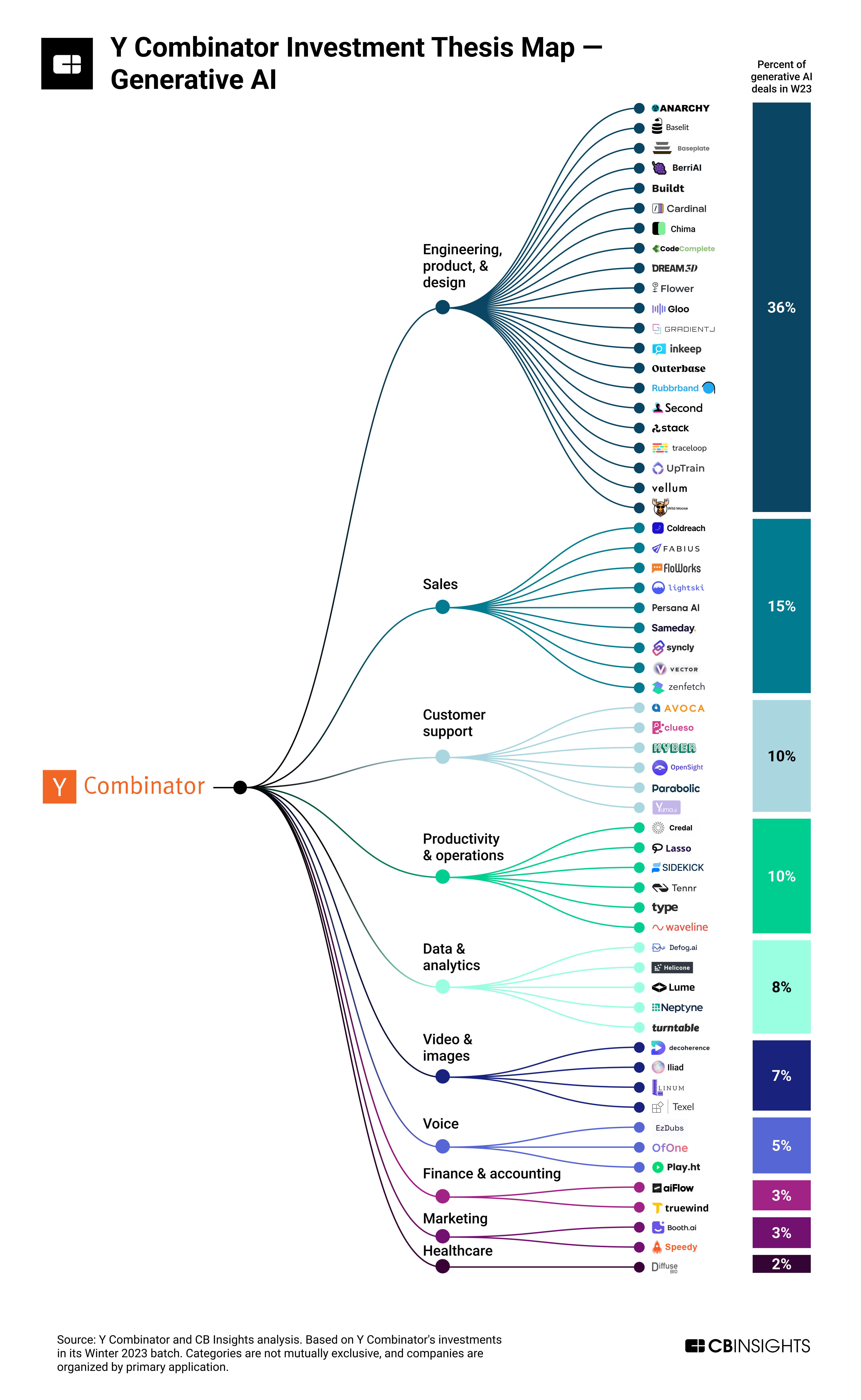
Many of these B2B startups will be seeking to establish an AI foothold in the enterprise. As they look to recent success, they will find Glean, started in 2019 by a group of ex-Googlers to finally solve AI-enabled enterprise search. In 2022 Sequoia led their Series C at a $1b valuation and Glean have just refreshed their website touting new logos across Databricks, Canva, Confluent, Duolingo, Samsara, and more in the Fortune 50 and announcing Enterprise-ready AI features including AI answers, Expert detection, and In-context recommendations.
We talked to Deedy Das, Founding Engineer at Glean and a former Tech Lead on Google Search, on why he thinks many of these startups are solutions looking for problems, and how Glean’s holistic approach to enterprise probllem solving has brought so much success.
Deedy is also just a fascinating commentator on AI current events, being both extremely qualified and great at distilling insights, so we also went over his many viral tweets diving into Google’s competitive threats, AI Startup investing, and his exposure of Indian University Exam Fraud!
Show Notes
Deedy on LinkedIn and Twitter and Personal Site
Deedy on Google vs ChatGPT
Deedy on Google Ad Revenue
Deedy on How much does it cost to train a state-of-the-art foundational LLM?
Deedy on Google LaMDA cost
Deedy’s Indian Exam Fraud Story
Lightning Round
Favorite Products: (covered in segment)
Favorite AI People: AI Pub
Predictions: Models will get faster for the same quality
Request for Products: Hybrid Email Autoresponder
Parting Takeaway: Read the research!
Timestamps
[00:00:21] Introducing Deedy
[00:02:27] Introducing Glean
[00:05:41] From Syntactic to Semantic Search
[00:09:39] Why Employee Portals
[00:12:01] The Requirements of Good Enterprise Search
[00:15:26] Glean Chat?
[00:15:53] Google vs ChatGPT
[00:19:47] Search Issues: Freshness
[00:20:49] Search Issues: Ad Revenue
[00:23:17] Search Issues: Latency
[00:24:42] Search Issues: Accuracy
[00:26:24] Search Issues: Tool Use
[00:28:52] Other AI Search takes: Perplexity and Neeva
[00:30:05] Why Document QA will Struggle
[00:33:18] Investing in AI Startups
[00:35:21] Actually Interesting Ideas in AI
[00:38:13] Harry Potter IRL
[00:39:23] AI Infra Cost Math
[00:43:04] Open Source LLMs
[00:46:45] Other Modalities
[00:48:09] Exam Fraud and Generated Text Detection
[00:58:01] Lightning Round
Transcript
[00:00:00] Hey everyone. Welcome to the Latent Space Podcast. This is Alessio, partner and CTO and residence at Decibel Partners. I'm joined by my, cohost swyx, writer and editor of
[00:00:19] Latent Space. Yeah. Awesome.
[00:00:21] Introducing Deedy
[00:00:21] And today we have a special guest. It's Deedy Das from Glean. Uh, do you go by Deedy or Debarghya? I go by Deedy. Okay.
[00:00:30] Uh, it's, it's a little bit easier for the rest of us to, uh, to, to spell out. And so what we typically do is I'll introduce you based on your LinkedIn profile, and then you can fill in what's not on your LinkedIn. So, uh, you graduated your bachelor's and masters in CS from Cornell. Then you worked at Facebook and then Google on search, specifically search, uh, and also leading a sports team focusing on cricket.
[00:00:50] That's something that we, we can dive into. Um, and then you moved over to Glean, which is now a search unicorn in building intelligent search for the workplace. What's not on your LinkedIn that people should know about you? Firstly,
[00:01:01] guys, it's a pleasure. Pleasure to be here. Thank you so much for having me.
[00:01:04] What's not on my LinkedIn is probably everything that's non-professional. I think the biggest ones are I'm a huge movie buff and I love reading, so I think I get through, usually I like to get through 10 books ish a year, but I hate people who count books, so I should say the number. And increasingly, I don't like reading non-fiction books.
[00:01:26] I actually do prefer reading fiction books purely for pleasure and entertainment. I think that's the biggest omission from my LinkedIn.
[00:01:34] What, what's, what's something that, uh, caught your eye for fiction stuff that you would recommend people?
[00:01:38] Oh, I recently, we started reading the Three Body Problem and I finished it and it's a three part series.
[00:01:45] And, uh, well, my controversial take is I did not really enjoy the second part, and so I just stopped. But the first book was phenomenal. Great concept. I didn't know you could write alien fiction with physics so Well, and Chinese literature in particular has a very different cadence to it than Western literature.
[00:02:03] It's very less about the, um, let's describe people and what they're all about and their likes and dislikes. And it's like, here's a person, he's a professor of physics. That's all you need to know about him. Let's continue with the story. Um, and, and I, I, I, I enjoy it. It's a very different style from, from what I'm used.
[00:02:21] Yeah, I, I heard it's, uh, very highly recommended. I think it's being adapted to a TV show, so looking forward
[00:02:26] to that.
[00:02:27] Introducing Glean
[00:02:27] Uh, so you spend now almost four years at gle. The company's not unicorn, but you were on the founding team and LMS and tech interfaces are all the reach now. But you were building this before.
[00:02:38] It was cool, so to speak. Maybe tell us more about the story, how it became, and some of the technological advances you've seen. Because I think you started, the company started really close to some of the early GPT models. Uh, so you've seen a lot of it from, from day one.
[00:02:53] Yeah. Well, the first thing I'll say is Glean was never started to be a.
[00:02:58] Technical product looking for a solution. We were always wanted to solve a very critical problem first that we saw, not only in the companies that we'd worked in before, but in all of the companies that a lot of our, uh, a lot of the founding team had been in past their time at Google. So Google has a really neat tool that already kind of does this internally.
[00:03:18] It's called MoMA, and MoMA sort of indexes everything that you'd use inside Google because they have first party API accessed who has permissions to what document and what documents exist, and they rank them with their internal search tool. It's one of those things where when you're at Google, you sort of take it for granted, but when you leave and go anywhere else, you're like, oh my God, how do I function without being able to find things that I've worked on?
[00:03:42] Like, oh, I remember this guy had a presentation that he made three meetings ago and I don't remember anything about it. I don't know where he shared it. I don't know if he shared it, but I do know the, it was a, something about X and I kind of wanna find that now. So that's the core. Information retrieval problem that we had set out to tackle, and we realized when we started looking at this problem that enterprise search is actually, it's not new.
[00:04:08] People have been trying to tackle enterprise search for decades. Again, pre two thousands people have been trying to build these on-prem enterprise search systems. But one thing that has really allowed us to build it well, A, you now have, well, you have distributed elastic, so that really helps you do a lot of the heavy lifting on core infra.
[00:04:28] But B, you also now have API support that's really nuanced on all of the SaaS apps that you use. So back in the day, it was really difficult to integrate with a messaging app. They didn't have an api. It didn't have any way to sort of get the permissions information and get the messaging information. But now a lot of SaaS apps have really robust APIs that really let.
[00:04:50] Index everything that you'd want though though. That's two. And the third sort of big macro reason why it's happening now and why we're able to do it well is the fact that the SaaS apps have just exploded. Like every company uses, you know, 10 to a hundred apps. And so just the urgent need for information, especially with, you know, remote work and work from home, it's just so critical that people expect this almost as a default that you should have in your company.
[00:05:17] And a lot of our customers just say, Hey, I don't, I can't go back to a life without internal search. And I think we think that's just how it should be. So that's kind of the story about how Glean was founded and a lot of the LLM stuff. It's neat that all, a lot of that's happening at the same time that we are trying to solve this problem because it's definitely applicable to the problem we're trying to solve.
[00:05:37] And I'm really excited by some of the stuff that we are able to do with it.
[00:05:41] From Syntactic to Semantic Search
[00:05:41] I was talking with somebody last weekend, they were saying the last couple years we're going from the web used to be syntex driven. You know, you siegal for information retrieval, going into a symantics driven where the syntax is not as important.
[00:05:55] It's like the, how you actually explain the question. And uh, we just asked Sarah from Seek.ai on the previous episode and instead of doing natural language and things like that for enterprise knowledge, it's more for business use cases. So I'm curious to see, you know, The enterprise of the future, what that looks like, you know, is there gonna be way less dropdowns and kind of like, uh, SQL queries and stuff like that.
[00:06:19] And it's more this virtual, almost like person that embodies the company that is like a, an LLM in a way. But how do you do that without being able to surface all the knowledge that people have in the organization? So something like Lean is, uh, super useful for
[00:06:35] that. Yeah, I mean, already today we see these natural language queries as well.
[00:06:39] I, I will say at, at this point, it's still a small fraction of the queries. You see a lot of, a lot of the queries are, hey, what is, you know, just a name of a project or an acronym or a name of a person or some someone you're looking for. Yeah, I
[00:06:51] think actually the Glean website explains gleans features very well.
[00:06:54] When I, can I follow the video? Actually, video wasn't that, that informative video was more like a marketing video, but the, the actual website was showing screenshots of what you see there in my language is an employee portal. That happens to have search because you also surface like collections, which proactively show me things without me searching anything.
[00:07:12] Right. Like, uh, you even have Go links, you should copy it, I think from Google, right? Which like, it's basically, uh, you know, in my mind it's like this is ex Googlers missing Google internal stuff. So they just built it for everyone else. So,
[00:07:25] well, I can, I can comment on that. So a, I should just plug that we have a new website as of today.
[00:07:30] I don't know how, how it's received. So I saw it yesterday, so let, let me know. I think today we just launch, I don't know when we launched a new one, I think today or yesterday. Yeah,
[00:07:38] it's
[00:07:38] new. I opened it right now it's different than yesterday.
[00:07:41] Okay. It's, it's today and yeah. So one thing that we find is that, Search in itself.
[00:07:48] This is actually, I think, quite a big insight. Search in itself is not a compelling enough use case to keep people drawn to your product. It's easy to say Google search is like that, but Google Search was also in an era where that was the only website people knew, and now it's not like that. When you are a new tool that's coming into a company, you can't sit on your high horse and say, yeah, of course you're gonna use my tool to search.
[00:08:13] No, they're not gonna remember who you are. They're gonna use it once and completely forget to really get that retention. You need to sort of go from being just a search engine to exactly what you said, Sean, to being sort of an employee portal that does much more than that. And yeah, the Go Links thing, I, I mean, yes, it is copied from Google.
[00:08:33] I will say there's a complete other startup called Go links.io that has also copied it from Google and, and everyone, everyone misses Go Links. It's very useful to be able to write a document and just be like, go to go slash this. And. That's where the document is. And, and so we have built a big feature set around it.
[00:08:50] I think one of the critical ones that I will call out is the feed. Just being able to see, not just, so documents that are trending in your sub-organization documents that you, we think you should see are a limited set of them, as well as now we've launched something called Mentions, which is super useful, which is all of your tags across all of your apps in one place in the last whatever, you know, time.
[00:09:14] So it's like all of the hundred Slack pings that you have, plus the Jira pings, plus the, the, the email, all of that in one place is super useful to have. So you did GitHub. Yeah, we do get up to, we do get up to all the mentions.
[00:09:28] Oh my God, that's amazing. I didn't know you had it, but, uh, um, this is something I wish for myself.
[00:09:33] It's amazing.
[00:09:34] It's still a little buggy right now, but I think it's pretty good. And, and we're gonna make it a lot better as as we go.
[00:09:39] Why Employee Portals
[00:09:39] This
[00:09:39] is not in our preset list of questions, but I have one follow up, which is, you know, I've worked in quite a few startups now that don't have employee portals, and I've worked at Amazon, which had an employee portal, but it wasn't as beautiful or as smart as as glean.
[00:09:53] Why isn't this a bigger norm in all
[00:09:56] companies? Well, there's several reasons. I would say one reason is just the dynamics of how enterprise sales happens is. I wouldn't say broken. It is, it is what it is, but it doesn't always cater to employees being happy with the best tools. What it does cater to is there's different incentive structures, right?
[00:10:16] So if I'm an IT buyer, I have a budget and I need to understand that for a hundred of these tools that are pitched to me all the time, which ones really help the company And the way usually those things are evaluated is does it increase revenue and does it cut cost? Those are the two biggest ones. And for a software like Glean or a search portal or employee portal, it's actually quite difficult when you're in, generally bucketed in the space of productivity to say, Hey, here's a compelling use use case for why we will cut your cost or increase your revenue.
[00:10:52] It's just a softer argument that you have to make there. It's just a fundamental nature of the problem versus if you say, Hey, we're a customer support tool. Everyone in SaaS knows that customer support tools is just sort of the. The last thing that you go to when you're looking for ideas, because it's easy to sell.
[00:11:08] It's like, here's a metric. How many tickets can your customer support agent resolve? We've built a thing that makes it 20% better. That means it's 1,000 thousand dollars cost savings. Pay us 50 k. Call it a deal. That's a good argument. That's a very simple, easy to understand argument. It's very difficult to make that argument with search, which you're like, okay, you're gonna get see about 10 to 20 searches that's gonna save about this much time, uh, a day.
[00:11:33] And that results in this much employee productivity. People just don't buy it as easily. So the first reaction is, oh, we work fine without it. Why do we need this now? It's not like the company didn't work without this tool, and uh, and only when they have it do they realize what they were missing out on.
[00:11:50] So it's a difficult thing to sell in, in some ways. So even though the product is, in my opinion, fantastic, sometimes the buyer isn't easily convinced because it doesn't increase revenue or cut cost.
[00:12:01] The Requirements of Good Enterprise Search
[00:12:01] In terms of technology, can you maybe talk about some of the stack and you see a lot of companies coming up now saying, oh, we help you do enterprise search.
[00:12:10] And it's usually, you know, embedding to then do context for like a LLM query mostly. I'm guessing you started as like closer to like the vector side of thing maybe. Yeah. Talk a bit about that and some learning siva and as founders try to, to build products like this internally, what should they think
[00:12:27] about?
[00:12:28] Yeah, so actually leading back from the last answer, one of the ways a lot of companies who are in the enterprise search space are trying to tackle the problem of sales is to lean into how advance the technology is, which is useful. It's useful to say we are AI powered, LLM powered vector search, cutting edge, state-of-the-art, yada, yada, yada.
[00:12:47] Put it all your buzzwords. That's nice, but. The question is how often does that translate to better user experience is sort of, a fuzzy area where it, it's really hard for even users to tell, to be honest. Like you can have one or two great queries and one really bad query and be like, I don't know if this thing is smart.
[00:13:06] And it takes time to evaluate and understand how a certain engine is doing. So to that, I think one of the things that we learned from Google, a lot of us come from an ex Google search background, and one of the key learnings is often with search, it's not about how advanced or how complex the technology is, it's about the rigor and intellectual honesty that you put into tuning the ranking algorithm.
[00:13:30] That's a painstaking long-term and slow process at Google until I would say maybe 20 17, 20 18. Everything was run off of almost no real ai, so to speak. It was just information retrieval at its core, very basic from the seventies, eighties, and a bunch of these ranking components that are put stacked on top of it that do various tasks really, really well.
[00:13:57] So one task in search is query understanding what does the query mean? One task is synonymous. What are other synonyms for this thing that we can also match on? One task is document understanding. Is this document itself a high quality document or not? Or is it some sort of SEO spam? And admittedly, Google doesn't do so well on that anymore, but there's so many tough sub problems that it breaks search down into and then just gets each of those problems, right, to create a nice experience.
[00:14:24] So to answer your question, also, vector search we do, but it is not the only way we get results. We do a hybrid approach both using, you know, core IR signal synonymy. Query accentuation with things like acronym expansion, as well as stuff like vector search, which is also useful. And then we apply our level of ranking understanding on top of that, which includes personalization, understanding.
[00:14:50] If you're an engineer, you're probably not looking for Salesforce documents. You know, you're probably looking for documents that are published or co-authored by people in your team, in your immediate team, and our understanding of all of your interactions with people around you. Our personalization layer, our good work on ranking is what makes us.
[00:15:09] Good. It's not sort of, Hey, drop in LLM and embeddings and we become amazing at search. That's not how we think it
[00:15:16] works. Yeah. I think there's a lot of polish that mix into quality products, and that's the difference that you see between Hacker News, demos and, uh, glean, which is, uh, actual, you know, search and chat unicorn.
[00:15:26] Glean Chat?
[00:15:26] But also is there a glean chat coming? Is is, what do you think about the
[00:15:30] chat form factor? I can't say anything about it, but I think that we are experi, my, my politically correct answer is we're experimenting with many technologies that use modern AI and LLMs, and we will launch what we think users like best.
[00:15:49] Nice. You got some media training
[00:15:51] again? Yeah. Very well handed.
[00:15:53] Google vs ChatGPT
[00:15:53] We can, uh, move off of Glean and just go into Google search. Uh, so you worked on search for four years. I've always wanted to ask what happens when I type something into Google? I feel like you know more than others and you obviously there's the things you cannot say, but I'm sure Google does a lot of the things that Glean does as well.
[00:16:08] How do you think about this Google versus ChatGPT debate? Let's, let's maybe start at a high level based on what you see out there, and I think you, you see a lot of
[00:16:15] misconceptions. Yeah. So, okay, let me, let me start with Google versus ChatGPT first. I think it's disingenuous, uh, if I don't say my own usage pattern, which is I almost don't go back to Google for a large section of my queries anymore.
[00:16:29] I just use ChatGPT I am a paying plus subscriber and it's sort of my go-to for a lot of things. That I ask, and I also have to train my mind to realize that, oh, there's a whole set of questions in your head that you never realize the internet could answer for you, and that now you're like, oh, wait, I could actually ask this, and then you ask it.
[00:16:48] So that's my current usage pattern. That being said, I don't think that ChatGPT is the best interface or technology for all sets of queries. I think humans are obviously very easily excited by new technology, but new technology does not always mean the previous technology was worse. The previous technology is actually really good for a lot of things, and for search in particular, if you think about all the queries that come into Google search, they fall into various kinds of query classes, depending on whatever taxonomy you want to use.
[00:17:24] But one sort of way of, of of understanding broad, generally, the query classes is something that is information seeking or exploratory. And for information for exploratory queries. I think there are uses where Google does really well. Like for example, let's say you want to just know a list of songs of this artist in this year.
[00:17:49] Google will probably be able to add a hundred percent, tell you that pretty accurately all the time. Or if you want to say understand like what showtimes of movies came out today. So fresh queries, another query class, Google will be really good at that chat, not so good at that. But if you look at information seeking queries, you could even argue that if I ask for information about Donald Trump, Maybe ChatGPT will spit out a reasonable sounding paragraph and it makes sense, but it doesn't give me enough stuff to like click on and go to and navigate to in a news article here.
[00:18:25] And I just kind wanna see a lot of stuff happening. So if you really break down the problem, I think it's not as easy as saying ChatGPT is a silver bullet for every kind of information need. There's a lot of information needs, especially for tail queries. So for long. Un before seen queries like, Hey, tell me the cheat code in Doom three.
[00:18:43] This level, this boss ChatGPTs gonna blow it out the water on those kind of queries cuz it's gonna figure out all of these from these random sparse documents and random Reddit threads and assemble one consistent answer for you where it takes forever to find this kind of stuff on Google. For me personally, coding is the biggest use case for anything technical.
[00:19:02] I just go to ChatGPT cuz parsing through Stack Overflow is just too mentally taxing and I don't care about, even if ChatGPT hallucinates a wrong answer, I can verify that. But I like seeing a coherent, nice answer that I can just kind of good starting point for my research on whatever I'm trying to understand.
[00:19:20] Did you see the, the statistic that, uh, the Allin guys have been saying, which is, uh, stack overflow traffic is down 15%? Yeah, I did, I did.
[00:19:27] See that
[00:19:28] makes sense. But I, I, I don't know if it's like only because of ChatGPT, but yeah, sure. I believe
[00:19:33] it. No, the second part was just about if some of the enterprise product search moves out of Google, like cannot, that's obviously a big AdWords revenue driver.
[00:19:43] What are like some of the implications in terms of the, the business
[00:19:46] there?
[00:19:47] Search Issues: Freshness
[00:19:47] Okay,
[00:19:47] so I would split this answer into two parts. My first part is just talking about freshness, cuz the query that you mentioned is, is specifically the, the issue there is being able to access fresh information. Google just blanket calls his freshness.
[00:20:01] Today's understanding of large language models is that it cannot do anything that's highly fresh. You just can't train these things fast enough and cost efficiently enough to constantly index new, new. Sources of data and then serve it at the same time in any way that's feasible. That might change in the future, but today it's not possible.
[00:20:20] The best thing that you can get that's close to it is what, you know, the fancy term is retrieval, augmented generation, but it's a fancy way of saying just do the search in the background and then use the results to create the actual response. That's what Bing does today. So to answer the question about freshness, I would say it is possible to do with these methods, but those methods all in all involve using search in the backend to, to sort of get the context to generate the answer.
[00:20:49] Search Issues: Ad Revenue
[00:20:49] The second part of the answer is, okay, talk about ad revenue. A lot of Google's ad revenue just comes from the fact that over the last two decades, it's figured out how to put ad links on top of a search result page that sometimes users click. Now the user behavior on a chat product is not to click on anything.
[00:21:10] You don't click on stuff you just read and you move on. And that actually, in my opinion, has severe impacts on the web ecosystem, on all of Google and all of technology and how we use the internet in the future. And, and the reason is one thing we also take for granted is that this ad revenue where everyone likes to say Google is bad, Google makes money off ads, yada, yada, yada, but this ad revenue kind of sponsored the entire internet.
[00:21:37] So you have Google Maps and Google search and photos and drive and all of this great free stuff basically because of ads. Now, when you have this new interface, sure it, it comes with some benefits, but if users aren't gonna click on ads and you replace the search interface with just chat, that can actually be pretty dangerous in terms of what it even means.
[00:21:59] To have to create a website, like why would I create a website if no one's gonna come to my. If it's just gonna be used to train a model and then someone's gonna spit out whatever my website says, then there's no incentive. And that kind of dwindles the web ecosystem. In the end, it means less ad revenue.
[00:22:15] And then the other existential question is, okay, I'm okay with saying the incumbent. Google gets defeated and there's this new hero, which is, I don't know, open AI and Microsoft. Now reinvent the wheel. All of that stuff is great, but how are they gonna make money? They can make money off, I guess, subscriptions.
[00:22:31] But subscriptions is not nearly gonna make you enough. To replace what you can make on ad revenue. Even for Bing today. Bing makes it 11 billion off ad revenue. It's not a society product like it's a huge product, and they're not gonna make 11 billion off subscriptions, I'll tell you that. So even they can't really replace search with this with chat.
[00:22:51] And then there are some arguments around, okay, what if you start to inject ads in textual form? But you know, in my view, if the natural user inclination is not to click on something or chat, they're clearly not gonna click on something. No matter how much you try to inject, click targets into your result.
[00:23:10] So, That's, that's my long answer to the ads question. I don't really know. I just smell danger in the horizon.
[00:23:17] Search Issues: Latency
[00:23:17] You mentioned the information augmented generation as well. Uh, I presumably that is literally Bing is probably just using the long context of GPT4 and taking the full text of all the links that they find, dumping it in, and then generating some answer.
[00:23:34] Do you think like speed is a concern or people are just people willing to wait for smarter?
[00:23:40] I think it's a concern. We noticed that every, every single product I've worked on, there's almost a linear, at least for some section of it, a very linear curve. A linear line that says the more the latency, the less the engagement, so there's always gonna be some drop off.
[00:23:55] So it is a concern, but with things like latency, I just kind of presume that time solves these things. You optimize stuff, you make things a little better, and the latency will get down with time. And it's a good time to even mention that. Bard, we just came out today. Google's LLM. For Google's equivalent, I haven't tried it, but I've been reading about it, and that's based off a model called LamDA.
[00:24:18] And LamDA intrinsically actually does that. So it does query what they call a tool set and they query search or a calculator or a compiler or a translator. Things that are good at factual, deterministic information. And then it keeps changing its response depending on the feedback from the tool set, effectively doing something very similar to what Bing does.
[00:24:42] Search Issues: Accuracy
[00:24:42] But I like their framing of the problem where it's just not just search, it's any given set of tools. Which is similar to what a Facebook paper called Tool Former, where you can think of language as one aspect of the problem and language interfaces with computation, which is another aspect of the problem.
[00:24:58] And if you can separate those two, this one just talks to these things and figures out what to, how to phrase it. Yeah, so it's not really coming up with the answer. Their claim is like GPT4, for example. The reason it's able to do factual accuracy without search is just by memorizing facts. And that doesn't scale.
[00:25:18] It's literally somewhere in the whole model. It knows that the CEO of Tesla is Elon Musk. It just knows that. But it doesn't know that this is a competition. It just knows that. Usually I see CEO, Tesla, Elon, that's all it knows. So the abstraction of language model to computational unit or tool set is an interesting one that I think is gonna be more explored by all of these engines.
[00:25:40] Um, and the latency, you know, it'll.
[00:25:42] I think you're focusing on the right things there. I actually saw another article this morning about the memorization capability. You know how GPT4 is a lot of, uh, marketed on its ability to answer SAT questions and GRE questions and bar exams and, you know, we covered this in our benchmarks podcast Alessio, but like I forgot to mention that all these answers are out there and were probably memorized.
[00:26:05] And if you change them just, just a little bit, the model performance will probably drop a lot.
[00:26:10] It's true. I think the most compelling, uh, proof of that, of what you just said is the, the code forces one where somebody I think tweeted, tweeted, tweeted about the, yeah, the 2021. Everything before 2021. It solves everything after.
[00:26:22] It doesn't, and I thought that was interesting.
[00:26:24] Search Issues: Tool Use
[00:26:24] It's just, it's just dumb. I'm interested in two former, and I'm interested in react type, uh, patterns. Zapier just launched a natural language integration with LangChain. Are you able to compare contrast, like what approaches you like when it comes to LMS using
[00:26:36] tools?
[00:26:37] I think it's not boiled down to a science enough for me to say anything that's uh, useful. Like I think everyone is at a point of time where they're just playing with it. There's no way to reason about what LLMs can and can't do. And most people are just throwing things at a wall and seeing what sticks.
[00:26:57] And if anyone claims to be doing better, they're probably lying because no one knows how these things behaves. You can't predict what the output is gonna be. You just think, okay, let's see if this works. This is my prompt. And then you measure and you're like, oh, that worked. Versus the stint and things like react and tool, form are really cool.
[00:27:16] But those are just examples of things that people have thrown at a wall that stuck. Well, I mean, it's provably, it works. It works pretty, pretty well. I will say that one of the. It's not really of the framing of what kind of ways can you use LLMs to make it do cool things, but people forget when they're looking at cutting edge stuff is a lot of these LLMs can be used to generate synthetic data to bootstrap smaller models, and it's a less sexy space of it all.
[00:27:44] But I think that stuff is really, really cool. Where, for example, I want to tag entities in a sentence that's a very simple classical natural language problem of NER. And what I do is I just, before I had to gather training data, train model, tune model, all of this other stuff. Now what I can do is I can throw GPT4 at it to generate a ton of synthetic data, which looks actually really good.
[00:28:11] And then I can either just train whatever model I wanted to train before on this data, or I can use something called like low rank adaptation, which is distilling this large model into a much smaller, cost effective, fast model that does that task really well. And in terms of productionable natural language systems, that is amazing that this is stuff you couldn't do before.
[00:28:35] You would have teams working for years to solve NER and that's just what that team does. And there's a great red and viral thread about our, all the NLP teams at Big Tech, doomed and yeah, I mean, to an extent now you can do this stuff in weeks, which is
[00:28:51] huge.
[00:28:52] Other AI Search takes: Perplexity and Neeva
[00:28:52] What about some of the other kind of like, uh, AI native search, things like perplexity, elicit, have you played with, with any of them?
[00:29:00] Any thoughts on
[00:29:01] it? Yeah. I have played with perplexity and, and niva. Everyone. I think both of those products sort of try to do, again, search results, synthesis. Personally, I think Perplexity might be doing something else now, but I don't see the, any of those. Companies or products are disrupting either open AI or ChatGPT or Google being whatever prominent search engines with what they do, because they're all built off basically the Bing API or their own version of an index and their search itself is not good enough and there's not a compelling use case enough, I think, to use those products.
[00:29:40] I don't know how they would make money, a lot of Neeva's way of making money as subscriptions. Perplexity I don't think has ever turned on the revenue dial. I just have more existential concerns about those products actually functioning in the long run. So, um, I think I see them as they're, they're nice, they're nice to play with.
[00:29:56] It's cool to see the cutting edge innovation, but I don't really understand if they will be long lasting widely used products.
[00:30:05] Why Document QA will Struggle
[00:30:05] Do you have any idea of what it might take to actually do like a new kind of like, type of company in this space? Like Google's big thing was like page rank, right? That was like one thing that kind of set them apart.
[00:30:17] Like people tried doing search before, like. Do you have an intuition for what, like the LM native page rank thing is gonna be to make something like this exist? Or have we kinda, you know, hit the plateau when it comes to search innovation?
[00:30:31] So I, I talk to so many of my friends who are obviously excited about this technology as well, and many of them who are starting LLM companies.
[00:30:38] You know, how many companies in the YC batch of, you know, winter 23 are LM companies? Crazy half of them. Right? Right. It's, it's ridiculous. But what I always, I think everyone's struggling with this problem is what is your advantage? What is your moat? I don't see it for a lot of these companies, and, uh, it's unclear.
[00:30:58] I, I don't have a strong intuition. My sense is that the people who focus on problem first usually get much further than the people who focus solution first. And there's way too many companies that are solutions first. Which makes sense. It's always been the, a big achilles heel of the Silicon Valley.
[00:31:16] We're a bunch of nerds that live in a whole different dimension, which nobody else can relate to, but nobody else. The problem is nobody else can relate to them and we can't relate to their problems either. So we look at tech first, not problem first a lot. And I see a lot of companies just, just do that.
[00:31:32] Where I'll tell you one, this is quite entertaining to me. A very common theme is, Hey, LMS are cool, that, that's awesome. We should build something. Well, what should we build? And it's like, okay, consumer, consumer is cool, we should build consumer. Then it's like, ah, nah man. Consumers, consumer's pretty hard.
[00:31:49] Uh, it's gonna be a clubhouse gonna blow up. I don't wanna blow up, I just wanna build something that's like, you know, pretty easy to be consistent with. We should go enter. Cool. Let's go enterprise. So you go enterprise. It's like, okay, we brought LMS to the enterprise. Now what problem do we tackle? And it's like, okay, well we can do q and A on documents.
[00:32:06] People know how to do that, right? We've seen a couple of demos on that. So they build it, they build q and a on documents, and then they struggle with selling, or they're like, or people just ask, Hey, but I don't ask questions to my documents. Like, you realize this is just not a flow that I do, like I, oh no.
[00:32:22] I ask questions in general, but I don't ask them to my documents. And also like what documents can you ask questions to? And they'll be like, well, any of them is, they'll say, can I ask them to all of my documents? And they'll be like, well, sure, if you give them, give us all your documents, you can ask anything.
[00:32:39] And then they'll say, okay, how will you take all my document? Oh, it seems like we have to build some sort of indexing mechanism and then from one thing to the other, you get to a point where it's like we're building enterprise search and we're building an LM on top of it, and that is our product. Or you go to like ML ops and I'm gonna help you host models, I'm gonna help you train models.
[00:33:00] And I don't know, it's, it seems very solution first and not problem first. So the only thing I would recommend is if you think about the actual problems and talk to users and understand what this can be useful for. It doesn't have to be that sexy of how it's used, but if it works and solves the problem, you've done your job.
[00:33:18] Investing in AI Startups
[00:33:18] I love that whole evolution because I think quite a few companies ha are, independently finding this path and, going down this route to build a glorified, you know, search spot. We actually interviewed a very problem focused builder, Mickey Friedman, who's very, very focused on products placement, image generation.
[00:33:34] , and, you know, she's not focused on anything else in terms of image generation, like just focused on product placement and branding. And I think that's probably the right approach, you know, and, and if you think about like Jasper, right? Like they, they're out of all the other GPT3 companies when, when GPT3 first came out, they built focusing on, you know, writers on Facebook, you know, didn't even market on Twitter.
[00:33:56] So like most people haven't heard of them. Uh, I think it's a timeless startup lesson, but it's something to remind people when they're building with, uh, language models. I mean, as a, as an investor like you, you know, you are an investor, you're your scout with me. Doesn't that make it hard to invest in anything like, cuz.
[00:34:10] Mostly it's just like the incumbents will get to the innovation faster than startups will find traction.
[00:34:16] Really. Like, oh, this is gonna be a hot take too. But, okay. My, my in, in investing, uh, with people, especially early, is often for me governed by my intuition of how they approach the problem and their experience with the technology, and pretty much solely that I don.
[00:34:37] Really pretend to be an expert in the industry or the space that's their problem. If I think they're smart and they understand the space better than me, then I mostly convinced as if they've thought through enough of the business stuff, if they've thought through the, the market and everything else. I'm convinced I typically stray away from, you know, just what I just said.
[00:34:57] Founders who are like LMS are cool and we should build something with them. That's not like usually very convincing to me. That's not a thesis. But I don't concern myself too much with pretending to understand what this space means. I trust them to do that. If I'm convinced that they're smart and they've thought about it, well then I'm pretty convinced that that they're a good person to, to, to
[00:35:20] back.
[00:35:21] Cool.
[00:35:21] Actually Interesting Ideas in AI
[00:35:21] Kinda like super novel idea that you wanna shout.
[00:35:25] There's a lot of interesting explorations, uh, going on. Um, I, I, okay, I'll, I'll preface this with I, anything in enterprise I just don't think is cool. It's like including, like, it's just, it's, you can't call it cool, man. You're building products for businesses.
[00:35:37] Glean is pretty cool. I'm impressed by Glean. This is what I'm saying. It's, it's cool for the Silicon Valley. It's not cool. Like, you're not gonna go to a dinner party with your parents and be like, Hey mom, I work on enterprise search. Isn't that awesome? And they're not all my, all my
[00:35:51] notifications in one place.
[00:35:52] Whoa.
[00:35:55] So I will, I'll, I'll start by saying, for in my head, cool means like, the world finds this amazing and, and it has to be somewhat consumer. And I do think that. The ideas that are being played with, like Quora is playing with Poe. It's kind of strange to think about, and may not stick as is, but I like that they're approaching it with a very different framing, which is, Hey, how about you talk to this, this chat bot, but let's move out of this, this world where everyone's like, it's not WhatsApp or Telegram, it's not a messaging app.
[00:36:30] You are actually generating some piece of content that now everybody can make you use of. And is there something there Not clear yet, but it's an interesting idea. I can see that being something where, you know, people just learn. Or see cool things that GPT4 has said or chatbots have said that's interesting in the image space.
[00:36:49] Very contrasted to the language space. There's so much like I don't even begin to understand the image space. Everything I see is just like blows my mind. I don't know how mid journey gets from six fingers to five fingers. I don't understand this. It's amazing. I love it. I don't understand what the value is in terms of revenue.
[00:37:08] I don't know where the markets are in, in image, but I do think that's way, way cooler because that's a demo where, and I, and I tried this, I showed GPT4 to, to my mom and my mom's like, yeah, this is pretty cool. It does some pretty interesting stuff. And then I showed the image one and she is just like, this is unbelievable.
[00:37:28] There's no way a computer could write do this, and she just could not digest it. And I love when you see those interactions. So I do think image world is a whole different beast. Um, and, and in terms of coolness, lot more cool stuff happening in image video multimodal I think is really, really cool. So I haven't seen too many startups that are doing something where I'm like, wow, that's, that's amazing.
[00:37:51] Oh, 11 labs. I'll, I'll mention 11 labs is pretty cool. They're the only ones that I know that are doing Oh, the voice synthesis. Have you tried it? I've only played with it. I haven't really tried generating my own voice, but I've seen some examples and it looks really, really awesome. I've heard
[00:38:06] that Descript is coming up with some stuff as well to compete, cuz yeah, this is definitely the next frontier in terms of, podcasting.
[00:38:13] Harry Potter IRL
[00:38:13] One last thing I I will say on the cool front is I think there is something to be said about. A product that brings together all these disparate advancements in ai. And I have a view on what that looks like. I don't know if everyone shares that view, but if you bring together image generation, voice recognition, language modeling, tts, and like all of the other image stuff they can do with like clip and Dream booth and putting someone's actual face in it.
[00:38:41] What you can actually make, this is my view of it, is the Harry Potter picture come to life where you actually have just a digital stand where there's a person who's just capable of talking to you in their voice, in, you know, understandable dialogue. That is how they speak. And you could just sort of walk by, they'll look at you, you can say hi, they'll be, they'll say hi back.
[00:39:03] They'll start talking to you. You start talking back to it. That's sort of my, that's my my wild science fiction dream. And I think the technology exists to put all of those pieces together and. The implications for people who are older or saving people over time are huge. This could be a really cool thing to productionize.
[00:39:23] AI Infra Cost Math
[00:39:23] There's one more part of you that also tweets about numbers and math, uh, AI math essentially is how I'm thinking about it. What gets you into talking about costs and math and, and you know, just like first principles of how to think about language models.
[00:39:39] One of my biggest beefs with big companies is how they abstract the cost away from all the engineers.
[00:39:46] So when you're working on a Google search, I can't tell you a single number that is cost related at all. Like I just don't know the cost numbers. It's so far down the chain that I have no clue how much it actually costs to run search, and how much these various things cost aside from what the public knows.
[00:40:03] And I found that very annoying because when you are building a startup, particularly maybe an enterprise startup, you have to be extremely cognizant about the cost because that's your unit economics. Like your primary cost is the money you spend on infrastructure, not your actual labor costs. The whole thesis is the labor doesn't scale, but the inf.
[00:40:21] Does scale. So you need to understand how your infra costs scale. So when it comes to language models, given that these things are so compute heavy, but none of the papers talk about cost either. And it's just bothers me. I'm like, why can't you just tell me how much it costs you to, to build this thing?
[00:40:39] It's not that hard to say. And it's also not that hard to figure out. They give you everything else, which is, you know, how many TPUs it took and how long they trained it for and all of that other stuff, but they don't tell you the cost. So I've always been curious because ev all everybody ever says is it's expensive and a startup can't do it, and an individual can't do it.
[00:41:01] So then the natural question is, okay, how expensive is it? And that's sort of the, the, the background behind. Why I started doing some more AI math and, and one of the tweets that probably the one that you're talking about is where I compare the cost of LlaMA, which is Facebook's LLM, to PaLM with, uh, my best estimates.
[00:41:23] And, uh, the only thing I'll add to that is it is quite tricky to even talk about these things publicly because you get rammed in the comments because by people who are like, oh, don't you know that this assumption that you made is completely BS because you should have taken this cost per hour? Because obviously people do bulk deals.
[00:41:42] And yeah, I have two 80 characters. This is what I could have said. But I think ballpark, I think I got close. I, I'd like to imagine, I think I was off maybe by, by by two x on the lower side. I think I took an upper bound and I might have been off by, by two x. So my quote was 4 million for LlaMA and 27 for PaLM.
[00:42:01] In fact, later today I'm going to do, uh, one on Bard. So. Oh oh one bar. Oh, the exclusive is that It's four, it's 4 million for Bard two.
[00:42:10] Nice. Nice. Which is like, do you think that's like, don't you think that's actually not a lot, like it's a drop in the bucket for these
[00:42:17] guys. One, and one of the, the valuable things to note when you're talking about this cost is this is the cost of the final training step.
[00:42:24] It's not the cost of the entire process. And a common rebuttal is, well, yeah, this is your cost of the final training process, but in total it's about 10 x this amount cost. Because you have to experiment. You have to tune hyper parameters, you have to understand different architectures, you have to experiment with different kinds of training data.
[00:42:43] And sometimes you just screw it up and you don't know why. And you have, you're just spend a lot of time figuring out why you screwed it up. And that's where the actual cost buildup happens, not in the one final last step where you actually train the final model. So even assuming like a 10 x on top of this, I think is, is, is fair for how much it would actually cost a startup to build this from scratch?
[00:43:03] I would say.
[00:43:04] Open Source LLMs
[00:43:04] How do you think about open source in this then? I think a lot of people's big 2023 predictions are an LLM, you know, open source LLM, that is comparable performance to the GPT3 model. Who foots the bill for the mistakes? You know, like when when somebody opens support request that it's not good.
[00:43:25] It doesn't really cost people much outside of like a GitHub actions run as people try entering these things separately. Like do you think open source is actually bad because you're wasting so much compute by so many people trying to like do their own things and like, do you think it's better to have a centralized team that organizes these experiments or Yeah.
[00:43:43] Any thoughts there? I have some thoughts. I. The most easy comparison to make is to image generation world where, you know, you had Mid Journey and Dolly come out first, and then you had Imad come out with stability, which was completely open source. But the difference there is I think stability. You can pretty much run on your machine and it's okay.
[00:44:06] It works pretty fast. So it, so the entire concept of, of open sourcing, it worked and people made forks that fine tuned it on a bunch of different random things and it made variance of stability that could. A bunch of things. So I thought the stability thing, agnostic of the general ethical concerns of training on everyone's art.
[00:44:25] I thought it was a cool, cool addition to the sort of trade-offs in different models that you can have in image generation for text generation. We're seeing an equivalent effect with LlaMA and alpaca, which LlaMA being, being Facebook's model, which they didn't really open source, but then the weights got leaked and then people clone them and then they tuned them using GPT4 generated synthetic data and made alpaca.
[00:44:50] So the version I think that's out there is only the 7,000,000,001 and then this crazy European c plus plus God. Came and said, you know what, I'm gonna write this entire thing in c plus plus so you can actually run it locally and and not have to buy GPUs. And a combination of those. And of course a lot of people have done work in optimizing these things to make it actually function quickly.
[00:45:13] And we can get into details there, but a function of all of these things has enabled people to actually. Semi-good models on their computer. I don't have that much, I don't have any comments on, you know, energy usage and all of that. I don't really have an opinion on that. I think the fact that you can run a local version of this is just really, really cool, but also supremely dangerous because with images, conceivably, people can tell what's fake and what's real, even though there, there's some concerns there as well. But for text it's, you know, like you can do a lot of really bad things with your own, you know, text generation algorithm. You know, if I wanted to make somebody's life hell, I could spam them in the most insidious ways with all sorts of different kinds of text generation indefinitely, which I, I can't really do with images.
[00:46:02] I don't know. I find it somewhat ethically problematic in terms of the power is too much for an individual to wield. But there are some libertarians who are like, yeah, why should only open AI have this power? I want this power too. So there's merits to both sides of the argument. I think it's generally good for the ecosystem.
[00:46:20] Generally, it will get faster and the latency will get better and the models may not ever reach the size of the cutting edge that's possible, but it could be good enough to do. 80% of the things that bigger model could do. And I think that's a really good start for innovation. I mean, you could just have people come up with stuff instead of companies, and that always unlocks a whole vector of innovation that didn't previously exist.
[00:46:45] Other Modalities
[00:46:45] That was a really good, conclusion. I, I, I want to ask follow up questions, but also, that was a really good place to end it. Was there any other AI topics that you wanted to
[00:46:52] touch on? I think Runway ML is the one company I didn't mention and that, that one's, uh, one to look out for.
[00:46:58] I think doing really cool stuff in terms of video editing with generative techniques. So people often talk about the open AI and the Googles of the world and philanthropic and clo and cohere and big journey, all the image stuff. But I think the places that people aren't paying enough attention to that will get a lot more love in the next couple of years.
[00:47:19] Better whisper, so better streaming voice recognition, better t t s. So some open source version of 11 labs that people can start using. And then the frontier is sort of multi-modality and videos. Can you do anything with videos? Can you edit videos? Can you stitch things together into videos from images, all sorts of different cool stuff.
[00:47:40] And then there's sort of the long tail of companies like Luma that are working on like 3D modeling with generative use cases and taking an image and creating a 3D model from nothing. And uh, that's pretty cool too, although the practical use cases to me are a little less clear. Uh, so that's kind of covers the entire space in my head at least.
[00:48:00] I
[00:48:00] like using the Harry Potter image, like the moving and speaking images as a end goal. I think that's something that consumers can really get behind as well. That's super cool.
[00:48:09] Exam Fraud and Generated Text Detection
[00:48:09] To double back a little bit before we go into the lining round, I have one more thing, which is, relevant to your personal story, but then also relevant to our debate, which is a nice blend.
[00:48:18] You're concerned about the safety of everyone having access to language models and you know, the potential harm that you can do there. My guess is that you're also not that positive on watermarking. Techniques from internal languages, right? Like maybe randomly sprinkling weird characters so that people can see like that this is generated by an AI model, but also like you have some personal experience with this because you found manipulation in the Indian Exam Board, which, uh, maybe you might be a similar story.
[00:48:48] I, I don't know if you like, have any thoughts about just watermarking manipulation, like, you know, ethical deployments of, of, uh,
[00:48:55] generated data.
[00:48:57] Well, I think those two things are a little separate. Okay. One I would say is for watermarking text data. There is a couple of different approaches. I think there is actual value to that because from a pure technical perspective, you don't want models to train on stuff they've generated.
[00:49:13] That's kind of bad for models. Yes. And two is obviously you don't want people to keep using Chatt p t for i, I don't know if you want this to use it for all their assignments and never be caught. Maybe you don't. Maybe you don't. But it, it seems like it's valuable to at least understand that this is a machine generated text versus not just ethically that seems, seems like something that should exist.
[00:49:33] So I do think watermarking is, is. A good direction of research and it's, and I'm fairly positive on it. I actually do think people should standardize how that water marketing works across language models so that everyone can detect and understand language models and not just, OpenAI does its own models, but not the other ones and, and so on.
[00:49:51] So that's my view on that. And then, and sort of transitioning into the exam data, this is really old one, but it's one of my favorite things to talk about is I. In America, as you know. Usually the way it works is you give your, you, you take your s a t exam, uh, you take a couple of aps, you do your school grades, you apply to colleges, you do a bunch of fluff.
[00:50:10] You try to prove how you're good at everything. And then you, you apply to colleges and then it's a, a weird decision based on a hundred other factors. And then they decide whether you get in or not. But if you're rich, you're basically gonna get in anyway. And if you're a legacy, you're probably gonna get in and there's a whole bunch of stuff going on.
[00:50:23] And I don't think the system is necessarily bad, but it's just really complicated. And some of the things are weird in India and in a lot of the non developed world, people are like, yeah, okay, we can't scale that. There's no way we can have enough people like. Non rigorously evaluate this cuz there's gonna be too much corruption and it's gonna be terrible at the end cuz people are just gonna pay their way in.
[00:50:45] So usually it works in a very simple way where you take an exam that is standardized and sometimes you have many exams, sometimes you have an exam for a different subject. Sometimes it's just one for everything. And you get ranked on that exam and depending on your rank you get to choose the quality and the kind of thing you want to study.
[00:51:03] Which this, the kind of thing always surprises people in America where it's not like, oh it's glory land, where you walk in and you're like, I think this is interesting and I wanna study this. Like, no, in the most of the world it's like you're not smart enough to study this, so you're probably not gonna study it.
[00:51:18] And there's like a rank order of things that you need to be smart enough to do. So it's, it's different. And therefore these exams. Much more critical for the functioning of the system. So when there's fraud, it's not like a small part of your application going wrong, it's your entire application going wrong.
[00:51:36] And that's why, that's just me explaining why this is severe. Now, one such exam is the one that you take in school. There's a, it's called a board exam. You take one in the 10th grade, which doesn't really matter for much, but, and then you take one in the 12th grade when you're about to graduate and that.
[00:51:53] How you, where you go to college for a large set of colleges, not all, but a large set of colleges, and based on how much you get on your top five average, you're sort of slotted into a different stream in a d in a, in a different college. And over time, because of the competition between two of the boards that are a duopoly, there's no standardization.
[00:52:13] So everyone's trying to like, give more marks than the, the, the other person to attract more students into their board because oh, that means that you can then claim, oh, you're gonna get into a better college if you take our exam and don't go to a school that administers the other exam. What? So it's, and that's, that's the, everyone knew that was happening ish, but there was no data to back it.
[00:52:34] But when you actually take this exam as I did, you start realizing that the numbers, the marks make no sense because you're looking at. Kid who's also in your class and you're like, dude, this guy's not smart. How did he get a 90 in English? He's not good at English. Like, you can't speak it. You cannot give him a 90.
[00:52:54] You gave me a 90. How did this guy get a 90? So everyone has like their anecdotal, this doesn't make any sense me, uh, moments with, with this exam, but no one has access to the data. So way back when, what I did was I realized they have very little security surrounding the data where the only thing that you need to put in to get access is your role number.
[00:53:15] And so as long as you predict the right set of role numbers, you can get everybody's results. So unlike America, also exam results aren't treated with a level of privacy. In India, it's very common to sort of the entire class's results on a bulletin board. And you just see how everyone did and you shamed the people who are stupid.
[00:53:32] That's just how it works. It's changed over time, but that's fundamentally a cultural difference. And so when I scraped all these results and I published it, and I, and I did some analysis, what I found was, A couple of very insidious things. One is that in, if you plot the distribution of marks, you generally tend to see some sort of skewed, but pseudo normal distribution where it's a big peak and a, and it falls off on both ends, but you see two interesting patterns.
[00:54:01] One that is just the most obvious one, which is Grace Marks, which is the pass grade is 33. You don't see nobody got between 29 and 32 because what they did for every single exam is they just made you pass. They just rounded up to 33, which is okay. I'm not that concerned about whether you give Grace Marks.
[00:54:21] It's kind of messed up that you do that, but okay, fine. You want to pass a bunch of people who deserve to fail, do it. Then the other more concerning thing was between 33 and 93, right? That's about 60 numbers, 61 numbers, 30 of those numbers were just missing, as in nobody got 91 on this exam. In any subject in any year.
[00:54:44] How, how does that happen? You, you don't get a 91, you don't get a 93, 89, 87, 85, 84. Some numbers were just missing. And at first when I saw this, I'm like, this is definitely some bug in my code. There's no way that, like, there's 91 never happened. And so I started, I remember I asked a bunch of my friends, I'm like, dude, did you ever get a 9 81 in anything?
[00:55:06] And they're like, no. And it just unraveled that this is obviously problematic cuz that means that they're screwing with your final marks in some way or the other. Yeah. And, and they're not transparent about how they do it. Then I did, I did the same thing for the other board. We found something similar there, but not, not, not the same.
[00:55:24] The problem there was, there was a huge spike at 95 and then I realized what they were doing is they'd offer various exams and to standardize, they would blanket add like a, a, a, a raw number. So if you took the harder math exam, everyone would get plus 10. Arbitrarily, no one. This is not revealed or publicized.
[00:55:41] It's randomly, that was the harder exam you guys all get plus 10, but it's capped at 95. That's just this stupid way to standardize. It doesn't make any sense. Ah, um, they're not transparent about it. And it affects your entire life because yeah, this is what gets you into college. And yeah, if you add the two exams up, this is 1.1 million kids taking it every year.
[00:56:02] So that's a lot of people's lives that you're screwing with by not understanding numbers and, and not being transparent about how you're manipulating them. So that was the thesis in my view, looking back on it, 10 years later, it's been 10 years at this point. I think the media never did justice to it because to be honest, nobody understands statistics.
[00:56:23] So over time it became a big issue then. And then there was a big Supreme court or high court ruling, which said, Hey, you guys can't do this, but there's no transparency. So there's no way of actually ensuring that they're not doing it. They just added a, a level of password protection, so now I can't scrape it anymore.
[00:56:40] And, uh, they probably do the same thing and it's probably still as bad, but people aren't. Raising an issue about it. It's really hard to make this people understand the significance of it because people are so compelled to just go lean into the narrative of exams are bullshit and we should never trust exams, and this is why it's okay to be dumb.
[00:56:59] And it's not, that's not the point, like the point. So, I, I think the, the response was lackluster in retrospect, but that's, that's what I unveiled in 2013. That's fascinating.
[00:57:09] You know, in my finance background, uh, the similar case happens with the Madoff funds because if you plot the, the statistical distribution of the, the Madoff funds, you could see that they were just not a normal distribution, and therefore they would, they would probably made up numbers.
[00:57:25] And, uh, we also did the same thing in my first job as a, as a regulator in Singapore for, for hedge funds returns. Wow. Which is watermarking. It's this, this is a watermark of a human or, uh, some kind of system. Uh, you know, making it up. And statistically, if you look at the distribution, you can see like this, this violates any reasonable assumption.
[00:57:41] Therefore, something's.
[00:57:42] Wrong. Well, I see, I see what you mean there. Like in that sense. Yes. That's really cool that you worked on a very similar problem, and I agree that it's messed up. It's a good way to catch liars in
[00:57:53] Madoff's case. Like they actually made it a big deal, but I don't know, like I don't see how this was a big, wasn't a bigger deal in India.
[00:57:58] But anyway, uh, that's a conversation for another, uh, over drinks perhaps.
[00:58:01] Lightning Round
[00:58:01] But, so now we're gonna go into the lightning round. Just to cut things off with a, uh, overview. What are your favorite AI people and communities? You mentioned Reddits. Let's be specific about which, uh,
[00:58:12] I actually don't really use Reddit that much for, uh, AI stuff.
[00:58:16] It was just one, a one-off example. Most of my learnings are Twitter, and I think there are the obvious ones, like everyone follows Riley Goodside now and there's a bunch of like the really famous ones. But I think amongst the lesser known ones, there are, let me say just my favorite one is probably AI Pub because it does a roundup of everybody else's stuff regularly.
[00:58:40] I know Brian who runs AI Pub as well, and I just think I find it really useful cuz often it's very hard to catch up on stuff and this gives you the entire roundup of last two weeks, here's what happened in ai.
[00:58:51] Good, good, good. Uh, and any other communities like Slack communities, the scores? You don't
[00:58:55] do that stuff?
[00:58:56] I try to, but I, I don't because it's too time consuming. I prefer reading at my own pace.
[00:59:02] Yeah, yeah, yeah. Okay. So, so my, my learning is, uh, start a Twitter like, uh, weekly recap of here's what happened in ai. I mean, it makes sense, right? Like it'll do very well. It was you
[00:59:11] very well a year from now. What do you think people will be the most surprised
[00:59:15] by in ai?
[00:59:17] I think they're gonna be surprised at how much cheaper they're able to bring out, down the cost to, and how much faster that these models get. I'm more optimistic about cost and latency more than I am about just quality improvements at this point. I think modalities will change, but I think quality is near about like a, a maxima that we're gonna achieve.
[00:59:42] So this is a request for startups or a request for site projects. What's an AI thing that you would pay for? Is somebody else built
[00:59:47] it aside from the Harry Potter image one, which I would definitely, I would pay a lot of money to have like a floating, I don't know, bill Clinton in my room, just saying things back to me whenever I talk to it.
[00:59:59] That would be cool. But in terms of other products, uh, if somebody built. A product that would smartly, I know many people have tried to build things like this that would smartly auto respond to things that it can auto respond to. And for the things that are actually important, please don't auto respond and just tell me to do it.
[01:00:19] And that distinction, I think is really important. So somewhere in between the automate everything and the just suggest everything hybrid that works well, I think that would be really cool. Yeah. I've thought
[01:00:30] about this as well. Even if it doesn't respond for you, it can draft an answer for you to edit.
[01:00:35] Right. Uh, so that you, you at least get to review.
[01:00:37] I actually built that this morning. If you guys want it. Ooh. You just, oh, with Gmail and then it pre-draft every email in your inbox. Really? But, uh, yeah, you have to change the prompt because my prompt says like, you. Software engineer. I'm a venture capitalist, this is where it works, blah, blah, blah, blah.
[01:00:55] But you can modify that and then it, it works. It works. Are you
[01:00:58] gonna open source it?
[01:01:00] I, I probably will, but it sometimes it's like it cares too much about the prompt. So for example, in the prompt, I was like, if the person is asking about scheduling, suggest the time and public like the calendar, my calendar or give this calendar link in every email.
[01:01:15] It will respond. And if you ever wanna chat, here's my calendar. Like no matter what the email was, every email, it would tell them to schedule time. So there's still work to
[01:01:24] be done. You're just very helpful. You're just very, very helpful. Well, so actually I have a GitHub version of this, which I actually would pay someone to build, which is read somebody who opened a GitHub issue, like, and, and check if they have missed anything for resolutions.
[01:01:38] And then generate response to like request for resolution. And then like me, you know, if, if they haven't answered in like 30 days, close the issue.
[01:01:45] Absolutely. And, and one thing I'll add to that is also the idea of the ai, just going in and making PRS for you, I think is super compelling that it just says, Hey, I found all these vulnerabilities, uh, patch man.
[01:01:58] Yeah, yeah. We, we got a cell company doing it, so Hello. Yeah, I'll let you know more. Deedee, thank you so much for coming on. I think to wrap it up, um, is there any parting thoughts, kind of like one thing that you want everyone to take away about AI and the impact this kind of have?
[01:02:14] Yeah, I think my, my parting thought is I have always been a big fan of people of bridging the gap between research and the end consumer.
[01:02:24] And I think this is just a great time to be alive where. If you are interested in AI or if you're even remotely interested, of course you can go build stuff. Of course you can read about it. But I think it's so cool that you sh you can just go read the paper and read the raw things that people did to make this happen.
[01:02:42] And I really encourage people to go and read research, follow people on YouTube who are explaining this. Andre Kapai has a great channel where he also explains it. It's just a great time to learn in this space and I would really encourage more people to go and and read the actual stuff. It's really cool.
[01:03:01] Thank you
[01:03:01] so much, Didi, for coming on. It was a great chat. Um, where can people follow you on Twitter? Any other thing you wanna
[01:03:08] plug? I think Twitter is fine. And there's a link to my website from my Twitter too. It's my first name, debark underscore das is my Twitter and dego.com is my website. But you can also just Google DB das and you will find both of those links.
[01:03:25] Awesome. All right. Thank you so much.
[01:03:27] Thank you. Thanks guys.


Share this post