





The Latent Space crew will be at NeurIPS on Tuesday! Reach out with any parties and papers of interest. We have also been incubating a smol daily AI Newsletter and Latent Space University is making progress.
Good open models like Llama 2 and Mistral 7B (which has just released an 8x7B MoE model) have enabled their own sub-industry of finetuned variants for a myriad of reasons:
Ownership & Control - you take responsibility for serving the models
Privacy - not having to send data to a third party vendor
Customization - Improving some attribute (censorship, multiturn chat and chain of thought, roleplaying) or benchmark performance (without cheating)
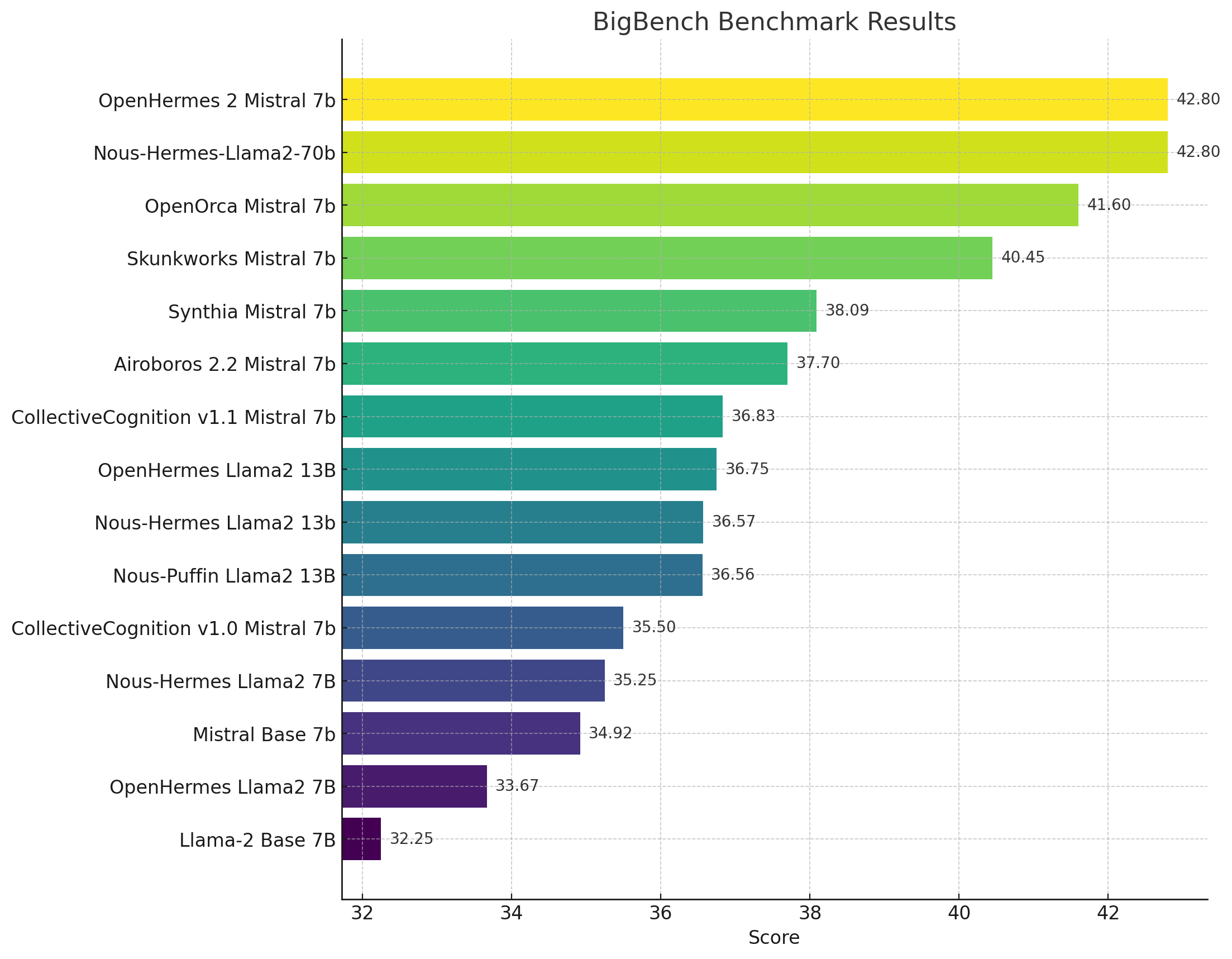
Related to improving benchmark performance is the ability to use smaller (7B, 13B) models, by matching the performance of larger models, which have both cost and inference latency benefits.
Core to all this work is finetuning, and the emergent finetuning library of choice has been Wing Lian’s Axolotl.
Axolotl
Axolotl is an LLM fine-tuner supporting SotA techniques and optimizations for a variety of common model architectures:
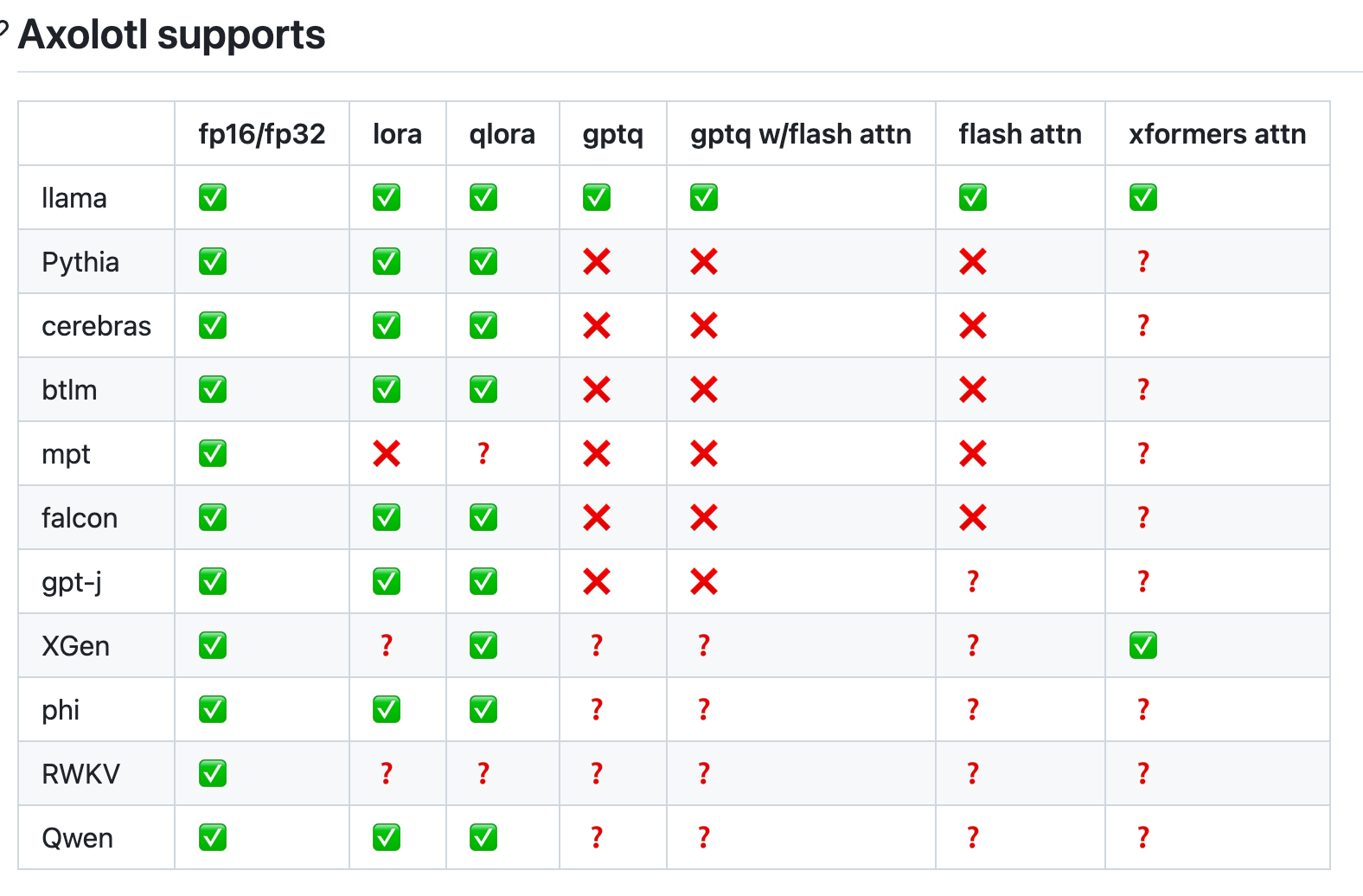
It is used by many of the leading open source models:
Teknium: OpenHermes, Trismigestus, CollectiveCognition
OpenOrca: Mistral-OpenOrca, Mistral-SlimOrca
Nous Research: Puffin, Capybara, NousHermes
Pygmalion: Mythalion, Pygmalion
Eric Hartford: Dolphin, Samantha
DiscoResearch: DiscoLM 120B & 70B
OpenAccess AI Collective: Manticore, Minotaur, Jackalope, Hippogriff
As finetuning is very formatting dependent, it also provides prompt interfaces and formatters between a range of popular model formats from Stanford’s Alpaca and Steven Tey’s ShareGPT (which led to Vicuna) to the more NSFW Pygmalion community.
Nous Research Meetup
We last talked about Nous at the DevDay Recap at the e/acc “banger rave”. We met Wing at the Nous Research meetup at the a16z offices in San Francisco, where they officially announced their company and future plans:
Including Nous Forge:
Show Notes
We’ve already covered the nuances of Dataset Contamination and the problems with “Open Source” in AI, so we won’t rehash those topics here but do read/listen to those if you missed it.
StackLlama model and blogpost
Timestamps
[00:00:00] Introducing Wing
[00:02:34] SF Open Source AI Meetup
[00:04:09] What is Axolotl?
[00:08:01] What is finetuning?
[00:08:52] Open Source Model Zoo
[00:10:53] Benchmarks and Contamination
[00:14:29] The Case for Open Source AI
[00:17:34] Orca and OpenOrca
[00:23:36] DiscoLM and Model Stacking
[00:25:07] Datasets and Evals over Models
[00:29:15] Distilling from GPT4
[00:33:31] Finetuning - LoRA, QLoRA, ReLoRA, GPTQ
[00:41:55] Axolotl vs HF Transformers
[00:48:00] 20x efficiency with StackLlama and Multipack
[00:54:47] Tri Dao and Mamba
[00:59:08] Roadmap for Axolotl
[01:01:20] The Open Source AI Community
Transcript
[00:00:00] Introducing Wing Lian
[00:00:00]
[00:00:00] swyx: Welcome to Latent Space, a special edition with Wing Lien, but also with our new guest host, Alex. Hello, hello. Welcome, welcome. Again, needs no introduction. I think it's like your sixth time on Latent Space already. I think so, yeah. And welcome, Wing. We just met, but you've been very prolific online. Thanks for having me.
[00:00:30] Yeah. So you are in town. You're not local. You're in town. You're from Minneapolis?
[00:00:35] Wing Lian: Annapolis. Annapolis. It's funny because a lot of people think it's Indianapolis. It's I've got Minneapolis, but I used to live out at least in the San Francisco Bay Area years ago from like 2008 to 2014. So it's fairly familiar here.
[00:00:50] swyx: Yep. You're the maintainer of Axolotl now, which we'll get into. You're very, very prolific in the open source AI community, and you're also the founder of the Open Access AI Collective. Yeah. Cool. Awesome. Maybe we can go over a little bit of your backgrounds into tech and then coming into AI, and then we'll cover what
[00:01:06] Wing Lian: happens and why you're here.
[00:01:08] Yeah. So. Back on tech, so I started years ago, I started way back when I was scraping, Apartment websites for listings and then, and then building like SEO optimized pages and then just throwing Google AdSense on it.
[00:01:24] And that got me through like college basically. Is
[00:01:27] swyx: that decent money? And what year
[00:01:28] Wing Lian: was this? Like 2004, 2005. Yeah, that's decent money. It's like thousand bucks a month. But as a college student, that's like. Gravy. Really good money, right? So, and then there's just too much competition It's just sort of like died off. I was writing stuff in like Perl back then using like like who nobody hosted anything on Perl anymore, right? Still did a little bit more like computer tech support and then software, and web more professionally.
[00:01:54] So I spent some time working on applications in the blood industry. I came out to San Francisco for, I was at SGN, so Social Gaming Network, as a startup. They started doing, with Facebook apps, and then they pivoted into doing mobile apps. And then, from there, I spent time.
[00:02:14] I've quite a few more startups since then and in the last few years I've been in the music space So like I was at United Masters for a while and then past year I've been at SoundCloud, but not doing that anymore and now that I have a lot more time It's just like all right.
[00:02:30] We're going full bore on axolotl and we're gonna we're gonna crush AI So yeah,
[00:02:34] SF Open Source AI Meetup
[00:02:34] swyx: totally you so you're here in town for the open source. Yeah, I meet up that we had yesterday Yep, yeah, that was amazing. Yeah, it was a big collection. Olama, Noose Research, Alignment Lab, Anyone else that I missed? I mean, Jeremy Howard is his own thing.
[00:02:47] Yeah.
[00:02:49] And Alex, you're also there. You love to bring SF to the world. Your takes?
[00:02:55] Alex Volkov: It's incredible that we recorded a Thursday Eye episode after that one. And LDJ, who's usually co hosts Thursday Eye, just like briefly mentioned, Oh yeah, I talked about it.
[00:03:04] Like, I saw Karpathy, and then I talked to Jeremy Howard, and the guy from Mistral came in, and it's like, He's talking about all these, titans of industry, basically, that outside of SF, You just don't meet casually hanging out in the same space. You can't, pull somebody. He ran into the Laylow from Mistral, he ran into him while, drinking water.
[00:03:20] He didn't even know he was there. It's just, that type of stuff is really hard to find outside of SF. So, absolutely, absolutely great. And also, presentations from Alignment Labs, presentations from News Research, news issues, talked about. Forge, and some of
[00:03:33] swyx: the other stuff they announced. We can say now they're officially a company.
[00:03:36] I met Technium.
[00:03:37] He
[00:03:37] Alex Volkov: came over here. He didn't want to get recorded. But maybe.
[00:03:41] Wing Lian: We'll wear him down at some point. Yeah, I'm excited for Forge. They've positioned it as this agentic sort of framework where it's just Drag and drop things and, fill in text with where you want to inject different variables and it opens up all of these potentials for data pipelines now, right?
[00:03:56] And using your own local LLMs and not relying on GPT 4 or anything like that. Yeah, yeah,
[00:04:02] swyx: good stuff. Okay, so let's maybe go into the Axolotl origin story and then we have, we have some intro or background.
[00:04:09] What is Axolotl?
[00:04:09] swyx: To do on like the open source model universe and also on fine tuning, but maybe just, since you're talking about your personal journey, what was your personal journey into
[00:04:18] Wing Lian: axolotl?
[00:04:19] Yeah, so my personal journey started like back in mid March, completely unrelated to AI and axolotl. And it really started, I fell while skiing, I torqued. Great 3 MCL sprain and being sort of like an active person that can no longer be active because the two, couldn't play soccer, because that is requires to have having knees until I, it's healed.
[00:04:42] So I. I decided I needed to find something to do to take up my free time. And that became, well, let's learn how to train in, these language models. It was everywhere. So I was like, all right, I'm just going to sit down, learn. I think I used like other, I think I was using like Alpacalora.
[00:05:00] Cause I think the Alpaca paper had just came out, come out then. So I was like using Alpacalora repo and sort of like learning how to use like. None of us were like GPU rich back then, and none of us, most of us still we're still all GPU poor, but I was doing what was it, like 4 bit, Alpaca Lord, there was like a 4 bit version where we were doing quant, or 8, no, 8 bit quantizations, and then I think they had released QLOR a little bit later, and I think right when, before QLOR came out, I was already starting to do fine tunes, but having this need to sort of like mix data sets together, and If you've ever looked at all the various different datasets available on HuggingFace, they all have various different prompt formats, and, it's sort of a nightmare, and then I think the other piece is if you've ever tried to fine tune, at least Back then probably the ecosystem's a little better now.
[00:05:54] Everybody required that you say, alright, you put your hyperparameters as command line arguments. And so it's always like, well, I now have to go copy and paste my previous thing and to change things out. And I really wanted it. to be in a YAML file because it was more portable and reproducible.
[00:06:09] So I was doing that and then the QLOR paper came out. Tim Dettmer announced that and then somebody looked it up for me yesterday and it's like between that announcement it took us seven days to get that integrated into Axolotl, right? Which is like, it's not. I wouldn't say it's really fast, but in a manner that, is in a, a reusable framework, I think it was quite the accomplishment then.
[00:06:33] And so we started, picking up traction with people there. And then it's just been building models, and then just iterating what my needs are. So, yeah. Excellent. Yeah. I
[00:06:44] Alex Volkov: want to ask, for folks who are listening who never heard of Axolotl, now do you describe how you got there?
[00:06:49] Can you, how do you summarize this for folks who maybe haven't fine tuned anything. They know about open source LLM exists, they maybe know like LLAML, what's XLR for somebody who doesn't know. I've never heard of a data set curation
[00:07:01] Wing Lian: creation before. We sort of have to take a step back and understand that, when you've got these language models, you have what I think most people refer to as like base models, also known as like foundational models, right?
[00:07:15] Where some benefactor, whether it's Meta or Mistral or whoever, has gone and spent all this money. To train these models on huge corpuses of text, right? And these, these corpuses, they're generally good across lots of different things, but they're really good at just saying, talking on and on and on, but they're not good at, following instructions or having chats or anything like that.
[00:07:40] So, when you think about fine tuning, it's like Saying, all right, we have this really sort of good generalized, text completion thing, and I want to turn it into something that I can talk to or have, follow instructions. So, I think fine tuning is probably best defined in like that.
[00:07:58] swyx: Okay, got it.
[00:07:59] And we actually
[00:08:01] What is finetuning?
[00:08:01] swyx: Do want to make sure that we have like an overall introduction to fine tuning for people because again like trying to make sure that we bring everyone along in this, in this journey. We already went into Loras and QLoras without explaining what
[00:08:12] Wing Lian: they are. Oh yes, yes, sorry.
[00:08:14] swyx: And so I will put things in my words and you can correct me as, as, as my I'll be the village idiot here.
[00:08:21] So, so fine tuning is basically sort of grabbing an open source model off the shelf, and then basically doing further training on it with a custom dataset of your own. Primarily, people use it, think about it as fine tuning for JSON output, or fine tuning for a style of response. Let's say you wanted to tell jokes, or be funny, or be short, or whatever.
[00:08:43] Just the open source AI community has really fine tuned in all sorts of different manner. I think we'll go over those those things now. Let's go over those things now, and then we'll talk about fine tuning methods.
[00:08:52] Open Source Model Zoo
[00:08:52] swyx: So there's a universe of people who fine tune stuff. Yesterday in your slides, you had, I'll just list some of these and then we'll maybe go through some of them, right?
[00:08:59] So Technium is personally leading Open Hermes, which is I think the sort of premier model out of the news. news community. There's OpenOrca, which you had a hand in. News, the news research itself also has Capybara and Puffin and all the others. There's Pygmalion, which I've never messed with.
[00:09:14] Eric Hartford, I am aware of his Uncensored Models and his Samantha Models. Disco Research with Disco LM. And then you personally have done Manticore, Minotaur, Jackalope, and Hippogriff. What should people know about all these names? Being part of AI Twitter is seeing all these things and going dude, I'm being DDoS'ed by all these things and I don't know how different they are.
[00:09:32] What should people know? Yeah, so
[00:09:34] Wing Lian: I think on a lot of these models, generally, we like to think of those as sort of general models, so If you think about it, what is GPT 4, what is Chad GPT? It's a good general model, and then, One of the services I think that OpenAI offers is like these fine tunings where you're a business and you have very specific business use cases and you might fine tune for that use case.
[00:10:00] All of these models are really just general use case that you can then go and maybe Fine tune another lore over it for your use cases, but they tend to be good. With good being relative, it's open source. Open source AI is still sort of is infancy. So, good is, it's pretty reasonable.
[00:10:18] It's probably still better than most, high schoolers at answering questions and being able to like figure things out and, and reasoning skills and math and those sorts of things, right?
[00:10:27] swyx: And also as measured on the Hugging
[00:10:29] Wing Lian: Face leaderboard. Yes, well, that's like a whole other discussion, right, there's a whole other, group of people who, and I, I mostly agree with them that, benchmarks can be, are pretty bogus these days, LM says, I think they published something recently where, even if you think the dataset's not contaminated, you can go and, find contamination And maybe we should step back and say what contamination is, right?
[00:10:53] Benchmarks and Contamination
[00:10:53] Wing Lian: So we have all of these data, when you go and do these benchmarks, there's a specific data set where there are these questions and usually it's multiple choice. And what can happen is, well, sometimes someone It puts the question, maybe maliciously, maybe accidentally, into the training dataset, and now the, the, your model knows how to answer the test questions really well, but it doesn't, it hasn't generalized the ability to actually do that
[00:11:20] Alex Volkov: right.
[00:11:21] We've seen some folks competitively announce models that are like the best at that leaderboard, but then it's, it's quite obvious that, In open source? Yeah, and in that leaderboard, for Hugging Face specific, I don't know if LMCs, if that had suffered, but we, there's been some models that seem to have been competitively trained and some leakage happened into their,
[00:11:41] swyx: like, supposal.
[00:11:43] I understand, once there's been a credible assertion, Hugging Face actually does take them down, right? Yeah, yeah,
[00:11:48] Alex Volkov: which is really hard to know, right?
[00:11:50] swyx: It's really hard to know, sometimes it's like a pure accident,
[00:11:52] Alex Volkov: it's oh, oops. You're going through a mixer. I think, a responsible So acknowledgement, that this kind of happened to you is also important.
[00:11:58] I saw LDJ from news research can acknowledge that. Because many of these datasets are collections of other datasets. There's a bunch of people are baking, basically. It's alchemy. Right. And so sometimes you don't know. Sometimes you pull an open source dataset and they announce, oh, you know what, actually, the MMLU benchmark which we used to Specifically identify models that did go into this data set, that then went into that data set.
[00:12:22] So sometimes it's actually an accident and folks take it down. But I've seen some competitive folks who want to put their name out there because people are starting to notice which is the top
[00:12:30] swyx: model. For those who want a fun take on this so the file one dataset. FindOne model from Microsoft was accused of being contaminated.
[00:12:37] And I saw this joke paper that was fantastic. It was called, training on the test set is all you need. It's a super small model that just memorizes everything. It was fantastic. So yeah, contamination, I think we've actually covered it in a previous episode before. So we're good. But again, I want to give people a map into the open source AI model, the universe.
[00:12:57] And Alex, you can also jump in here because you guys have spent a lot more time with them than I have. So, what should people know about Technium? What should people know about Noose? And then we can go down the list. Yeah,
[00:13:05] Wing Lian: I think so. I think if we start with, Technium. When you talk to him, he's gonna say, I think, I think his response is that he wants to build GP4 on his laptop, right?
[00:13:14] So, very, very good at building general models. I think with Noose, Noose Research, they're looking at more, sort of, More, more research focused things, like their Yarn models, I don't, I don't, they didn't actually train their, they have their own trainer for their Yarn models, but So they did not use Xlato for that one?
[00:13:30] They didn't use that, but like Is that, you don't have support for it? I think we do support Yarn, I think, I'd have to double check that answer. Yeah, I'm just kind of curious what you can and cannot support, and Yeah, I mean, Yarn is supportable, it's basically, I think it's just replacing, I think, the rope part of that, so Yeah, not, not a big deal.
[00:13:48] Yeah, it's not a big deal, it's just I haven't gotten to it, not enough people have asked, I think a lot of people have asked for other things, so it's just, squeaky wheel, right? I think at the end of the day, people are like building these data sets and I think if you sort of map things chronologically, these make more sense because it's like, how do we incrementally improve all of these models?
[00:14:07] So a lot of these models are just incremental improvements over the last thing, right? Whether it is sort of through methods of how do we, how did we curate the data set? How did we improve the quality of the data set? So, you maybe LDJ talked about it right on I think for, for Capybara and Puffin, like how those, those were very specific dataset curation techniques that he works on.
[00:14:29] The Case for Open Source AI
[00:14:29] Alex Volkov: So there's, folks are doing this for dataset curation. Folks are doing this for skillset building as well. Definitely people understand that open source is like very important, especially after the, the, the, the, the march, the debacle, the OpenAI weekend that we all had. And people started noticing that even after developer day in OpenAI, the APIs went out.
[00:14:48] And then after that, the whole leadership of the company is swiftly changed and people, there was worries about, you know. How can people continue building AI products based on these like shaky grounds that turned attention definitely to Technium at least in open RMS I started seeing this more and more on Twitter, but also other models and many companies They're gonna start with open AI just to get there quick, and then they they think about okay Maybe I don't want to share my knowledge.
[00:15:13] Maybe I don't want to sign up for Microsoft. Maybe they will change their terms and conditions so What else is out there? They turned to other companies. Up until yesterday, Google was nowhere to be found. We've talked about Gemini a little bit before in a previous And you can tune in
[00:15:26] swyx: to
[00:15:26] Alex Volkov: Thursday Eye.
[00:15:26] Yeah, you can tune in to Thursday Eye. We covered the Gemini release a little bit. And but many are turning into the open source community and seeing that Meta released and continues to release and commit to open source AI. Mistral came out and the model is way smaller than LLAMA and performs Significantly better.
[00:15:43] People play with OpenRMS, which is currently techniums based, news researched, sourced, axolotl trained OpenRMS, I assume, right? And then they play with this and they see that, okay, this is like GPT 3. 5 quality. We had GPT 4. 5 birthday just a week ago. A week ago, a year ago, a week ago, we never, interacted with these models of this caliber.
[00:16:04] And now there's one open source, one that's on my laptop, completely offline, that, I can continue improving for my use cases. So enterprises, companies are also noticing this. And the open source community folks are building the skill set, not only the data sets. They're building the actual kind of, here's how we're going to do this, with Axelotl, with these data sets.
[00:16:21] The curation pieces. Now. Interesting. There's like recipes of curation. The actual model training is kind of a competitive thing where people go and compete on these leaderboards that we talked about, the LMC arena, and that recently added open air and recently added open chat and a bunch of other stuff that are super cool.
[00:16:37] The hug and face open source leaderboard. And so there's a competitive aspect to this. There's the open source. Aspect to this, like Technium says, I want GPT 4 on my laptop. There's the, let me build a skill set that potentially turns into a company, like we saw with Noose. Noose just, started organizing, a bunch of people on Discord, and suddenly, they're announcing their company.
[00:16:54] It's happening across all these modalities, and suddenly all these people who saw these green pastures and a fairly quick way to, hey, here's a cool online community I can, start doing cool stuff with. You mentioned the same in the beginning, right? Like, after your accident, what's cool, let me try this out.
[00:17:08] Suddenly I start noticing that there's a significant movement of interest in enterprising companies into these areas. And, this skill set, these data sets, and this community is now very Very important, important enough to create an event which pulls in Andrei Karpathy from OpenAI to come and see what's new Jeremy Howard, like the event that we just talked about, people are flying over and this is just a meetup.
[00:17:28] So, definitely, the community is buzzing right now and I think Axelot is a big piece as well.
[00:17:34] Orca and OpenOrca
[00:17:34] Wing Lian: Cool. Maybe we can talk about like Orca real quick, Orca, OpenOrca rather, I think there was a lot of buzz when, the first Orca paper came out. And just briefly, what is Orca? Yeah, Orca was basically having traces of like chain of thought reasoning, right?
[00:17:48] So they go and they, they distill sort of GPT 4. They take, they take a sampling of data from the Flan dataset. Maybe we can like add some show notes in the Flan dataset. Yeah, but we've covered it. Okay, cool. Use GPT 4 to say, all right, explain this in a step by step reasoning, right?
[00:18:06] And then you take that and you, they train the model and it showed, very good improvements across a lot of benchmarks. So OpenOrca was sort of the open reproduction of that since Microsoft Research never released that particular data set. And going back to sort of the Hugging Face leaderboard thing, those models did really well.
[00:18:23] And then I think, so sort of the follow up to that was SlimOrca, right? I think Going into and building the OpenOrca dataset, we never really went in and, validated the actual answers that GPT 4 gave us, so what we did was one from OpenChat actually cross referenced the original Flan, the original Flan response, the human responses, the correct answers with the dataset, and then I went and took it and sent all of, both of them to GPT 4 and said, is this answer mostly correct, right?
[00:18:54] Yeah. And then we were able to filter the dataset from, At least of the GPT 4 only answers from like 800, 000 to like 500, 000 answers or rows and then, and then retrain the model and it had the same performance as the original model to within I think, 0. 1 percent here about, and 30 percent less data.
[00:19:13] So, yeah. Okay.
[00:19:15] swyx: Interesting. So, I mean, there's, there's so much there that I want to highlight, but yeah. Orca is interesting. I do want people to know about it. Putting chain of thought into the data set like it's just makes a ton of sense one thing I think it would be helpful for people to scope thing these things out is how much data are we talking about when when you When people are fine tuning and then how much time or resources or money does it take to train to fine
[00:19:36] Wing Lian: tune?
[00:19:37] Yeah, so I think there's a little bit of overlap there with sort of like fine tuning techniques, but let's say Orca and I think even Hermes, they're both relatively large data sets like 10 billion tokens. Yeah. So large data sets being or the original Orca was, or the original open Orca was 800,000 rows.
[00:19:55] I believe it was somewhere in the ballpark of like a gigabyte of data, of gigabyte, of text data. And I, I don't. I believe, Hermes was, is like a quarter million rows of data, I don't know the actual byte size on that particular one. So, going and training a, let's, let's say everybody's training 7 billion Mistral right now, right?
[00:20:15] So, to tri I, I believe to fine tune 7 billion Mistral on, let's say, 8 A6000s, which have 48 gigabytes of VRAM, I believe, It takes about 40 hours, so 40, and then that's, depending on where you get your compute, 40 times 6, so it's like 500 to fine tune that model, so, and, and that's assuming you get it right the first time, right?
[00:20:44] So, you know.
[00:20:45] swyx: Is, is that something that X. Lotto handles, like, getting it right the first
[00:20:48] Wing Lian: time? If you talk to anybody, it's like you've probably tried at least three or four runs or experiments to like find the right hyperparameters. And after a while you sort of have a feel for like which, where you need your hyperparameters to be.
[00:21:04] Usually you might do like a partial training run, do some benchmark. So I guess for Al Farouk, whether you're going by his. This is Jeremy, he's, his actual name, or his twitter handle. He released the Dharma dataset, which is basically a subset of all the benchmarks. And Axolotl actually supports, you know taking that subset and then just running many benchmarks across your model every time you're doing an evaluation so you can sort of like see sort of relative it's not going to be the actual benchmark score, but you can get ideas alright, is this benchmark improving, is this benchmark decreasing, based on, you know Wait,
[00:21:39] swyx: why don't you run the full benchmark?
[00:21:41] What, what, what The
[00:21:42] Wing Lian: full benchmarks take Take a long time. Significant, yeah, significant amount of time. Yeah. And Okay, so that's like
[00:21:48] swyx: mini MMLU. Yeah. Like,
[00:21:49] Wing Lian: mini BigBench or whatever. Yep, exactly.
[00:21:51] Alex Volkov: It's really cool. We, when I joined Web2Masters just recently, and one of the things that I try to do is hey I'm not, I'm a software engineer by trade, I don't have an MLE background, But I joined a company that does primarily MLE, and I wanted to learn from the community, Because a lot of the open source community, they use weights and biases, And the benchmark that you said that Pharrell did, remind me of the name, sorry.
[00:22:13] Dharma? Dharma, yeah, yeah. So Luigi showed me how Dharma shows inside the dashboard. In Wi and Biases dashboard and so you can actually kinda see the trending run and then you can see per each kind of iteration or, or epoch or you can see the model improving trending so you can on top of everything else.
[00:22:29] The wi and biases gives like hyper parameter tracking, which like you, you started with common line and that's really hard to like remember. Also the Dharma data set, like the quick, the mini orca mini, you mini many different things. It's pretty cool to like visualize them as well. And I, I heard that he's working on a new version of, of Dharma, so Dharma 2, et cetera.
[00:22:47] So hopefully, hopefully we'll see that soon, but definitely it's hard, right? You start this training around, it said like 40, 50 hours. Sometimes, sometimes it's like your SSHing into this machine. You, you start a process, you send it with God and you just go about your day, collecting data sets, and then you have to return.
[00:23:04] And the whole process of instrumentation of this is still a little bit like squeaky but definitely. Tuning performance, or like grabbing performance in the middle of this, like with Dharma and some other tools, is very helpful to know that you're not wasting precious resources going somewhere you shouldn't go.
[00:23:21] Yeah.
[00:23:22] swyx: Yeah. Very cool. Maybe I'll, I'll, before we go into like sort of more details on fine tuning stuff, I just wanted to round out the rest of the Excel autoverse. There's, there's still Eric Hartford stuff. I don't know if you want to talk about Pygmalion, Disco, anything that you know about
[00:23:35] Wing Lian: those, those things.
[00:23:36] DiscoLM and Model Stacking
[00:23:36] Wing Lian: Yeah, I think like one of the, definitely one of the more interesting ones was like the Disco 120b, right? Yeah, I know nothing about it. Yeah. So, so. Alpen from Pygmalion AI, right, so they, so Pygmalion is a sort of a, it's, it's, they have their own community, a lot of it is based around, roleplay models, those sorts of things, and Alpen, like, put together, merged together Llama270B, so, and Alpen, like, put together, merged together Llama270B, so, I don't remember how he stacked them together, whether he merged the layers in between. There's a whole, there's a whole toolkit for that by Charles Goddard, where you can like take a single model and like stack them together or multiple models merge.
[00:24:18] That's like a whole other talk and a whole other tool set, but was able to create this 120. Billion parameter model out of a LAMA two 70 B. And then I believe the, yeah, disco is a fine tune of, of the, the, the sort of the base one 20 B is, I believe Goliath one 20 B. So, and, and what are the
[00:24:37] swyx: headline results that people should know about
[00:24:39] Wing Lian: disco?
[00:24:39] I think for the headline results, I, I've, I haven't played with it personally because it's. It's a very large model and there's a lot of GPU, right? But, like, from what I've heard anecdotally, it performs really well. The responses are very good. Even with, like, just, even the base model is a lot better than, Llama70b.
[00:24:57] So, and we, I think generally everybody's like, we would all love to fine tune Llama70b, but it's just, it's so much, it's so much memory, so much compute, right?
[00:25:07] Datasets and Evals over Models
[00:25:07] Wing Lian: I
[00:25:07] Alex Volkov: want to touch on this point because the interesting thing That comes up out of being in this ecosphere and being friends with open source folks, tracking week to week state of the art performance on different models.
[00:25:19] First of all, a lot of the stuff that the folks do a couple of weeks ago, and then something like Mistral comes out, and a lot of the stuff back then, Doesn't technically make sense anymore. Like the artifacts of that work, the actual artifacts, they don't no longer make sense. They're like lower on the on, on the hug and face leaderboard or lower on LM CS leaderboard.
[00:25:36] But some of the techniques that people use, definitely the datasets. The datasets keep traveling, right? So open airmen, for example, is the dataset. The tum cleaned up for only. Open sourceable data that previously was just Hermes. And that, it was previously used to train Lama. And then once Mistral came out, it was used to train Mistral.
[00:25:54] And then it became significantly better on the 7b base Mistral. So the data sets keep traveling, keep getting better a little bit here and there. And so the techniques improve as well. It looks like both things are simultaneously true. The artifacts of a month and a half ago. The, the actual models themselves, it's great the hug and face has them, because not every company can keep up with the next weeks', oh, I, I'll install this model instead, sell this model instead.
[00:26:19] But the, the techniques and the, the dataset keep improving as we go further, and I think that's really cool. However, the outcome of this is that for a long time. For many, many people, including us, that we do this every week. We literally talk with people who release these models every week. It's really hard to know.
[00:26:36] So, there's a few aspects of this. One, I think, like you said, the bigger model, the 70B models, you actually have to have somebody like Perplexity, for example, giving you access to the 70B really fast. Or you have to, like, Actually, find some compute, and it's expensive, especially for the bigger models. For example Falcon 180B came out, like the hugest open source model.
[00:26:56] How do you evaluate this if you can't run it? Nobody liked it. It's really, so first of all, nobody liked it, but secondly, only the people who were able to find compute enough to run inference on this, they only had like, I can't run this on my laptop, and so that's why it's much easier, something like OpenRMS 7 to be, 7B, it's much easier, because you can run this on your MacBook.
[00:27:14] It's much easier to evaluate. It's much easier to figure out the vibes, right? Everybody talks about the vibes as an evaluation check. If you're plugged in enough, if you follow the right people, if they say pretty much the same things all independently, then you run into a problem of whether they're repeating, and their stochastic parents are repeating the same thing, or they actually evaluated themselves.
[00:27:31] Yeah, you never know. But, you never know, but like, I think on a large enough scale on Twitter, you start getting the feel. And we all know that like, OpenRMS is one of the top performing models, benchmarks, but also vibes. And I just wanted to highlight this vibes checks thing because you can have the benchmarks, you can have the evaluations, they potentially have contamination in them, potentially they not necessarily tell you the whole story because some models are good on benchmarks, but then you talk to them, they're not super helpful.
[00:28:00] And I think it's a combination of the benchmarks, the leaderboards, the chatbot, because LMSys, remember, their ranking is not only based on benchmarks, it's also people playing with their arena stuff. People actually like humans, like, get two answers. I think they completely ignore benchmarks. Yeah, and then They only do ELO.
[00:28:18] Oh, they do ELO completely, right? So that, for example, is just like people playing with both models and say, Hey, I prefer this one, I prefer that one. But also there's like some selection bias. The type of people who will go to LMCs to play with the models, they're a little bit specific in terms of like who they are.
[00:28:33] It's very interesting. There's so many models. People are doing this in this way, that way. Some people are doing this for academic rigor only to test out new ideas. Some people are actually doing this like the Intel fine tunes of Mistral. Intel wanted to come out and show that their hardware approach is possible, Mistral, etc.
[00:28:51] And it's really hard to know, like, what to pick, what to use. And especially on the bigger models, like you said, like the Llama 70B, the Falcon 180B. It's really because, like, who has the compute to validate those? So I would mention that, like, use with caution. Like, go and research and see if the biggest model that just released was actually worth the tokens and the money you spend on it.
[00:29:12] To try and, if you're a business, to integrate it.
[00:29:15] Distilling from GPT4
[00:29:15] swyx: Since you said use of caution, I'll bring in one issue that has always been in the back of my mind whenever I look at the entire universe of open source AI models, which is that 95 percent of the data is derived from GPC 4, correct?
[00:29:30] Which technically you can't use for commercial licenses,
[00:29:34] Wing Lian: right?
[00:29:35] swyx: What is the community's stance on this kind of stuff?
[00:29:40] Wing Lian: I think from the community stance, like I feel like a lot of us are just experimenting, so for us, it's like, we're not going and building a product that we're trying to sell, right?
[00:29:49] We're just building a product because we think it's interesting and we want to use it in our day to day lives, whether or not we try and integrate it. Personal use, yeah. Yeah, personal use, so like, as long as we're not selling it, yeah, it's fine. But
[00:30:01] swyx: like, I as a company cannot just take OpenHermes and start serving
[00:30:05] Alex Volkov: it and make money on it.
[00:30:06] OpenHermes you can. Because the opening of OpenHermes, I think, is a clean up. That did after the regular Hermes, please folks, check your licenses before you listen to podcasts and say, Hey, I will tell you though, you could say the same thing about OpenAI. You could say the same thing kind of makes sense, where OpenAI or StabilityAI trains their diffusion model on a bunch of pictures on the internet, and then the court kind of doesn't strike down Sarah Silverman, I think, or somebody else, who came and said, hey, this has my work in it, because of the way how it processes, and the model eventually builds this knowledge into the model, and then it doesn't actually reproduce one to one what happened in the dataset.
[00:30:45] You could claim the same thing for open source. Like, we're using And by we, I mean the, the open source community that I like happily report on uses GPT 4 to rank, for example, which is the better answer you, you, that's how you build one, one type of data set, right? Or DPO or something like this, you, you basically generate data set of like a question and four answers, for example, and then you go to GPT 4 and say, Hey, smartest model in the world right now, up to Gemini Ultra, that we should mention as well.
[00:31:11] Which one of those choices is better? But the choices themselves are not necessarily written with GPT 4. Some of them may be, so there's like full syntactic datasets. But there's also, datasets are just ranked with GPT 4. But they're actually generated with a sillier model, or like the less important model.
[00:31:25] The lines are very blurry as to what type of stuff is possible or not possible. And again, when you use this model that's up on Hug Face, the license says you can use this. OpenAI is not going to come after you, the user. If anything, OpenAI will try to say, hey, let's prevent this, this type of thing happening, and the brain, but I honestly don't think that they could know even, not that it makes it okay, it's just like, They also kind of do this with the Internet's archive, and also, I think that some of it is for use.
[00:31:55] You use models to help you augment tasks, which is what GPT 4 lets you do.
[00:32:00] swyx: Yeah, the worst thing that OpenAI can do is just kick you off OpenAI. That's because it's only enforced in the terms of service.
[00:32:05] Alex Volkov: Sure, but just like to make sure, to clarify who they're going to kick out, they could kick out like News, for example, if news are abusing their service, a user of the open source, fully Apache 2 open source, for example, They won't get kicked out if they use both, just because they use both.
[00:32:22] I don't believe so. I don't think OpenAI has a claim for that.
[00:32:25] swyx: Well, we're not lawyers, but I just want to mention it for people to know it's an issue.
[00:32:30] Wing Lian: And one of the things, like, I talked to someone recently, and I think that they also are like interested in it, but also to the point of like, right, if I use a model trained on data, using GPT for data, But I use that model to then regenerate new data.
[00:32:46] Is that model, is that data okay? So like you start going down this whole rabbit hole. So yeah. All right.
[00:32:53] swyx: Fantastic. Cool. Well, I think that's roughly highlights most of the open source universe. You also have your own models. Do you want to shout out any one of them? Yeah.
[00:33:01] Wing Lian: I mean, I think like, I think Early on, Manicore got a lot of love.
[00:33:04] I think it was mostly popular in, like, the roleplay communities. It was, it tended to be pretty truthful. It tended to be, like, have relatively good answers, depending on who you ask, right? But, I think for me, it was just, Releasing models was a way to try and, like, continue to build out the product, figure out what I needed to put into the product, how do I make it faster, and, if you've got to, like, go and debug your product, you may as well have it do something useful.
[00:33:29] Awesome. So, yeah.
[00:33:31] Finetuning - LoRA, QLoRA, ReLoRA, GPTQ
[00:33:31] swyx: Okay, and then maybe we'll talk about just fine tuning techniques. So this is going to be a little bit more technical than just talking about model names and datasets. So we started off talking about LoRa, QLoRa. I just learned from your readme there's ReLoRa. Which I've never heard about.
[00:33:45] Could you maybe talk about, like, just parameter efficient fine tuning that whole, that
[00:33:50] Wing Lian: whole journey, like, what people should know. Yeah, so with parameter efficient fine tuning, I think the popular ones, again, being, let's, we'll start with lore, right? So, usually what you do is you freeze all the layers on your base, on the base model, and then you, at the same time, you sort of introduce additional Oh, this is tight.
[00:34:08] No. You introduce, another set of layers over it, and then you train those, and it is done in a way that is mathematically possible, particularly with LORs that you can, then you, you, When you, when you train the model, you, you run your inputs through the base model, whose weights are frozen, but you, then you also run it through the additional weights, and then at the end you combine the weights, and then, and then, or you combine the weights to get your outputs, and then at the end, and when you're done training, you're left with this other set of weights, right, that are completely independent, and And then from that, what you can do is, some person smarter than I figured out, well, oh, they've done it in such a way that now I can merge these weights back into the original model without changing the architecture of the model, right?
[00:35:03] So, so, that tends to be, like, the go to, and You're training much fewer parameters so that when you do that, yes, you still need to have all of the original weights, but you have a smaller gradient, you have a smaller optimizer state, and you're just training less weights, so you can tend to train those models on, like, much smaller GPUs.
[00:35:27] swyx: Yeah. And it's roughly like, what I've seen, what I've seen out there is roughly like 1 percent the number of parameters that you're trading. Yeah, that sounds about right. Which is that much cheaper. So Axelotl supports full fine tune, LoRa, QLoRa,
[00:35:40] Wing Lian: Q. Yes. So, so QLoRa is, is very similar to LoRa. The paper was, if I remember correctly, the paper was Rather, traditionally, most people who did Loras were, were, they were quant, they were putting the model weights in 8 bit, and then fine tune, parameter efficient fine tuning over the Lora weights, and then with QLora, they were quantizing all of those, they were then quantizing the weights down to 4 bit, right, and then I believe they were also training on all of the linear layers in the model.
[00:36:15] And then with ReLore, that was an interesting paper, and then, I think, like, it got implemented. Some people in the community tried it, tried it out, and it showed that it didn't really have the impact that the paper indicated that it would. And from what I was told recently, that they re I guess they re released something for Relora, like, a few weeks ago, and that it's possibly better.
[00:36:44] I personally haven't had the time. What was the
[00:36:46] swyx: main difference,
[00:36:47] Wing Lian: apart from quantization? I don't know. Okay. What was the main difference, sorry?
[00:36:49] swyx: Apart from quantization, right? Like,
[00:36:50] Wing Lian: Qlora's thing was, like, we'll just drop off some bits. With Relora, what they did was, you would go through, you would define some number of steps that you would train, like, your Lora with, or your Qlora.
[00:37:01] Like, you could do Like, ReqLore, if you really wanted to, you would, you would train your LoRa for some number of steps, And then you would merge those weights into your base model, and then you would start over. So by starting, so, then by starting over, The optimizer has to find, like, sort of, re optimize again, and find what's the best direction to move in, and then do it all again, and then merge it in, do it all again, and theoretically, according to the paper, doing ReLore, you can do parameter efficient fine tuning, but still have sort of, like, the performance gains of doing a full fine tuning, so.
[00:37:38] swyx: Yeah, and
[00:37:39] Wing Lian: GPTQ? And GPTQ, so it's, I think with GPTQ, it's very similar to, more similar to QLore, where you're, it's mostly a quantization of the weights down to like 4 bit, where GPTQ is a very, is a specific methodology or implementation of quantization, so. Got it.
[00:37:57] Alex Volkov: Wang, for, for folks who use Axolotl, your users, some people who maybe, Want to try it out?
[00:38:03] And do they need to know the differences? Do they need to know the implementation details of QLora versus ReLora? Or is it okay for them to just know that Axolotl is the place that already integrated them? And if that's true, if that's all they need to know, how do they choose which method to use? Yeah,
[00:38:22] Wing Lian: so I think like, I think most people aren't going to be using ReLora.
[00:38:25] I think most people are going to be using either Lora or QLora. And I think they should have it. They should have an understanding of why they might want to use one over the other. Most people will say that with Qlora, the quality of the final model is not quite as good as like if you were to do a LoRa or a full fine tune, right?
[00:38:44] Just because, you've quantized these down, so your accuracy is probably a little off, and so that by the time you've done the Qlora, you're not moving the weights how you would on a full fine tune with the full parameter weights.
[00:38:56] Interesting.
[00:38:57] swyx: Okay, cool. For people who are more interested, obviously, read the papers. I just wanted to give people, like, a high level overview of what these things are. And you've done people a service by making it easy for people to try it out. I'm going to, I'm going to also ask a question which I know to be wrong, but I'm curious because I get asked this all the time.
[00:39:15] What is the difference between all these kinds of fine tunes
[00:39:17] Wing Lian: and RLHF? Okay, between all of these sorts of fine tunes and RLHF. So all of these sorts of fine tunes are based, are, ideally, this, they are taking knowledge that the base model already knows about, and presenting it in a way to the model that you're having the model answer like, Use what it already knows to sort of answer in a particular way, whether it's, you're extracting general knowledge, a particular task, right?
[00:39:44] Instruct, tune, chat, those sorts of things. And then generally with RLHF, so what is, let's go back, what is it? Reinforcement Learning with Human Feedback. So if we start with the human feedback part, What you're doing is you generally have, you have like a given prompt and then you, maybe you have one, maybe you have two, I think, like if you look at with Starling, you have like up to what, seven different, seven different possible responses, and you're sort of ranking those responses on, on some sort of metric, right, whether the metric is how much I, I might like that answer versus or I think with like starling is like how how how helpful was the answer how accurate was the answer how toxic was the answer those sorts of things on some sort of scale right and then using that to go back and like sort of Take a model and nudge it in the direction of giving that feedback, to be able to answer questions based on those preferences.
[00:40:42] swyx: Yeah, so you can apply, and is it commutative? Can you apply fine tuning after and onto an RLHF model? Or should the RLHF apply, come in afterwards,
[00:40:54] Wing Lian: after the fine tune? Um, I, yeah, I don't know that there's There's been enough research for one way or another, like, I don't know.
[00:41:02] That's a question that's been asked on Discord. Yeah, like, I definitely would say I don't know the answer. Go and try it and report back to me and let me know so I can answer for the next guy.
[00:41:10] swyx: It's shocking how much is still unknown about all these things. Well, I mean, that's what research is for, right?
[00:41:16] Wing Lian: So actually I, I think I saw on the top of a leaderboard, it was a, it was a mytral base model, and they didn't actually fine tune it. They, or they, they just did RLH, they did like an RLHF fine tune on it using like, I don't, I don't recall which dataset, but it was like, and it benchmarked really well.
[00:41:37] But yeah, you'd have to go and look at it. But, so it is interesting, like going back to that, it's like. Traditionally, most people will fine tune the model and then do like a DPO, PPO, some sort of reinforcement learning over that, but that particular model was, it seemed like they skipped like the supervised fine tuning or Scott.
[00:41:55] Axolotl vs HF Transformers
[00:41:55] swyx: Cool. One thing I did also want to comment about is the overall, like, landscape, competitive landscape, I don't know. Hugging Face Transformers, I think, has a PFT module.
[00:42:05] Wing Lian: Yeah, yeah, the PEFT, the Parameter Efficient Fine Tuning, yep. Is that a competitor to you? No, no, so we actually use it. We're just a wrapper over sort of, sort of the HuggingFace stuff.
[00:42:15] So, so that is their own sort of module where They have, taken the responsibility or yeah, the responsibility of like where you're doing these parameter efficient fine tuning methods and just sort of like, it is in that particular package where transformers is mostly responsible for sort of like the modeling code and, and the trainer, right.
[00:42:35] And then sort of, there's an integration between the two and, there's like a variety of other fine tuning packages, I think like TRL, TRLX, that's the stability AI one. Yeah, I think TRL likes the stability, yeah, Carper, and TRL is a hugging face trainer. Even that one's just another wrapper over, over the transformers library and the path library, right?
[00:43:00] But what we do is we have taken sort of those, yes, we've We also use that, but we also have more validation, right? So, there are some of us who have done enough fine tunes where like, Oh, this and this just don't go together, right? But most people don't know that, so like Example?
[00:43:19] Like, people want to One and one doesn't go together. I don't have an example offhand, but if you turn this knob and this knob, right? You would think, all right, maybe this will work, but you don't know until you try. And then by the time you find out it doesn't work, it's like maybe five minutes later, it's failed.
[00:43:34] It's failed in the middle of training or it's failed during the evaluation step. And you're like, ah, so we've, we've added a lot of, we've added a lot more validation in it. So that like, when you've, you've created your configuration, you run it through and now you say. The validation code says this is probably not right or probably not what you don't, not what you want.
[00:43:52] So are you like a, you
[00:43:53] swyx: do some linting of your YAML file?
[00:43:56] Wing Lian: There, I guess you could call it linting, it's sort of like Is there a set of rules out
[00:44:00] swyx: there somewhere? Yeah, there's a set of rules in there. That's amazing, you should write documentation like This rule is because, this user at this time, like, ran into this bug and that's what we invested in.
[00:44:10] It's like a good collection
[00:44:11] Wing Lian: of knowledge. Yeah, it is, and I guess like, if you really wanted to, like, figure it out, I guess you could, like, git blame everything, and But, yeah, it's, so, I think that's always a useful thing, it's like Because people want to experiment but they don't, people will get frustrated when you've experiment, you're experimenting and it breaks and you don't know why or you know why and you've just gone down the rabbit hole, right?
[00:44:37] So, so I think that's one of the big features that's, that I think I find important because it's It prevents you from doing things you probably shouldn't have, and it, and sometimes we will let you do those things, but we'll try and warn, warn you that you've done that.
[00:44:50] I
[00:44:51] Alex Volkov: have a follow up question on this, actually, because yesterday we hung out to this open source event, and I spent time by you a couple times, like when people told you, oh, XLR, I use XLR, it's super cool, and then the first thing you asked is, like, immediately, like, what can we improve?
[00:45:04] And yes, from multiple folks, and I think we talked about this a little bit, where there's It's a developer tool. It's like a machine learning slash developer tool. Your purpose in this is to help and keep people, as much as possible, like, Hey, here's the best set of things that you can use right now. The bear libraries are, or the bear trainer, for example, is a bear trainer.
[00:45:28] And also, maybe we should talk about how fast you're implementing these things. So you mentioned the first implementation took a week or so. Now there's a core maintainer group, right? There's like, features are landing, like Qlora, for example. Neftune, I don't know if that's one example of something that people potentially said that it's going to be cool, and then eventually, like, one of those things that didn't really shake out, like, people quickly tested this out.
[00:45:48] So, there's a ton of Wait, Neftune is cancelled? I don't know if it's fully canceled, but based on vibes, I heard that it's not that great. So like, but the whole point that I'm trying to make with Neftune as well is that being existing in the community of like XLR or like, I don't know, even following the, the GitHub options or following the Discord, it's a fairly good way to like, learn these, Kind of gut feelings that you just, you just said, right?
[00:46:14] Like where this, maybe this knob, that knob doesn't work. Some of these are not written down. Some of these are like tribal knowledge that passes from place to place. Axel is like a great collection of many of them. And so, do you get That back also from community of folks who just use, like, how do you know who uses this?
[00:46:30] I think that's still an issue, like, knowing if they trained with XLR or should they add this to things? Talk about, how do you get feedback and how else you should get feedback?
[00:46:38] Wing Lian: Yeah, I mean, most of the feedback comes from the Discord, so people come in and , they don't get a training running, they run into, like, obscure errors or, errors that That's a lot of things that maybe, maybe as a product we could catch, but like, there's a lot of things that at some point we need to go and do and it's just on the list somewhere.
[00:46:58] Right that's why when people come up, I'm like, what, what were your pain points? Because like, as a developer tool, if you're not happy with it, or you come in and in the first, Takes you 30 minutes and you're still not happy. You leave the tool and you may, you might move on maybe to a better tool, maybe to, one with less frustration, but it may not be as good, right?
[00:47:17] So I'm trying to like, figure out, all right, how can I reduce all this frustration? Because like for me, I use it every day for the most part, right? And so I am blind to that, right? Mm-Hmm. . Mm-Hmm. . I just know, I, I go do this, this, and this. It pretty much mostly works, right? But, so I don't have sort of that, alright, that learning curve that other people are seeing and don't understand their pain points.
[00:47:40] Yeah,
[00:47:40] Alex Volkov: you don't have the The ability to onboard yourself as a new user completely new to the whole paradigm to like get into the doors of like, Oh, no, I don't even know how to like ask about this problem or error.
[00:47:53] swyx: Cool. The last few things I wanted to cover was also just the more advanced stuff that you covered yesterday.
[00:48:00] 20x efficiency with StackLlama and Multipack
[00:48:00] swyx: So I'll just, caution this as like, yeah, this is more advanced. But you mentioned Stackllama and Multipack. What are they
[00:48:06] Wing Lian: and what should people know? Yeah, so, so, Stack Llama was, that paper came out, so Stack Llama I think was like, two, two, two separate, two separate concepts that they announced, so the first one was They being hugging face.
[00:48:20] Yeah, sorry, yes, they being hugging face, so the first one being sort of like, this idea of packing, like some packing sequences together, so like, if we think about training data, right, your training data is, let's say, to keep the math easy, let's say your training data is 500, We, we, we, we will use the terminology words.
[00:48:39] Let's say your training data is 500 words long, and let's say your, your context length, you know how much data your, that your model can accept is like, or that you want feed into your model. It's, let's say, we won't use tokens again, we'll we'll use it is it's 4,000 tokens, right? So if you're training at 4K Con or four 4,000 4K contacts and you're only using 500 of it, you're sitting like with the other 1500.
[00:49:05] 3, 500 words that you're not using, right? And typically that's either filled with these PAD tokens, so I think I made the analogy last night that it's like having sort of like a glass here you fill it up with a shot of liquor and then you're and that's your training data and then you just fill it up with more water and those are your PAD tokens and it's just, it doesn't do much, right?
[00:49:27] It's still the same thing, but you still have to go through all of that to go through all your training data. And then, so what Stack Llama showed was you could just sort of take your training data, append the next row of training data until you filled that entire 4k context, so in this example, right, with 500 words to 4k, that's 8 rows of training data.
[00:49:48] But, the problem with that is, is that with a lot of these transformer models, they're very much relying on attention, right? So, like, if you now have this sequence of words that now, in order for the, the model has seen all of these other words before, right? And then it sees another set of words, another set of words, but it's learning everything in context of all the words that it's seen before.
[00:50:13] We haven't corrected the attention for that. And just real quickly, since I said that that paper was two concepts, the other one was, I believe it was like a reinforcement learning, but outside the scope of this. So going from that, I implemented that early on because I was like, Oh, wow, this is really great.
[00:50:29] And. Yes, because it saves you a bunch of time, but the trade off is a little bit of accuracy, ultimately, but it still did pretty well. I think when I did Manicore, I think it used sort of that concept from Stack Llama of just sort of appending these sequences together, right? And then sort of the next evolution of that is Multipack, right?
[00:50:51] So, there was a separate paper on that, it was, I believe it was referenced, it got referenced in the Orca paper, where you could, you could properly mask those out using like a, I think it was like a lower block triangular attention mask, and then sort of, so, So, there's that. I did try implementing that, manually recreating that mask, but then one from the OpenChat, so he was helping with OpenOrca as well, and he had done an implementation of Multipack, and where he used FlashAttention, so FlashAttention So that was released by TreeDAO, and it was this huge performance gain.
[00:51:35] Everybody uses it now, even the Transformers library now, they've taken all of these, like, people are taking all of these models and sort of like, making it compatible with FlashAttention. But in Flash Tension, there is one particular implementation that lets you say, Well, I'm sending you all of these sequences like you would in Stack Llama, But let me send you another, another, Set of information about, this is where this set of sequences is, this is where the second set of sequences is.
[00:52:06] So like, if it was like, 500 words long, and you stacked them all together, you would just send it a row of information that was like, 0, 500, 1000, 1500, etc, etc, out to 4000. And it would know, alright, I need to break this up, and then run the forward pass with it. And then it would be able to, and it was much more, much more performant.
[00:52:29] And I think you end up seeing like 10x, 20x improvements over sort of, I mean, I think FlashAttention was like a 2x improvement, and then adding that with the Multipack, you start to see like, depending on, how much data you have, up to like a 20x improvement sometimes. 20x. 20x. Wow. Yeah.
[00:52:48] And I only know the 20x because I, like, before last night, I was like, I re ran the alpaca, I looked up the alpaca paper because it was like, I just need a frame of reference where somebody did it, and I think they used eight A100s for three hours, and they said it cost them 100. I don't, I don't think eight A100s cost, I don't know how much it costs right now.
[00:53:14] But I ended up rerunning it. Usually a dollar an hour, right? Yeah, so eight. The cheapest is like a
[00:53:18] Alex Volkov: dollar, a dollar an hour for one.
[00:53:20] Wing Lian: Yeah, so that's still like 24, 25. But maybe if you're going on Azure, maybe it's like, maybe it's 100 on Azure. I mean, it used to be more expensive, like, a year ago.
[00:53:31] Yeah, and then, so I re ran it with sort of like, I turned on all of the optimizations just to see what it would be. And like, and usually Multipack is the biggest optimization, so Multipack with Flash Detention. And it, I think I spun it up on 8 L40s, and it ran, and I didn't let it run all the way through, I just grabbed the time, the estimated completion time, and it was like 30 minutes, so it would have cost like 4 or 5 to run the entire, like, reproduce the alpaca paper, right?
[00:54:00] Which is crazy. It's crazy. 20x,
[00:54:02] Alex Volkov: yeah. I want to ask about, like, you said you turned on all the optimization. Is that the yaml file with xlodl, you just go and like check off, like, I want this, I want that? Yeah, yeah,
[00:54:10] Wing Lian: so there's like one particular yaml file in there, That, there's one particular YAML file in there that's like, it's under examples, llama2, fft, optimize.
[00:54:20] So, I think someone had created one where they just turned, they put in all of the optimizations and turned them on. I mean, it actually, it does run, which is like, sort of surprising sometimes, because sometimes, you optimize this, optimize this, and sometimes they just don't work together, but, yeah.
[00:54:36] Just turn the knobs on, and like, fine tuning should really just be that easy, right? I just want to flip the knob and move on with my life and not figure out how to implement it.
[00:54:47] Tri Dao and Mamba
[00:54:47] Alex Volkov: Specifically, the guy behind FlashAttention came up with something new. You want to talk about this a little bit? You want to briefly cover Mamba?
[00:54:53] Yeah, let's talk about Mamba. Let's talk about Mamba. So, what is Mamba?
[00:54:57] Wing Lian: Oh, gosh. I mean, I have not read the paper end to end. Like, I think you need to find someone smarter to tell you what Mamba is. But I think in a nutshell, it's sort of this, like, attentionless, attentionless model architecture. So I think it was, like, using a lot of his learnings from, like, I think Stanford did a lot of like sort of attentionless models with like I think Hyena several months ago as well so it is sort of this evolution of that of these of this research they've done and Apparently I believe it is what 5x faster for inference But the memory requirements are sub quadratic, so like I think, so with models that have attention, as you scale the context length out, the memory and the inference and training time goes up, quadratically, like Or squared, right?
[00:55:50] Whereas this one is closer, much closer to linear. So it's, it's really exciting. And there's a lot of like, I think a lot of people in the community are excited about it because especially I was talking with LGJ yesterday and he was saying it showed think with the perplexity curves and given the same exact, like comparing a, I think it was like a 140 million parameter model with the Pythea 140 million parameter model trained on the exact same data set as that model that there was a, that I believe the perplexity curves were a little bit lower than the Pythea model.
[00:56:26] So yeah. Yeah.
[00:56:28] Alex Volkov: I think one thing LDJ also is the guy behind, he was super excited to get like us to talk on Thursday about Mamba as well. He mentioned to me that the significant improvements in performance, it could be like 2x in the beginning where like lower tokens are, but then as you scale more with longer, longer tokens, because the non quadratic, the almost linear type scale, it's the performance improvements for larger and bigger and like more models are significant, like in the 10x to maybe 20x.
[00:56:57] Yeah, I think he said 10 yeah. At the larger models. And that's where we want to go. We want to get to the bigger sizes, the longer trains.
[00:57:06] Wing Lian: Yeah, yeah. So in particular, the longer context links. So like, if you're talking like 50, 60, like, or 128k context, like what is it, GPT turbo now? Or 4 turbo?
[00:57:19] 128, yes. So, like, getting out to that because it's no longer, yeah, it's like, it's, it's just as fast. I believe it should be just as fast, like, generating those tokens as it is, like, on a short, on a short
[00:57:34] Alex Volkov: prop. So, this came out just recently, and then between running to this open source AI, driving here in Uber, like, you already put out something that I saw that, that you started.
[00:57:44] Wait, what? Something today? Yeah,
[00:57:47] Wing Lian: what did you do? Well, I mean, so like tree and I forget who the other author is on that paper. They had released sort of the modeling code on, on GitHub. And then sort of like, it wasn't, they hadn't quite put it like made it like transform or, transformers library native.
[00:58:04] So, and it, it didn't quite drop in. Like cleanly into like Axel lot to get it, so that you could fine tune it. So like, it was one of the things I actually wanted to try and get done before the, before the meetup yesterday, and just demo that because that would be awesome, right? That'd be awesome.
[00:58:20] I think it dropped on Thursday and you know No. What day? No, today is Thursday. Thursday. I keep. I keep thinking today was Friday, that's what I said. I think, so it dropped on what, Tuesday, the meetup was Wednesday, I wanted to get it done for that, but I was getting it where it would like, the loss would just go to zero, and just fail.
[00:58:40] So, but yeah, right before coming here, I was working on it this morning and I think we finally got it working. So, I think Pharrell's training something on it. I'm pretty sure like Tenuim is going to be training something on it soon. So,
[00:58:52] Alex Volkov: yeah. So, we'll see, but I wanted to highlight the speed because you started with like within a week the first alpaca or, implementation and change in Axelot came and now like you're talking about like three days and that's with you flying and that's with you like presenting and talking on podcasts.
[00:59:08] Roadmap for Axolotl
[00:59:08] swyx: Very productive. Yeah. Yeah, excellent. Well, so, we're going to start wrapping up soon, but I always wanted to give you space to also talk about what you're working on next, and, on the
[00:59:17] Wing Lian: roadmap for Axelotl. Yeah, I think so, the roadmap for Axelotl is really like, I think, trying to stabilize sort of the feature set.
[00:59:26] Like, so the first thing on the roadmap is to write the roadmap, and then sort of going from there, it's, I think, So for me the sort of the vision is like it's it's a developer first platform right and as a developer You you're maybe you're more than likely doing it this sort of this side hustle side project trying to figure out like how do I build?
[00:59:45] LLMs and you know how do I build you know? How do I use a trainer that sort of thing and then you're you get comfortable with this tool? And then you maybe you take it to your company and you're training Models for where you work, right? So, and then, ultimately, you're saying, I want to use this because it's easy and I know how to use it.
[01:00:03] So, for me Given that sort of like, if I follow that through, that thought through, it's like, well, companies don't want to use this if it's hard for them to like, if given their specific use cases, right, they might need something specific in the workflow that they, and I, what I don't want is to have is them having to fork it, like, to Like, fork it in a way that is, like, hard to maintain, that if they want to get features, they then have to, like, rebase it and all of that.
[01:00:32] So, for me, and I actually have, like, a issue in GitHub that's about three or four months old at this point of exactly, yet, expose, like, create a plugin system, expose sort of, like, these hooks where companies can go in and build their own plugins and sort of, like, Modify, like, hyperparameters on the fly, or modify various, like attributes of training.
[01:00:57] Yeah, it's becoming a platform. Yeah, exactly. So, I need to, provide a way for, for them to be able to, like, use it in, in a, in a reliable manner and something that, that they can go invent and feel comfortable using, right? Yeah,
[01:01:10] swyx: awesome. You are working independently? You left SoundCloud a few months ago, and you have a non profit, the Open Access AI Collective.
[01:01:20] The Open Source AI Community
[01:01:20] swyx: It has a Discord people can join. How else can people support
[01:01:22] Wing Lian: you? I think really, like, for me, the biggest thing is, like, I'm looking, I'm always looking for contributors. Like, we have a great, set of core contributors, Nanobit, Amin slash TMM1, Casper Hansen, and then, and there are probably a few others who, I've Don't have the names offhand for, but we do see some like smaller PRs trickle through, but like A lot of the, sort of like, if I had somebody that could have gone and done Mamba for me, that would make my life a hundred times easier, right?
[01:01:51] I wouldn't have to be scrambling between, Ubers and meetings and those sorts of things to try and, like, get that implemented. So, there's definitely this, like, roadmap of, Things to do and nice to have, right? And like Nano is great at being a community manager and answering questions and sort of fueling all of that and being technical and you know It's really technical and can stole open PR's and fix things and like so and he's a graduate So he's a graduate student in Japan Working, doing research, and somehow he finds time to like, support this community, right?
[01:02:25] He's amazing, I love him, and I think everybody should like, show him some love, and then, but yeah, like, ultimately, the, I think the, the big, yeah, the biggest thing that I could ask for would be just, yeah, more core contributors.
[01:02:38] swyx: Cool. All right, well if you're interested in checking it out check out XLotto.
[01:02:42] Alex, anything else to, to
[01:02:43] Alex Volkov: add? Yeah, I will say folks who are listening to us, open source doesn't just happen. It happens because there's a bunch of great people. Giving their life, basically, to these things. So, first of all, be nice in comments. Like, that's obvious. Like, if you want to come in and complain about something, be productive and do the work as much as possible so the person who's, like, giving out of their life to help you will actually find it, like, easier.
[01:03:06] It usually gets to a point where, like, a small project becomes a platform, the platform then has rules, and then it's making it hard for some people to just go in and kind of say, Hey, this thing or that thing. Remember, there's people contributing without necessarily a lot of gain from it, just because they're contributing to the community.
[01:03:24] And also, come in and contribute. If you're using axolotl, and I heard many people, commercial people, come up to you, A16z folks come up to you, like many people, if they use axolotl, Give back. Give back to the community. I think it's always great. So I just like, if you're listening to this, and you've used Excelato, it helped you, there is a way to also contribute, not necessarily as the only core contributor, as a sponsorship, reach out, reach out to you as well, but definitely talk about this and give feedback as well.
[01:03:51] That's also very helpful. Sometimes people get stuck, and it's like, ah, okay, we'll do something else. No, just give feedback, talk about this. I think everybody else will generally benefit from that. Excellent.
[01:04:01] Wing Lian: Thank you. That's it. Yeah. Alright.
[01:04:04] Alex Volkov: Cool. Thanks for coming. Everybody should try Axolotl and tell us what
[01:04:08] swyx: they
[01:04:09] Wing Lian: think.
[01:04:11] Yeah.



Share this post