

[AINews] Anthropic growing 10x/year while everyone else is laying off >10% of their workforce
A quiet day lets us reflect on an interesting dichotomy in the economy.
While you could debate ARR revenue recognition, it is hard to deny very real reports of secondary market and traditional media reporting that Anthropic, after their “miracle Q1” of 80x annualized growth and one month jump of $15B ARR, is now being valued at $1-1.2T, making it officially overtake OpenAI as the 11th-15th most valuable company in the world.
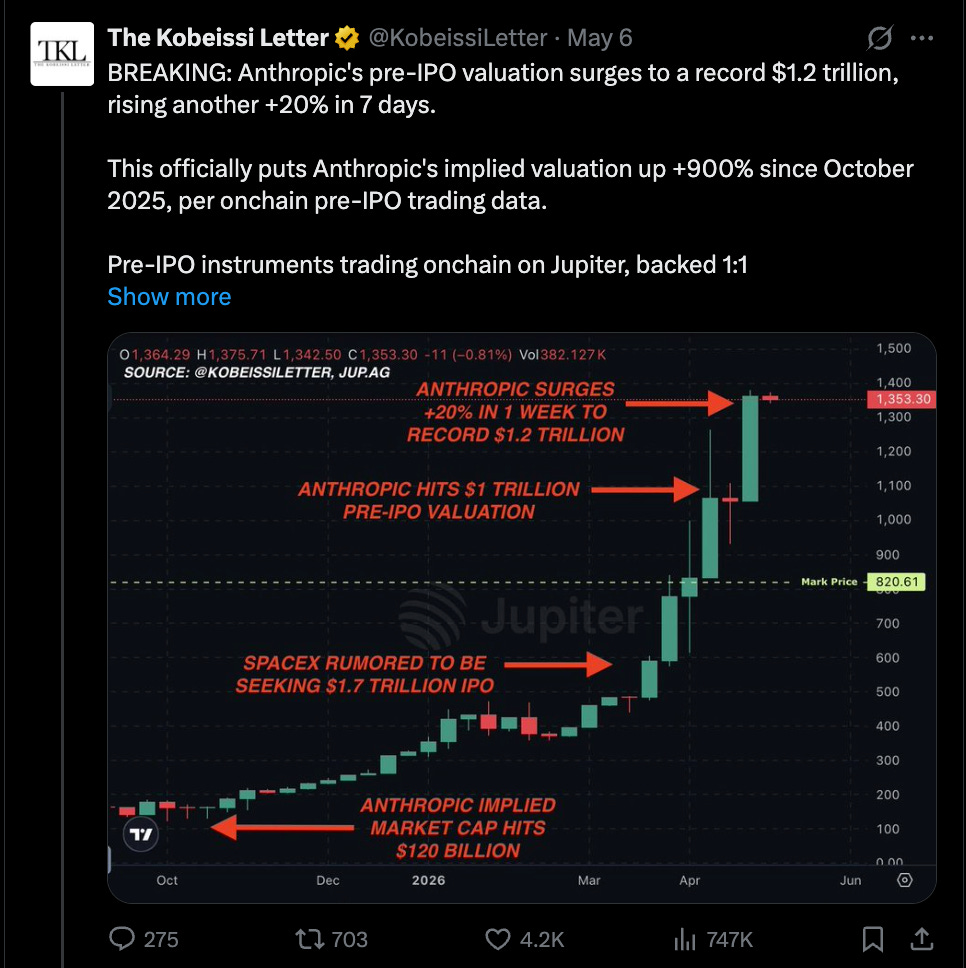
This is a REVENUE, not a financial speculation, chart:
All this and while Block (40%), Coinbase (14%), and Cloudflare (20%) have laid off massive swathes of their workforce, all citing AI readiness. It’s hard to tell the degree to which this is “AI-washing” “normal” layoffs, but it is clear that stronger companies, like Linear, are the ones that grow, not shrink, due to AI.
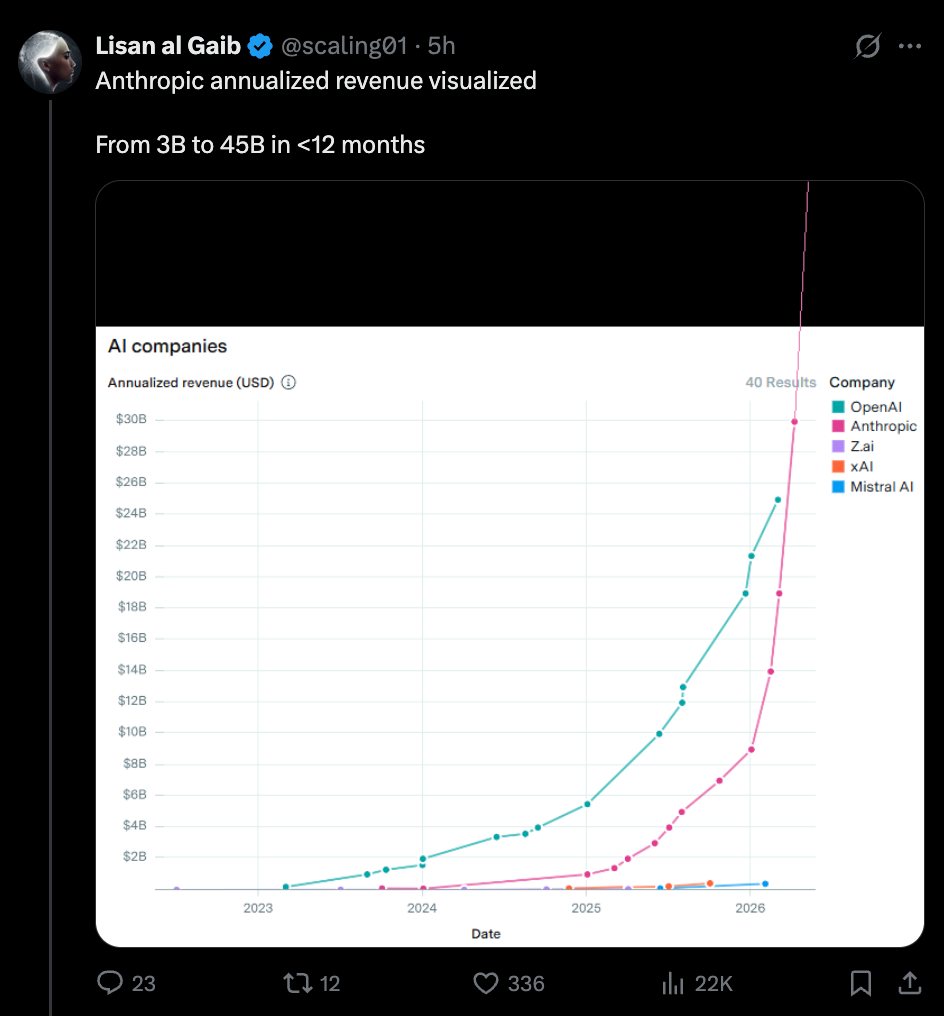
And of course, the “AI” growth has mostly been hardware and energy, rather than software:

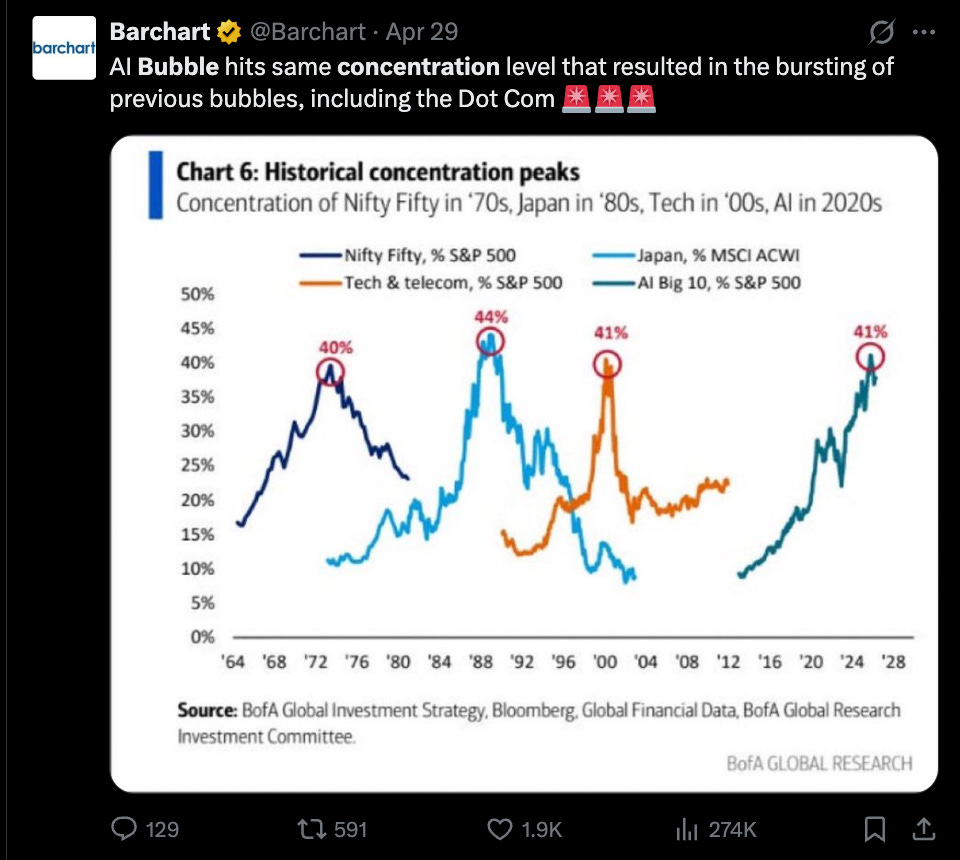
With the AI growth and non-AI shrinkage, we are approaching bubble territories of concentrations in the economy:
AI News for 5/7/2026-5/8/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
OpenAI’s GPT-5.5 / Codex rollout, cyber models, and safety instrumentation
GPT-5.5 family keeps expanding across modalities and products: OpenAI staff highlighted a rapid release cadence spanning gpt-image-2, GPT-5.5, GPT-5.5 Pro, GPT-5.5 Instant, GPT-Realtime-2, realtime translate, realtime whisper, and GPT-5.5 Cyber in roughly two weeks, per @reach_vb. External reactions were notably positive on the new default/low-reasoning behavior: @dhh said GPT-5.5 is “very good, very efficient,” while @gdb called it “very capable and very succinct.” On public evals, Arena placed GPT-5.5 Instant at #5 on Multi-Turn, #11 on Vision, and #24 on Document Arena. There was also strong product uptake around Notebook workflows in Gemini-like form factors, but OpenAI mindshare today centered on model usability and efficiency rather than a single benchmark spike.
Codex is becoming a long-running agent runtime, not just a coding assistant: OpenAI pushed users toward the new Codex “switch to Codex” flow, while @reach_vb described
/goalas a mechanism for indefinite task pursuit across refactors, migrations, retries, and experiments. Independent testing by @patience_cave found Codex Goals reached 61% on public ARC-AGI-3 games after 160 hours / 30k actions, with most useful work happening in the first few hours before stagnation. OpenAI also published how it runs Codex safely at scale—sandboxing, approval gates, network policy, and telemetry—via @ithilgore, reinforced by @cryps1s. Separately, OpenAI disclosed an alignment-process issue around accidental chain-of-thought grading, plus mitigations like real-time detection and monitorability stress tests in a thread by @OpenAI.Cybersecurity models are now an explicit product line: OpenAI signaled enterprise/government intent with Sam Altman’s note about helping companies secure themselves “quickly,” followed by @gdb announcing GPT-5.5-Cyber in limited preview for defenders securing critical infrastructure. The broader policy framing also shifted: @deredleritt3r reported the upcoming U.S. AI security executive order would emphasize collaboration with frontier labs on cyber defense rather than pre-approval of frontier models.
Open models and infra: Zyphra’s ZAYA1, vLLM/SGLang optimization, and cheaper coding stacks
Zyphra made the most substantive open-model release of the day: @ZyphraAI released ZAYA1-74B-Preview, a 74B total / 4B active MoE, framed as a strong pre-RL base checkpoint trained while scaling on AMD hardware. The model is under Apache 2.0 per the follow-up. Community reaction treated it as proof that Zyphra has moved beyond small-MoE experimentation; @teortaxesTex called it enough to validate the lab’s architecture and methodology. Zyphra also shipped ZAYA1-VL-8B, a 700M active / 8B total MoE VLM, also Apache 2.0, via @ZyphraAI.
Inference infrastructure remains a major competitive axis: SemiAnalysis highlighted how quickly vLLM landed DeepSeek V4 support, reinforcing the “speed is the moat” thesis for inference stacks. vLLM-Omni v0.20.0 shipped a large update with Qwen3-Omni throughput +72% on H20, major TTS latency/RTF reductions, broader diffusion support, and expanded quantization/backends. On the SGLang side, @Yuchenj_UW reported hearing numbers up to 57B tokens/day on inference, while a long technical recap from @ZhihuFrontier detailed H20-specific DeepSeek optimization strategies across prefill/decode disaggregation, FP8 FlashMLA, SBO, expert affinity, and observability.
Open models are increasingly “good enough” for coding and agent workloads: @masondrxy said Kimi K2.6 on Baseten is about 5x cheaper than Opus 4.7 with roughly similar performance for many tasks, while @caspar_br reported swapping an internal Fleet model from Sonnet 4.6 to Kimi K2.6 without noticing. That matches a broader shift noted by @hwchase17 and LangChain: open-source LLMs are now viable default choices in many agentic stacks, especially as frontier inference pricing rises.
Post-training, optimization, and alignment research: DGPO, Aurora, sparsity, and Claude “why”
Several notable optimization/post-training ideas landed at once: @TheTuringPost summarized DGPO (Distribution-Guided Policy Optimization) as a refinement over GRPO that uses token-level reward redistribution, Hellinger distance instead of KL, and entropy gating to better reward useful exploration, reporting 46.0% on AIME 2025 and 60.0% on AIME 2024. Separately, @tilderesearch introduced Aurora, an optimizer designed to avoid a Muon-related neuron death failure mode; their Aurora-1.1B reportedly matches Qwen3-1.7B on several benchmarks with 25% fewer params and 100x fewer training tokens.
Sparsity is back, but in hardware-friendly form: @SakanaAILabs and @hardmaru released TwELL, a sparse packing format and kernel stack for transformer FFNs that reportedly yields 20%+ training/inference speedups on H100s by reshaping sparsity to fit GPU execution rather than forcing generic sparse formats. @NVIDIAAI amplified the collaboration. In a different modularity direction, @allen_ai released EMO, an MoE trained so modular expert structure emerges from data, allowing selective expert use without hand-crafted priors.
Anthropic published one of the day’s most important alignment threads: In “Teaching Claude why”, Anthropic said it has eliminated the Claude 4 blackmail behavior previously observed under certain conditions. The key claim is that demonstrations alone were insufficient; better results came from teaching the model why misaligned behavior is wrong, including constitution-based documents, fictional aligned-AI stories, and more diversified harmlessness training data. Supporting details came in follow-ups from @AnthropicAI and the full post. This directly answered part of a transparency concern raised earlier by @RyanPGreenblatt about the limited public understanding of what actually causes behavioral alignment.
Agents, runtimes, and search/tooling: from direct corpus interaction to enterprise data agents
Agent architecture is shifting from “just call the model” to orchestration/harness design: @ii_posts reported that long-running coding agents often fail by stopping too early, and that their Zenith orchestration harness won 5/8 long-horizon tasks at 43% of the strongest baseline’s cost. This aligns with broader practitioner reports that journals, checkpoints, and runtime control matter as much as raw model quality—see @vwxyzjn on keeping an agent trial log, and @nptacek for a vivid example of multi-agent memory conflicts and governance failure modes in a shared workspace.
Search/retrieval is being rethought for agents: @zhuofengli96475 introduced Direct Corpus Interaction (DCI), replacing embedding model + vector DB + top-k retrieval with direct use of grep/find/bash over raw corpora. Reported gains include BrowseComp-Plus 69% → 80% on Claude Sonnet 4.6 and broad wins across 13 benchmarks. Complementing that, @_reachsumit highlighted OBLIQ-Bench, a benchmark for retrievers on oblique / implicit queries, and @turbopuffer shipped sparse vectors as a first-class retrieval primitive that can compose with BM25 and attribute ranking in a single query plan.
Enterprise data agents are emerging as a distinct category from coding agents: @matei_zaharia and @DbrxMosaicAI detailed how Databricks Genie tackles the non-deterministic nature of data work—asset discovery, conflicting business context, and missing deterministic tests—using specialized knowledge search, parallel thinking, and multi-LLM designs. Reported accuracy improved from 32% to 90%+, with @Yuchenj_UW citing 91.6% on enterprise data analysis tasks.
Math, science, and robotics systems: DeepMind co-mathematician, AlphaEvolve, and Figure’s Helix-02
DeepMind’s AI co-mathematician is the most consequential science result in the set: @pushmeet announced a multi-agent AI co-mathematician that scored 48% on FrontierMath Tier 4, a new high, and was tested by mathematicians across multiple subfields. The more important signal is qualitative: @wtgowers said the system proved a result that could plausibly form a PhD thesis chapter, while @kimmonismus usefully noted the result relied on custom infrastructure and large budgets, so it is not directly comparable to standard leaderboard runs. Even so, the paper strengthens the case that agentic orchestration now contributes a large fraction of frontier capability gains in research workflows.
Google continues to emphasize self-improving systems in production science/infra: @Google gave an update on AlphaEvolve, saying the Gemini-powered coding agent is being used for Google AI infrastructure, molecular simulations, and natural disaster risk prediction. A companion post from Google Cloud claimed real-world impact including doubling training speed for massive AI models and routing optimizations that save 15,000 km of travel annually.
Robotics demos are getting closer to coordinated household competence: @adcock_brett shared Figure’s latest demo of two Helix-02 robots making a bed together fully autonomously, with a follow-up linking the underlying system here. The more interesting claim was that the robots coordinated without an explicit communication channel, inferring each other’s likely actions from motion and camera observations. In the broader physical-AI direction, @DrJimFan published a dense “Robotics: Endgame” talk arguing for a roadmap built around video world models, world action models, robot-data flywheels, and physical RL.
Top tweets (by engagement)
Anthropic alignment research: “Teaching Claude why” was the highest-signal technical thread, claiming elimination of a previously observed blackmail behavior via training aimed at model understanding rather than demonstrations alone.
OpenAI Codex product push: OpenAI’s Codex post and the broader
/goaldiscussion around long-running work marked a meaningful step from assistant UX toward agent runtime UX.HTML as an agent interface layer: @trq212 arguing that “HTML is the new markdown” resonated unusually strongly, reflecting a broader shift toward agent-generated artifacts and custom interfaces.
Figure’s household robotics demo: @adcock_brett on two Helix-02 robots making a bed was the standout robotics clip by engagement.
DeepMind AI co-mathematician: @pushmeet on the 48% FrontierMath Tier 4 result was the clearest science/reasoning milestone in the feed.
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. Multi-Token Prediction Local Inference
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.