



AI Agents, meet Test Driven Development
Guest Post: 5 stages for embracing test-driven development (TDD) to build stronger, more reliable AI systems! One of our top talks from AIE Online Track
swyx here! We’re delighted to bring you another guest poster, this time talking about something we’ve been struggling to find someone good to articulate: TDD for AI. This is part of a broader discussion we’re seeing as teams of AI Engineers want templates and models for how the SDLC adapts in the age of AI (e.g. Sierra’s ADLC)
Anita’s talk came out of the online track for the NYC Summit, and it’s warm reception gives us enough confidence to re-share it with the broader LS community.
AIEWF talk selection is very selective - we have over 500 talks submitted with the deadline closing soon - but we have just gotten resources for the online track again for AIEWF - send in your talk and we’ll fit good ideas in where-ever we have room!
30 minute Talk Version
from AI Engineer Summit’s Online Track:
Based on the success of the online talk, we asked Anita to convert it into a blogpost for easier scanning/discussion. What follows is Anita’s updated, short blog version of the main takeaways, but it’s definitely handy to have the full talk to doubleclick into each stage and get more context!
AI agents, meet Test Driven Development
Historically with Test Driven Development (TDD), the thing that you're testing is predictable. You expect the same outputs given a known set of inputs.
With AI agents, it's not that simple. Outcomes vary, so tests need flexibility.
Instead of exact answers, you're evaluating behaviors, reasoning, and decision-making (e.g., tool selection). This requires nuanced success criteria like scores, ratings, and user satisfaction, not just pass/fail tests.
And internal evals aren’t enough. You need to make continuous adjustments based on real-world feedback.
So how can you build a process around this?
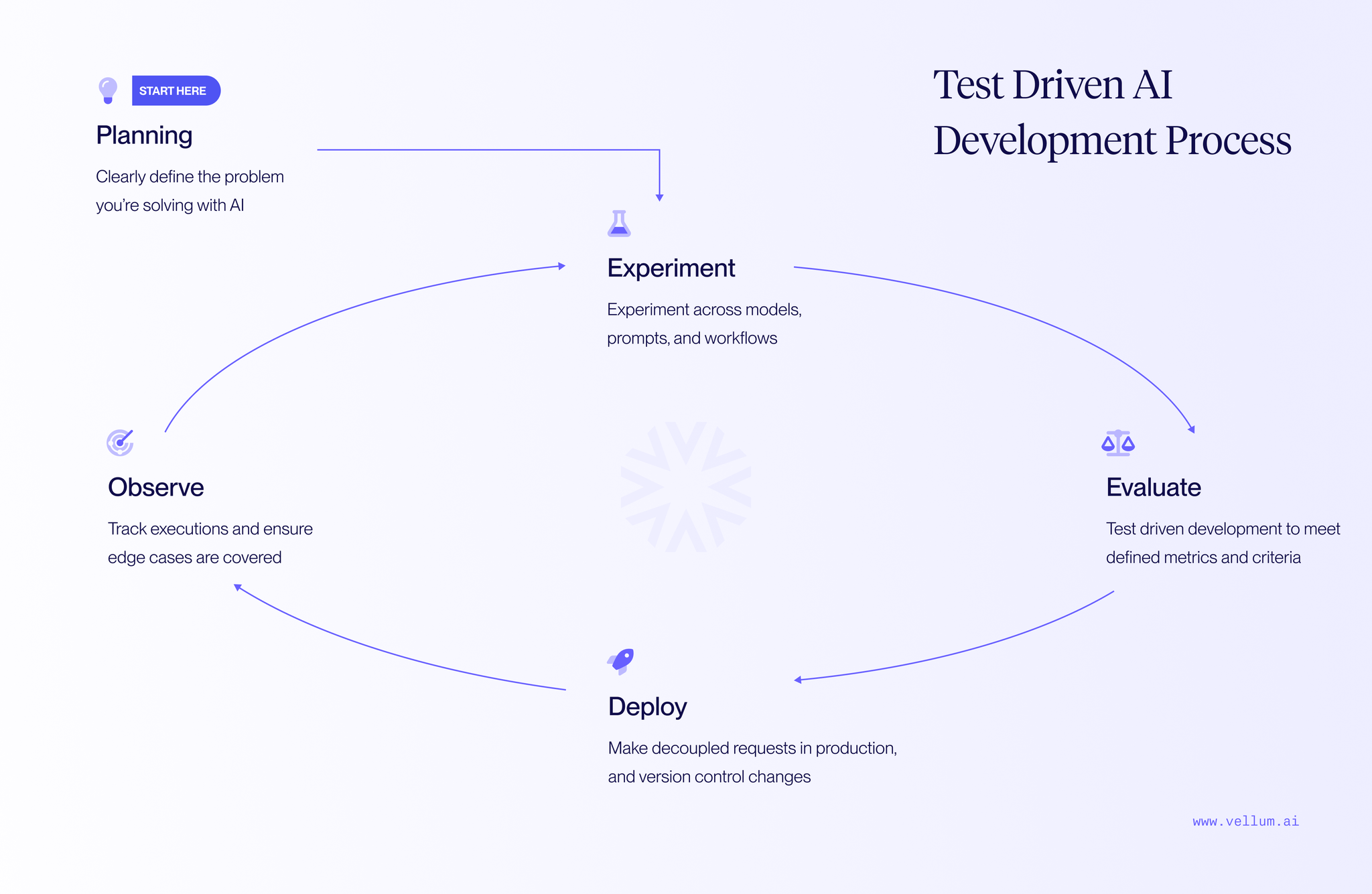
At Vellum, we’ve worked with hundreds of companies refining this process. If you're after a "self-improving" magic agent, this isn’t the article for you.1 We believe in observability and debugging, because that’s what actually works.
What follows is a breakdown of the five stages you can follow to enable TDD-based AI development for your organization and ship reliable agentic applications.
Stage 1: Planning / Speccing
First you must start by clearly defining the problem you're solving with AI.
Not every issue is an AI problem. Sometimes a simpler solution using traditional software works better. Map out the user journey clearly from start to finish. Identify exactly where AI adds value, how users will interact with the AI-generated outputs, and isolate any areas where friction might occur.
For example, if you’re developing a customer support chatbot, specify clearly which types of customer issues (intents) your AI will handle, and which you'll escalate to humans.
Second, your AI will only be as good as the context (data) you provide. Understand exactly what data you have, its quality, and how you’ll access it (MCP or otherwise). Think about how fresh it needs to be or how often you'll need updates. And don't forget privacy!
Finally, plan for future readiness by answering questions like:
Workflow-Agent tradeoffs: If I want to add agentic capabilities later, will it be easy?
Reusability: Is this system modular enough to easily build upon or reuse components?
Areas of Technical Risk: What components are likely to change and how will I test for regressions when I change them?
Once you have your process outlined, it’s time to validate whether your idea can be built with AI.
Stage 2: Experimentation
Unlike traditional software engineering, LLMs are non-deterministic, unpredictable, and getting your AI working right requires a lot of trial and error.
The second stage of the TDD process requires you to first validate that AI works in the context of your use-case.
You start by building an MVP. The MVP can be as simple as a prompt that you want to test with different models. You follow some prompting structure, test different techniques and evaluate at a small scale whether these models can work with your use-case.
For example, if your system should extract data from a PDF, you might test Gemini 2.0 Flash Thinking mode or Mistral OCR, and do a quick comparison on how the results compare. At this stage you should optimize for rapid iteration cycles to narrow in on the best implementation quickly.
An MVP might also look like an orchestrated workflow, doing several things in sequence or looping through multiple steps. Think of using RAG, pulling details from longer documents, calling tools (functions), or keeping track of things with short- or long-term memory.
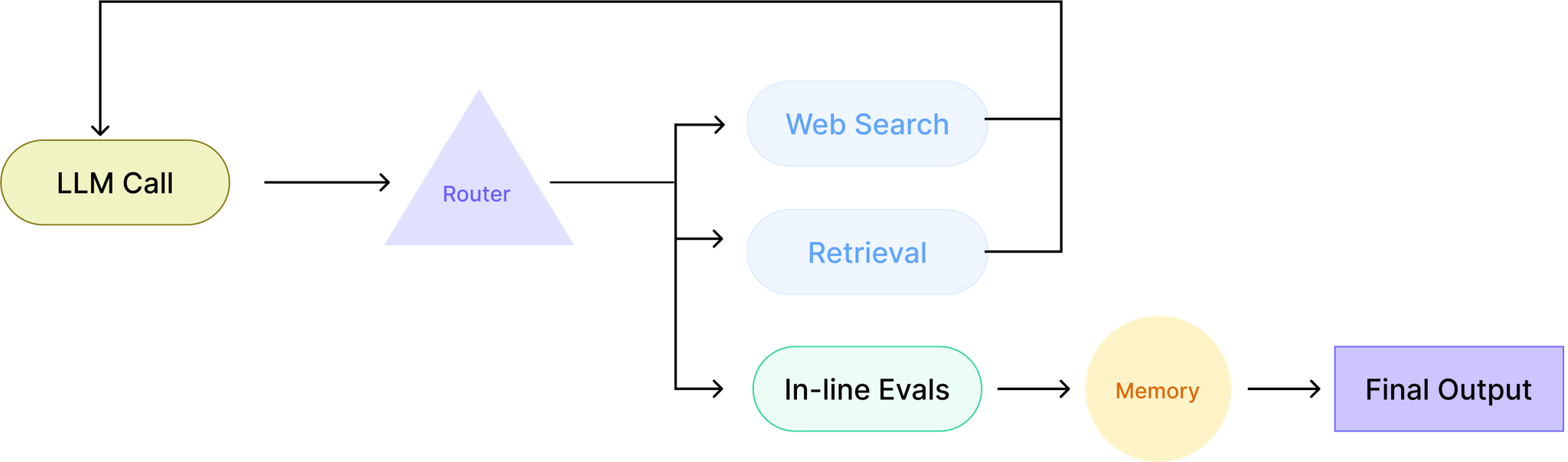
If your MVP relies on all these pieces working together, you'll want to test it out with a few examples early on, just to confirm that the whole setup actually makes sense for your use case.
But for production-ready solutions, chances are that you’ll need to evaluate hundreds or thousands of these tests.
That brings me to the next stage.
Stage 3: Evaluation at scale
At this stage, you should work with product and domain experts who will know how to tell whether your AI system is "doing a good job."
Say you're building a chatbot that suggests real estate properties based on user preferences:
You'd need to work with the product team to figure out things like what questions the chatbot should ask, how it filters results, and how users interact with it.
At the same time, you'd check with the legal team about what regulations you may need to stay in compliance with, like fair housing laws, privacy rules, and what you can or can't say when suggesting properties.
Using this knowledge, you’ll be creating a database with all these examples and the correct responses. Then you’ll run automated tests to see which of these test will pass/fail.
At this point, you probably know that with AI solutions you’ll end up evaluating more things than just “correctness”. Some examples include checking for correctly retrieved context from a vector database, JSON validity, semantic similarities and more.
Then you keep repeating this loop: create tests → run evals → make small change to prompts/logic to fix for that test → check for regressions.
Notice the last part: Check for regressions.
Fixing a prompt for one test case can easily introduce regressions to other test cases. You need to have a mechanism that will be able to check for these regressions and flag them for review.
Now, let’s say that through evals, you’ve built the confidence you need to put your AI system in front of customers in production. What's next?
Stage 4: Release management
As you've probably noticed, AI development needs a lot of trial and error, and small tweaks can break the system.
This means that when it comes time to integrate your AI system with your application layer, you'll get massive benefit from two concepts:
Decoupled deployments
Release management
If you decouple the deployment lifecycle of your AI systems from that of your application layer, you'll be able to ship changes to your AI features quickly and roll back easily if things go wrong.
You won't be bound to the release cycle of the rest of your product.
Second, and just as important, is having solid release management. Good release management means version-controlling the system as a whole and allowing for different environments point to different versions. For example, your application layer's staging environment might point to a newer, less stable release of your AI system, whereas your production environment might point to an older, more tried-and-true version.
This separation also allows you to run the same evaluations every time you push an update, so you can clearly see what's improving, and what's getting worse. You should be able to easily answer questions like:
Regressions: Did the new update cause more mistakes or unexpected behavior?
A/B testing: Can we easily compare performance with previous versions?
Rollbacks: If something goes wrong, can you quickly switch back to a safe, earlier version?
Now, lets say your AI solution is in production and is being used by your customers. Amazing!
However, even now, it's likely your AI feature will come across some user input you could never have expected and produce an output that leaves users dissatisfied. The best AI teams capture this data, flag edge-cases, and create a feedback loop such that they can run new experiments to account for them.
This brings us to observability.
Stage 5: Observability
This is the final stage in this list, but in many ways it feels like stage 0.
This is where you need to capture all edge cases that show up in production, and successfully update your AI solution to account for them without regressing in other ways.
For example, you can capture implicit or explicit feedback from your customers to learn if a given AI response or workflow completion was useful for your end user.
Two things are very useful here:
Graph or Tracing view (looking at all executions, API invocations, received data)
Feedback loops
The more complex your system gets, the more you'll need observability.
The more agentic your system becomes, the more you'll rely on observability.
Use a graph view to track important details—things like unique executions, API calls, parameters you're sending, and data you're getting back—at every step of your workflow. Drill down into each and every execution, and easily spot issues.

It’s like a continuous loop honestly — your work is never done.
It will get more stable over time, but in order to get full control of your system you need to tame it first.
Once deployed, the TDD looks something like this: capture feedback loops → evaluate → improve → regression check → deploy.
(Shameless plug!) About Vellum
Vellum’s solutions are designed around this TDD vector.
We’ve worked closely with hundreds of companies who have successfully put agentic TDD into practice — and we’ve designed our platform around those best practices.
Our platform gives you the flexibility to define and evaluate agent behaviors, capture real-world feedback, and continuously improve your AI—all in one place.
If you want to see a demo, happy to do one — book a call with us here.
Ironically, Augment Code’s talk is exactly about this!
|