


Sponsorships and applications for the AI Engineer Summit in NYC are live! (Speaker CFPs have closed) If you are building AI agents or leading teams of AI Engineers, this will be the single highest-signal conference of the year for you.
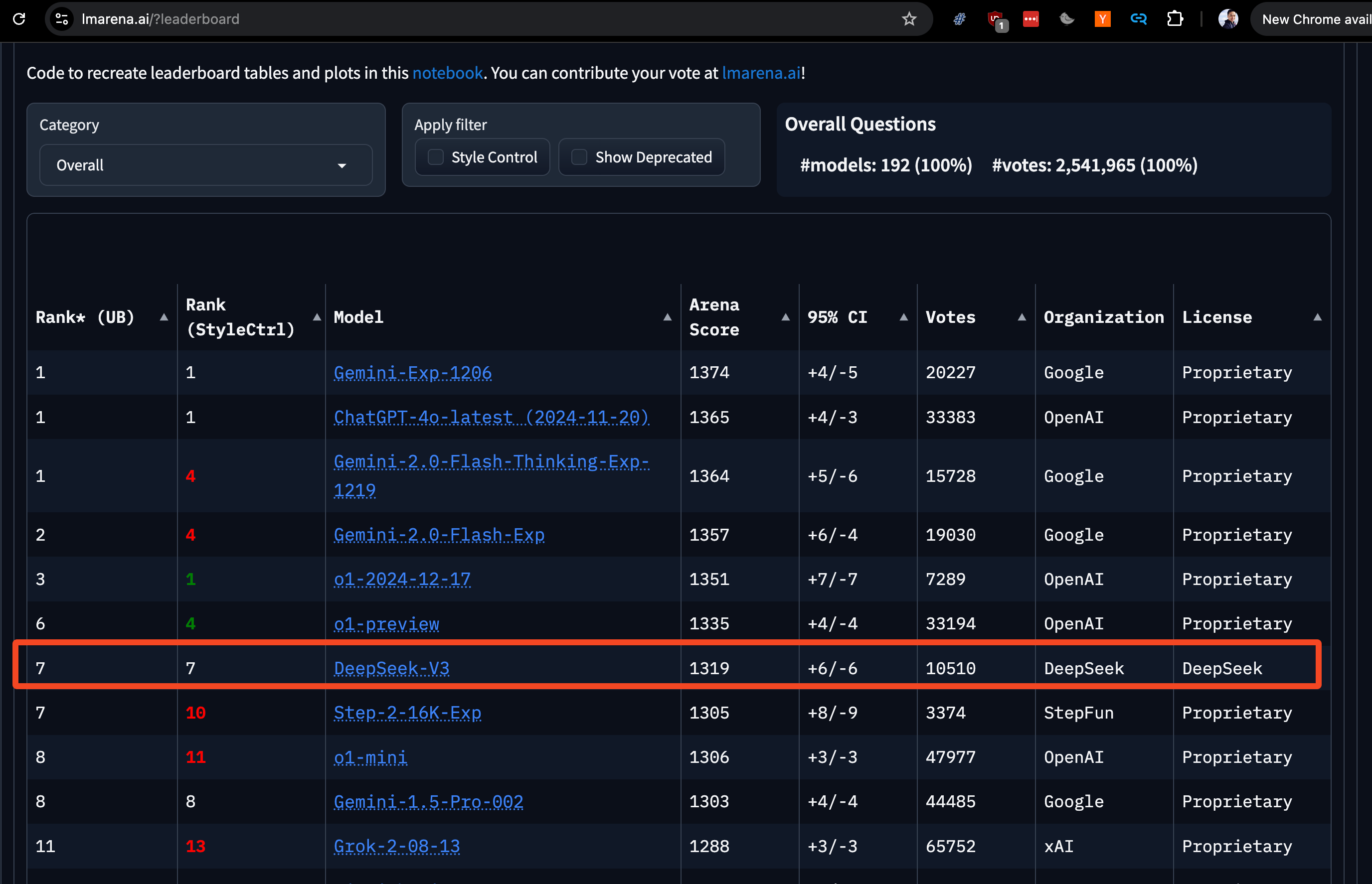
Right after Christmas, the Chinese Whale Bros ended 2024 by dropping the last big model launch of the year: DeepSeek v3. Right now on LM Arena, DeepSeek v3 has a score of 1319, right under the full o1 model, Gemini 2, and 4o latest. This makes it the best open weights model in the world in January 2025.
There has been a big recent trend in Chinese labs releasing very large open weights models, with TenCent releasing Hunyuan-Large in November and Hailuo releasing MiniMax-Text this week, both over 400B in size. However these extra-large language models are very difficult to serve.
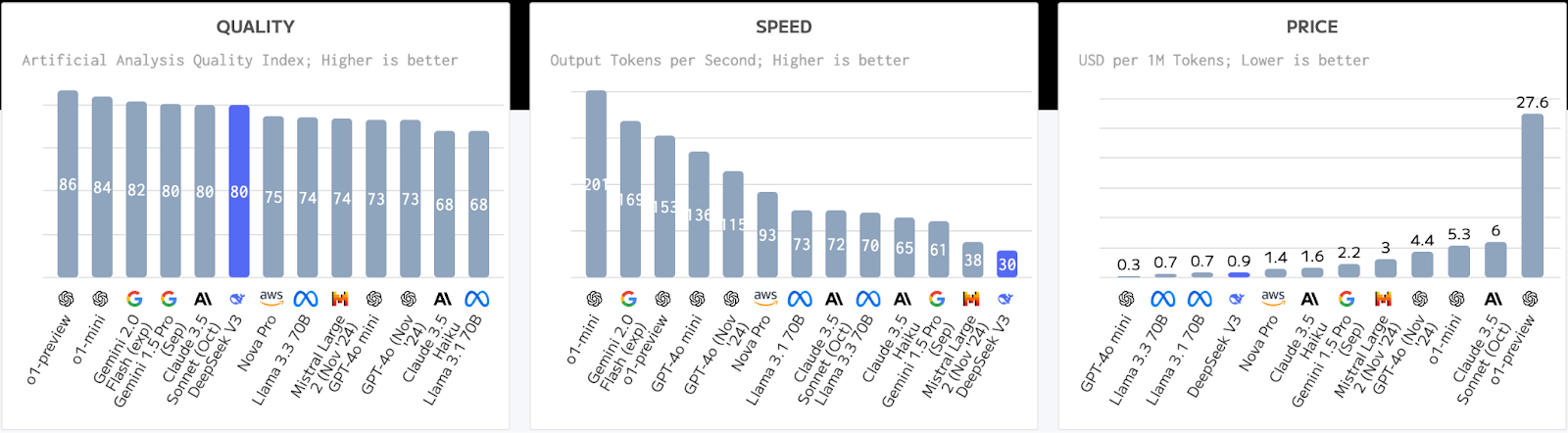
Baseten was the first of the Inference neocloud startups to get DeepSeek V3 online, because of their H200 clusters, their close collaboration with the DeepSeek team and early support of SGLang, a relatively new VLLM alternative that is also used at frontier labs like X.ai. Each H200 has 141 GB of VRAM with 4.8 TB per second of bandwidth, meaning that you can use 8 H200's in a node to inference DeepSeek v3 in FP8, taking into account KV Cache needs.
We have been close to Baseten since Sarah Guo introduced Amir Haghighat to swyx, and they supported the very first Latent Space Demo Day in San Francisco, which was effectively the trial run for swyx and Alessio to work together!

Since then, Philip Kiely also led a well attended workshop on TensorRT LLM at the 2024 World's Fair.
We worked with him to get two of their best representatives, Amir and Lead Model Performance Engineer Yineng Zhang, to discuss DeepSeek, SGLang, and everything they have learned running Mission Critical Inference workloads at scale for some of the largest AI products in the world.
The Three Pillars of Mission Critical Inference
We initially planned to focus the conversation on SGLang, but Amir and Yineng were quick to correct us that the choice of inference framework is only the simplest, first choice of 3 things you need for production inference at scale:
“I think it takes three things, and each of them individually is necessary but not sufficient:
Performance at the model level: how fast are you running this one model running on a single GPU, let's say. The framework that you use there can, can matter. The techniques that you use there can matter. The MLA technique, for example, that Yineng mentioned, or the CUDA kernels that are being used. But there's also techniques being used at a higher level, things like speculative decoding with draft models or with Medusa heads. And these are implemented in the different frameworks, or you can even implement it yourself, but they're not necessarily tied to a single framework. But using speculative decoding gets you massive upside when it comes to being able to handle high throughput. But that's not enough. Invariably, that one model running on a single GPU, let's say, is going to get too much traffic that it cannot handle.
Horizontal scaling at the cluster/region level: And at that point, you need to horizontally scale it. That's not an ML problem. That's not a PyTorch problem. That's an infrastructure problem. How quickly do you go from, a single replica of that model to 5, to 10, to 100. And so that's the second, that's the second pillar that is necessary for running these machine critical inference workloads.
And what does it take to do that? It takes, some people are like, Oh, You just need Kubernetes and Kubernetes has an autoscaler and that just works. That doesn't work for, for these kinds of mission critical inference workloads. And you end up catching yourself wanting to bit by bit to rebuild those infrastructure pieces from scratch. This has been our experience.
And then going even a layer beyond that, Kubernetes runs in a single. cluster. It's a single cluster. It's a single region tied to a single region. And when it comes to inference workloads and needing GPUs more and more, you know, we're seeing this that you cannot meet the demand inside of a single region. A single cloud's a single region. In other words, a single model might want to horizontally scale up to 200 replicas, each of which is, let's say, 2H100s or 4H100s or even a full node, you run into limits of the capacity inside of that one region. And what we had to build to get around that was the ability to have a single model have replicas across different regions. So, you know, there are models on Baseten today that have 50 replicas in GCP East and, 80 replicas in AWS West and Oracle in London, etc.
Developer experience for Compound AI Systems: The final one is wrapping the power of the first two pillars in a very good developer experience to be able to afford certain workflows like the ones that I mentioned, around multi step, multi model inference workloads, because more and more we're seeing that the market is moving towards those that the needs are generally in these sort of more complex workflows.

We think they said it very well.
Show Notes
Amir Haghighat, Co-Founder, Baseten
Yineng Zhang, Lead Software Engineer, Model Performance, Baseten
Full YouTube Episode
Please like and subscribe!
Timestamps
00:00 Introduction and Latest AI Model Launch
00:11 DeepSeek v3: Specifications and Achievements
03:10 Latent Space Podcast: Special Guests Introduction
04:12 DeepSeek v3: Technical Insights
11:14 Quantization and Model Performance
16:19 MOE Models: Trends and Challenges
18:53 Baseten's Inference Service and Pricing
31:13 Optimization for DeepSeek
31:45 Three Pillars of Mission Critical Inference Workloads
32:39 Scaling Beyond Single GPU
33:09 Challenges with Kubernetes and Infrastructure
33:40 Multi-Region Scaling Solutions
35:34 SG Lang: A New Framework
38:52 Key Techniques Behind SG Lang
48:27 Speculative Decoding and Performance
49:54 Future of Fine-Tuning and RLHF
01:00:28 Baseten's V3 and Industry Trends
Baseten’s previous TensorRT LLM workshop:

Share this post