


Happy holidays! We’ll be sharing snippets from Latent Space LIVE! through the break bringing you the best of 2024! We want to express our deepest appreciation to event sponsors AWS, Daylight Computer, Thoth.ai, StrongCompute, Notable Capital, and most of all all our LS supporters who helped fund the gorgeous venue and A/V production!
For NeurIPS last year we did our standard conference podcast coverage interviewing selected papers (that we have now also done for ICLR and ICML), however we felt that we could be doing more to help AI Engineers 1) get more industry-relevant content, and 2) recap 2024 year in review from experts. As a result, we organized the first Latent Space LIVE!, our first in person miniconference, at NeurIPS 2024 in Vancouver.
Today, we’re proud to share Loubna’s highly anticipated talk (slides here)!
Synthetic Data
We called out the Synthetic Data debate at last year’s NeurIPS, and no surprise that 2024 was dominated by the rise of synthetic data everywhere:
Apple’s Rephrasing the Web1, Microsoft’s Phi 2-4 and Orca/AgentInstruct, Tencent’s Billion Persona dataset, DCLM, and HuggingFace’s FineWeb-Edu, and Loubna’s own Cosmopedia extended the ideas of synthetic textbook and agent generation to improve raw web scrape dataset quality
This year we also talked to the IDEFICS/OBELICS team at HuggingFace who released WebSight this year, the first work on code-vs-images synthetic data.
We called Llama 3.1 the Synthetic Data Model for its extensive use (and documentation!) of synthetic data in its pipeline, as well as its permissive license.
Nemotron CC and Nemotron-4-340B also made a big splash this year for how they used 20k items of human data to synthesize over 98% of the data used for SFT/PFT.
Cohere introduced Multilingual Arbitrage: Optimizing Data Pools to Accelerate Multilingual Progress observing gains of up to 56.5% improvement in win rates comparing multiple teachers vs the single best teacher model
In post training, AI2’s Tülu3 (discussed by Luca in our Open Models talk) and Loubna’s Smol Talk were also notable open releases this year.

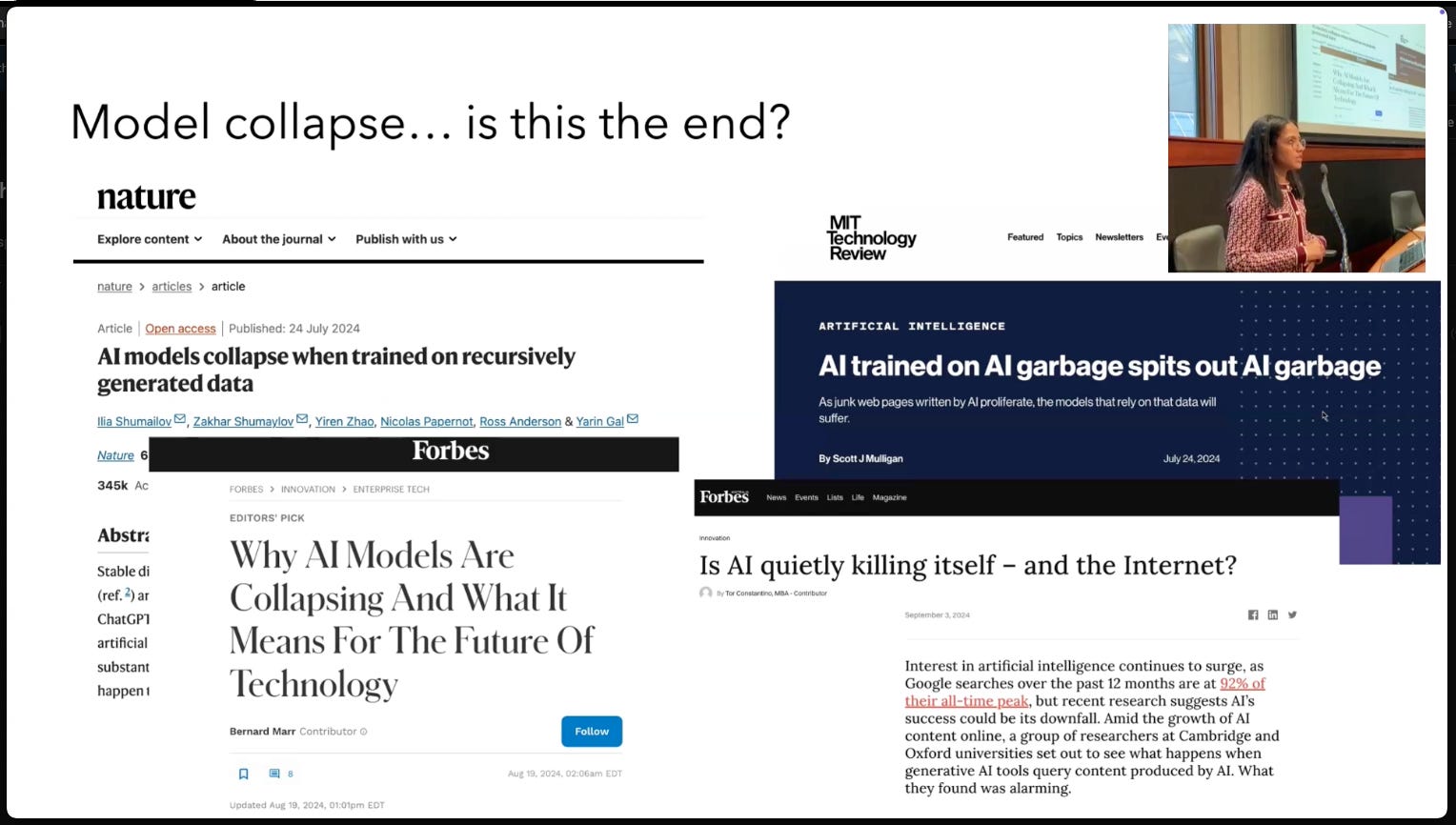
This comes in the face of a lot of scrutiny and criticism, with Scale AI as one of the leading voices publishing AI models collapse when trained on recursively generated data in Nature magazine bringing mainstream concerns to the potential downsides of poor quality syndata:
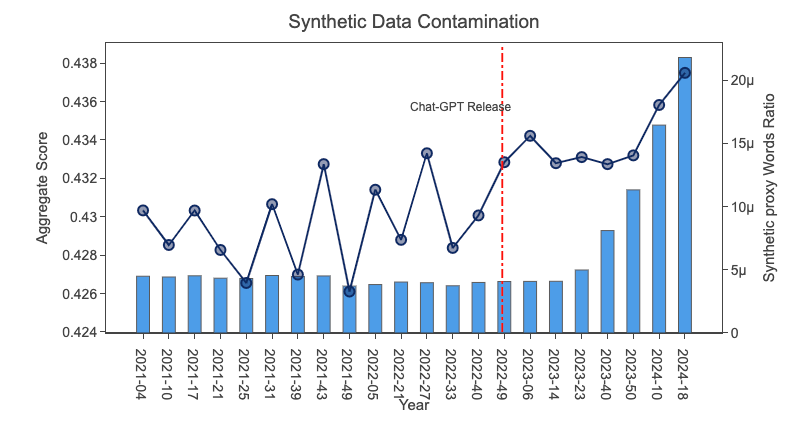
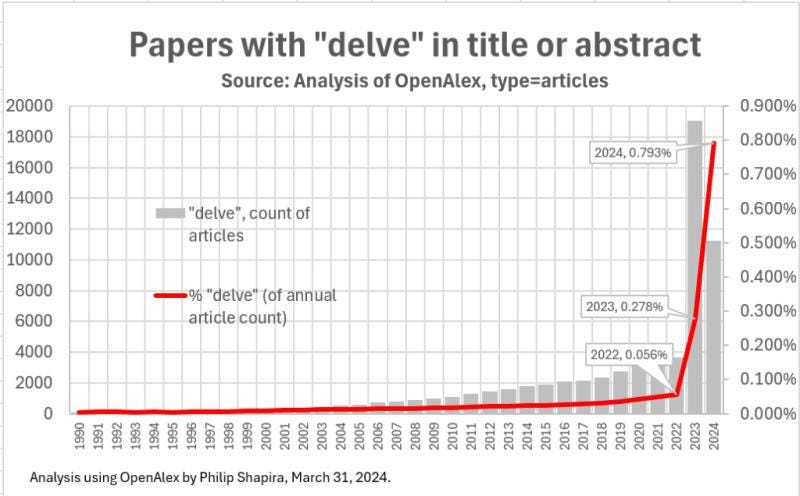
Part of the concerns we highlighted last year on low-background tokens are coming to bear: ChatGPT contaminated data is spiking in every possible metric:
We Are Running Out of Low-Background Tokens (Nov 2023 Recap)

The Latent Space crew will be at NeurIPS on Tuesday! Reach out with any parties and papers of interest. We have also been incubating a smol daily AI Newsletter and Latent Space University is making progress.
But perhaps, if Sakana’s AI Scientist pans out this year, we will have mostly-AI AI researchers publishing AI research anyway so do we really care as long as the ideas can be verified to be correct?2
Smol Models
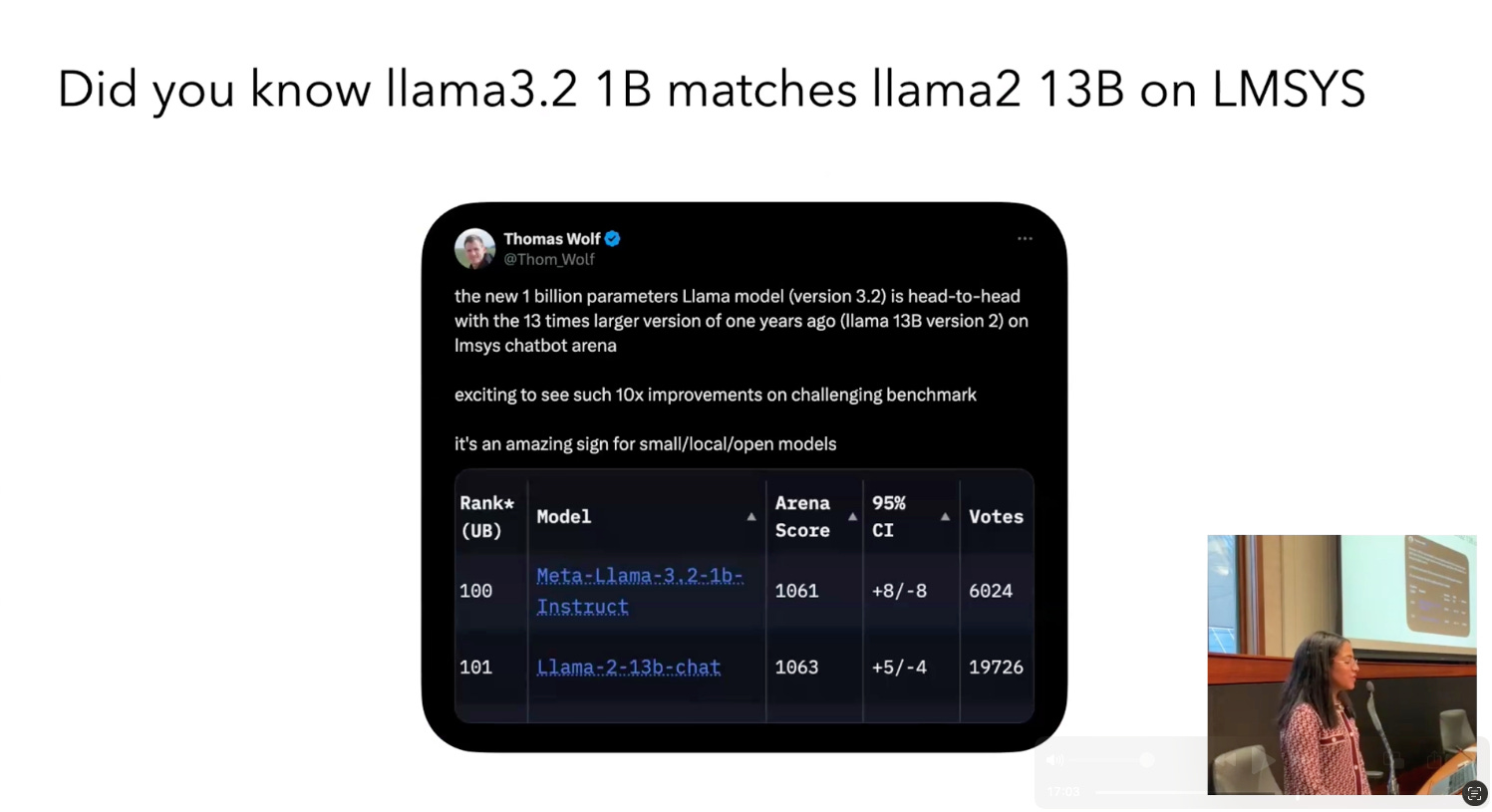
Meta surprised many folks this year by not just aggressively updating Llama 3 and adding multimodality, but also adding a new series of “small” 1B and 3B “on device” models this year, even working on quantized numerics collaborations with Qualcomm, Mediatek, and Arm. It is near unbelievable that a 1B model today can qualitatively match a 13B model of last year:
and the minimum size to hit a given MMLU bar has come down roughly 10x in the last year. We have been tracking this proxied by Lmsys Elo and inference price:

The key reads this year are:
MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases
Loubna’s SmolLM and SmolLM2: a family of state-of-the-art small models with 135M, 360M, and 1.7B parameters on the pareto efficiency frontier.
and Moondream, which we already covered in the 2024 in Vision talk
Full Talk on YouTube
Timestamps
[00:00:05] Loubna Intro
[00:00:33] The Rise of Synthetic Data Everywhere
[00:02:57] Model Collapse
[00:05:14] Phi, FineWeb, Cosmopedia - Synthetic Textbooks
[00:12:36] DCLM, Nemotron-CC
[00:13:28] Post Training - AI2 Tulu, Smol Talk, Cohere Multilingual Arbitrage
[00:16:17] Smol Models
[00:18:24] On Device Models
[00:22:45] Smol Vision Models
[00:25:14] What's Next
Transcript
2024 in Synthetic Data and Smol Models
[00:00:00]
[00:00:05] Loubna Intro
[00:00:05] Speaker: I'm very happy to be here. Thank you for the invitation. So I'm going to be talking about synthetic data in 2024. And then I'm going to be talking about small on device models. So I think the most interesting thing about synthetic data this year is that like now we have it everywhere in the large language models pipeline.
[00:00:33] The Rise of Synthetic Data Everywhere
[00:00:33] Speaker: I think initially, synthetic data was mainly used just for post training, because naturally that's the part where we needed human annotators. And then after that, we realized that we don't really have good benchmarks to [00:01:00] measure if models follow instructions well, if they are creative enough, or if they are chatty enough, so we also started using LLMs as judges.
[00:01:08] Speaker: Thank you. And I think this year and towards the end of last year, we also went to the pre training parts and we started generating synthetic data for pre training to kind of replace some parts of the web. And the motivation behind that is that you have a lot of control over synthetic data. You can control your prompt and basically also the kind of data that you generate.
[00:01:28] Speaker: So instead of just trying to filter the web, you could try to get the LLM to generate what you think the best web pages could look like and then train your models on that. So this is how we went from not having synthetic data at all in the LLM pipeline to having it everywhere. And so the cool thing is like today you can train an LLM with like an entirely synthetic pipeline.
[00:01:49] Speaker: For example, you can use our Cosmopedia datasets and you can train a 1B model on like 150 billion tokens that are 100 percent synthetic. And those are also of good quality. And then you can [00:02:00] instruction tune the model on a synthetic SFT dataset. You can also do DPO on a synthetic dataset. And then to evaluate if the model is good, you can use.
[00:02:07] Speaker: A benchmark that uses LLMs as a judge, for example, MTBench or AlpacaEvil. So I think this is like a really mind blowing because like just a few years ago, we wouldn't think this is possible. And I think there's a lot of concerns about model collapse, and I'm going to talk about that later. But we'll see that like, if we use synthetic data properly and we curate it carefully, that shouldn't happen.
[00:02:29] Speaker: And the reason synthetic data is very popular right now is that we have really strong models, both open and closed. It is really cheap and fast to use compared to human annotations, which cost a lot and take a lot of time. And also for open models right now, we have some really good inference frameworks.
[00:02:47] Speaker: So if you have enough GPUs, it's really easy to spawn these GPUs and generate like a lot of synthetic data. Some examples are VLM, TGI, and TensorRT.
[00:02:57] Model Collapse
[00:02:57] Speaker: Now let's talk about the elephant in the room, model [00:03:00] collapse. Is this the end? If you look at the media and all of like, for example, some papers in nature, it's really scary because there's a lot of synthetic data out there in the web.
[00:03:09] Speaker: And naturally we train on the web. So we're going to be training a lot of synthetic data. And if model collapse is going to happen, we should really try to take that seriously. And the other issue is that, as I said, we think, a lot of people think the web is polluted because there's a lot of synthetic data.
[00:03:24] Speaker: And for example, when we're building fine web datasets here at Guillerm and Hinek, we're interested in like, how much synthetic data is there in the web? So there isn't really a method to properly measure the amount of synthetic data or to save a webpage synthetic or not. But one thing we can do is to try to look for like proxy words, for example, expressions like as a large language model or words like delve that we know are actually generated by chat GPT.
[00:03:49] Speaker: We could try to measure the amount of these words in our data system and compare them to the previous years. For example, here, we measured like a, these words ratio in different dumps of common crawl. [00:04:00] And we can see that like the ratio really increased after chat GPT's release. So if we were to say that synthetic data amount didn't change, you would expect this ratio to stay constant, which is not the case.
[00:04:11] Speaker: So there's a lot of synthetic data probably on the web, but does this really make models worse? So what we did is we trained different models on these different dumps. And we then computed their performance on popular, like, NLP benchmarks, and then we computed the aggregated score. And surprisingly, you can see that the latest DOMs are actually even better than the DOMs that are before.
[00:04:31] Speaker: So if there's some synthetic data there, at least it did not make the model's worse. Yeah, which is really encouraging. So personally, I wouldn't say the web is positive with Synthetic Data. Maybe it's even making it more rich. And the issue with like model collapse is that, for example, those studies, they were done at like a small scale, and you would ask the model to complete, for example, a Wikipedia paragraph, and then you would train it on these new generations, and you would do that every day.
[00:04:56] Speaker: iteratively. I think if you do that approach, it's normal to [00:05:00] observe this kind of behavior because the quality is going to be worse because the model is already small. And then if you train it just on its generations, you shouldn't expect it to become better. But what we're really doing here is that we take a model that is very large and we try to distill its knowledge into a model that is smaller.
[00:05:14] Phi, FineWeb, Cosmopedia - Synthetic Textbooks
[00:05:14] Speaker: And in this way, you can expect to get like a better performance for your small model. And using synthetic data for pre-training has become really popular. After the textbooks are all you need papers where Microsoft basically trained a series of small models on textbooks that were using a large LLM.
[00:05:32] Speaker: And then they found that these models were actually better than models that are much larger. So this was really interesting. It was like first of its time, but it was also met with a lot of skepticism, which is a good thing in research. It pushes you to question things because the dataset that they trained on was not public, so people were not really sure if these models are really good or maybe there's just some data contamination.
[00:05:55] Speaker: So it was really hard to check if you just have the weights of the models. [00:06:00] And as Hugging Face, because we like open source, we tried to reproduce what they did. So this is our Cosmopedia dataset. We basically tried to follow a similar approach to what they documented in the paper. And we created a synthetic dataset of textbooks and blog posts and stories that had almost 30 billion tokens.
[00:06:16] Speaker: And we tried to train some models on that. And we found that like the key ingredient to getting a good data set that is synthetic is trying as much as possible to keep it diverse. Because if you just throw the same prompts as your model, like generate like a textbook about linear algebra, and even if you change the temperature, the textbooks are going to look alike.
[00:06:35] Speaker: So there's no way you could scale to like millions of samples. And the way you do that is by creating prompts that have some seeds that make them diverse. In our case, the prompt, we would ask the model to generate a textbook, but make it related to an extract from a webpage. And also we try to frame it within, to stay within topic.
[00:06:55] Speaker: For example, here, we put like an extract about cardiovascular bioimaging, [00:07:00] and then we ask the model to generate a textbook related to medicine that is also related to this webpage. And this is a really nice approach because there's so many webpages out there. So you can. Be sure that your generation is not going to be diverse when you change the seed example.
[00:07:16] Speaker: One thing that's challenging with this is that you want the seed samples to be related to your topics. So we use like a search tool to try to go all of fine web datasets. And then we also do a lot of experiments with the type of generations we want the model to generate. For example, we ask it for textbooks for middle school students or textbook for college.
[00:07:40] Speaker: And we found that like some generation styles help on some specific benchmarks, while others help on other benchmarks. For example, college textbooks are really good for MMLU, while middle school textbooks are good for benchmarks like OpenBookQA and Pico. This is like a sample from like our search tool.
[00:07:56] Speaker: For example, you have a top category, which is a topic, and then you have some [00:08:00] subtopics, and then you have the topic hits, which are basically the web pages in fine web does belong to these topics. And here you can see the comparison between Cosmopedia. We had two versions V1 and V2 in blue and red, and you can see the comparison to fine web, and as you can see throughout the training training on Cosmopedia was consistently better.
[00:08:20] Speaker: So we managed to get a data set that was actually good to train these models on. It's of course so much smaller than FineWeb, it's only 30 billion tokens, but that's the scale that Microsoft data sets was, so we kind of managed to reproduce a bit what they did. And the data set is public, so everyone can go there, check if everything is all right.
[00:08:38] Speaker: And now this is a recent paper from NVIDIA, Neumatron CC. They took things a bit further, and they generated not a few billion tokens, but 1. 9 trillion tokens, which is huge. And we can see later how they did that. It's more of, like, rephrasing the web. So we can see today that there's, like, some really huge synthetic datasets out there, and they're public, so, [00:09:00] like, you can try to filter them even further if you want to get, like, more high quality corpses.
[00:09:04] Speaker: So for this, rephrasing the web this approach was suggested in this paper by Pratyush, where basically in this paper, they take some samples from C4 datasets, and then they use an LLM to rewrite these samples into a better format. For example, they ask an LLM to rewrite the sample into a Wikipedia passage or into a Q& A page.
[00:09:25] Speaker: And the interesting thing in this approach is that you can use a model that is Small because it doesn't, rewriting doesn't require knowledge. It's just rewriting a page into a different style. So the model doesn't need to have like knowledge that is like extensive of what is rewriting compared to just asking a model to generate a new textbook and not giving it like ground truth.
[00:09:45] Speaker: So here they rewrite some samples from C4 into Q& A, into Wikipedia, and they find that doing this works better than training just on C4. And so what they did in Nemo Trans CC is a similar approach. [00:10:00] They rewrite some pages from Common Crawl for two reasons. One is to, like improve Pages that are low quality, so they rewrite them into, for example, Wikipedia page, so they look better.
[00:10:11] Speaker: And another reason is to create more diverse datasets. So they have a dataset that they already heavily filtered, and then they take these pages that are already high quality, and they ask the model to rewrite them in Question and Answer format. into like open ended questions or like multi choice questions.
[00:10:27] Speaker: So this way they can reuse the same page multiple times without fearing like having multiple duplicates, because it's the same information, but it's going to be written differently. So I think that's also a really interesting approach for like generating synthetic data just by rephrasing the pages that you already have.
[00:10:44] Speaker: There's also this approach called Prox where they try to start from a web page and then they generate a program which finds how to write that page to make it better and less noisy. For example, here you can see that there's some leftover metadata in the web page and you don't necessarily want to keep that for training [00:11:00] your model.
[00:11:00] Speaker: So So they train a model that can generate programs that can like normalize and remove lines that are extra. So I think this approach is also interesting, but it's maybe less scalable than the approaches that I presented before. So that was it for like rephrasing and generating new textbooks.
[00:11:17] Speaker: Another approach that I think is really good and becoming really popular for using synthetic data for pre training is basically building a better classifiers. For filtering the web for example, here we release the data sets called fine web edu. And the way we built it is by taking Llama3 and asking it to rate the educational content of web pages from zero to five.
[00:11:39] Speaker: So for example, if a page is like a really good textbook that could be useful in a school setting, it would get a really high score. And if a page is just like an advertisement or promotional material, it would get a lower score. And then after that, we take these synthetic annotations and we train a classifier on them.
[00:11:57] Speaker: It's a classifier like a BERT model. [00:12:00] And then we run this classifier on all of FineWeb, which is a 15 trillion tokens dataset. And then we only keep the pages that have like a score that's higher than 3. So for example, in our case, we went from 15 trillion tokens to 3. to just 1. 5 trillion tokens. Those are really highly educational.
[00:12:16] Speaker: And as you can see here, a fine web EDU outperforms all the other public web datasets by a larger margin on a couple of benchmarks here, I show the aggregated score and you can see that this approach is really effective for filtering web datasets to get like better corpuses for training your LLMs.
[00:12:36] DCLM, Nemotron-CC
[00:12:36] Speaker: Others also try to do this approach. There's, for example, the DCLM datasets where they also train the classifier, but not to detect educational content. Instead, they trained it on OpenHermes dataset, which is a dataset for instruction tuning. And also they explain like IAM5 subreddits, and then they also get really high quality dataset which is like very information dense and can help [00:13:00] you train some really good LLMs.
[00:13:01] Speaker: And then Nemotron Common Crawl, they also did this approach, but instead of using one classifier, they used an ensemble of classifiers. So they used, for example, the DCLM classifier, and also classifiers like the ones we used in FineWebEducational, and then they combined these two. Scores into a, with an ensemble method to only retain the best high quality pages, and they get a data set that works even better than the ones we develop.
[00:13:25] Speaker: So that was it for like synthetic data for pre-training.
[00:13:28] Post Training - AI2 Tulu, Smol Talk, Cohere Multilingual Arbitrage
[00:13:28] Speaker: Now we can go back to post training. I think there's a lot of interesting post training data sets out there. One that was released recently, the agent instructs by Microsoft where they basically try to target some specific skills. And improve the performance of models on them.
[00:13:43] Speaker: For example, here, you can see code, brain teasers, open domain QA, and they managed to get a dataset that outperforms that's when fine tuning Mistral 7b on it, it outperforms the original instruct model that was released by Mistral. And as I said, to get good synthetic data, you really [00:14:00] have to have a framework to make sure that your data is diverse.
[00:14:03] Speaker: So for example, for them, they always. And then they see the generations on either source code or raw text documents, and then they rewrite them to make sure they're easier to generate instructions from, and then they use that for their like instruction data generation. There's also the Tool3SFT mixture, which was released recently by Allen AI.
[00:14:23] Speaker: It's also really good quality and it covers a wide range of tasks. And the way they make sure that this dataset is diverse is by using personas from the persona hub datasets. Which is basically a data set of like I think over a million personas. And for example, in the tool mixture to generate like a new code snippet, they would give like the model persona, for example, a machine learning researcher interested in neural networks, and then ask it to generate like a coding problem.
[00:14:49] Speaker: This way you make sure that your data set is really diverse, and then you can further filter the data sets, for example, using the reward models. We also released a dataset called Smalltalk, [00:15:00] and we also tried to cover the wide range of tasks, and as you can see here, for example, when fine tuning Mistral 7b on the dataset, we also outperformed the original Mistral instructs on a number of benchmarks, notably on mathematics and instruction following with ifevil.
[00:15:18] Speaker: Another paper that's really interesting I wanted to mention is this one called Multilingual Data Arbitrage by Cohere. And basically they want to generate a data set for post training that is multilingual. And they have a really interesting problem. It's the fact that there isn't like one model that's really good at all the languages they wanted.
[00:15:36] Speaker: So what they do is that like they use not just one teacher model, but multiple teachers. And then they have a router which basically sends the prompts they have to all these models. And then they get the completions and they have a reward model that traces all these generations and only keeps the best one.
[00:15:52] Speaker: And this is like arbitrage and finance. So well, I think what's interesting in this, it shows that like synthetic data, it doesn't have to come from a single model. [00:16:00] And because we have so many good models now, you could like pull these models together and get like a dataset that's really high quality and that's diverse and that's covers all your needs.
[00:16:12] Speaker: I was supposed to put a meme there, but. Yeah, so that was it for like a synthetic data.
[00:16:17] Smol Models
[00:16:17] Speaker: Now we can go to see what's happening in the small models field in 2024. I don't know if you know, but like now we have some really good small models. For example, Lama 3. 2 1B is. It matches Lama 2. 13b from, that was released last year on the LMSYS arena, which is basically the default go to leaderboard for evaluating models using human evaluation.
[00:16:39] Speaker: And as you can see here, the scores of the models are really close. So I think we've made like hugely forward in terms of small models. Of course, that's one, just one data point, but there's more. For example, if you look at this chart from the Quint 2. 5 blog post, it shows that today we have some really good models that are only like 3 billion parameters [00:17:00] and 4 billion that score really high on MMLU.
[00:17:03] Speaker: Which is a really popular benchmark for evaluating models. And you can see here that the red, the blue dots have more than 65 on MMLU. And the grey ones have less. And for example, Llama33b had less. So now we have a 3b model that outperforms a 33b model that was released earlier. So I think now people are starting to realize that like, we shouldn't just scale and scale models, but we should try to make them more efficient.
[00:17:33] Speaker: I don't know if you knew, but you can also chat with a 3B plus model on your iPhone. For example, here, this is an app called PocketPal, where you can go and select a model from Hugging Face. It has a large choice. For example, here we loaded the 5. 3. 5, which is 3. 8 billion parameters on this iPhone. And we can chat with this and you can see that even the latency is also acceptable.
[00:17:57] Speaker: For example, here, I asked it to give me a joke about [00:18:00] NeurIPS. So let's see what it has to say.
[00:18:06] Speaker: Okay, why did the neural network attend NeurIPS? Because it heard there would be a lot of layers and fun and it wanted to train its sense of humor. So not very funny, but at least it can run on device. Yeah, so I think now we have good small models, but we also have like good frameworks and tools to use these small models.
[00:18:24] On Device Models
[00:18:24] Speaker: So I think we're really close to having like really on edge and on device models that are really good. And I think for a while we've had this narrative. But just training larger models is better. Of course, this is supported by science scaling laws. As you can see here, for example, when we scale the model size, the loss is lower and obviously you get a better model.
[00:18:46] Speaker: But and we can see this, for example, in the GPT family of models, how we went from just a hundred million parameters to more than a trillion. parameters. And of course, we all observed the performance improvement when using the latest model. But [00:19:00] one thing that we shouldn't forget is that when we scale the model, we also scale the inference costs and time.
[00:19:05] Speaker: And so the largest models were are going to cost so much more. So I think now instead of just building larger models, we should be focusing on building more efficient models. It's no longer a race for the largest models since these models are really expensive to run and they require like a really good infrastructure to do that and they cannot run on, for example, consumer hardware.
[00:19:27] Speaker: And when you try to build more efficient models that match larger models, that's when you can really unlock some really interesting on device use cases. And I think a trend that we're noticing now is the trend of training smaller models longer. For example, if you compare how much, how long LLAMA was trained compared to LLAMA3, there is a huge increase in the pre training length.
[00:19:50] Speaker: LLAMA was trained on 1 trillion tokens, but LLAMA3 8b was trained on 15 trillion tokens. So Meta managed to get a model that's the same size, but But it performs so much [00:20:00] better by choosing to like spend the sacrifice during training, because as we know, training is a one time cost, but inference is something that's ongoing.
[00:20:08] Speaker: If we want to see what are like the small models reads in 2024, I think this mobile LLM paper by Meta is interesting. They try to study different models that are like have the less than 1 billion parameters and find which architecture makes most sense for these models. For example, they find that depth is more important than width.
[00:20:29] Speaker: So it's more important to have models that have like more layers than just one. making them more wide. They also find that GQA helps, that tying the embedding helps. So I think it's a nice study overall for models that are just a few hundred million parameters. There's also the Apple intelligence tech report, which is interesting.
[00:20:48] Speaker: So for Apple intelligence, they had two models, one that was like on server and another model that was on device. It had 3 billion parameters. And I think the interesting part is that they trained this model using [00:21:00] pruning. And then distillation. And for example, they have this table where they show that, like, using pruning and distillation works much better than training from scratch.
[00:21:08] Speaker: And they also have some interesting insights about, like, how they specialize their models on specific tasks, like, for example, summarization and rewriting. There's also this paper by NVIDIA that was released recently. I think you've already had a talk about, like, hybrid models that was all interesting.
[00:21:23] Speaker: And this model, they used, like, a hybrid architecture between state space models and transformers. And they managed to train a 1B model that's really performant without needing to train it on a lot of tokens. And regarding our work, we just recently released SmallM2, so it's a series of three models, which are the best in class in each model size.
[00:21:46] Speaker: For example, our 1. 7b model outperforms Lama 1b and also Qt 2. 5. And how we managed to train this model is the following. That's where you spent a lot of time trying to curate the pre training datasets. We did a lot of [00:22:00] ablations, trying to find which datasets are good and also how to mix them. We also created some new math and code datasets that we're releasing soon.
[00:22:08] Speaker: But you basically really spent a lot of time trying to find what's the best mixture that you can train these models on. And then we spent some time trying to like we also trained these models for very long. For example, small M1 was trained only on 1 trillion tokens, but this model is trained on 11 trillion tokens.
[00:22:24] Speaker: And we saw that the performance kept improving. The models didn't really plateau mid training, which I think is really interesting. It shows that you can train such small models for very long and keep getting performance gains. What's interesting about SmallLM2 is that it's fully open. We also released, like the pre training code base, the fine tuning code, the datasets, and also evaluation in this repository.
[00:22:45] Smol Vision Models
[00:22:45] Speaker: Also there's, like, really interesting small models for text, but also for vision. For example, here you can see SmallVLM, which is a 2B model that's really efficient. It doesn't consume a lot of RAM, and it also has a good performance. There's also Moondream 0. [00:23:00] 5b, which was released recently. It's like the smallest visual language model.
[00:23:04] Speaker: And as you can see, there isn't like a big trade off compared to Moondream 2b. So now I showed you that we have some really good small models. We also have the tools to use them, but why should you consider using small models and when? I think, like, small models are really interesting because of the on device feature.
[00:23:23] Speaker: Because these models are small and they can run fast, you can basically run them on your laptop, but also on your mobile phone. And this means that your dataset stays locally. You don't have to send your queries to third parties. And this really enhances privacy. That was, for example, one of the big selling points for Apple Intelligence.
[00:23:42] Speaker: Also, right now, we really have a lot of work to do. So many frameworks to do on device inference. For example, there's MLX, MLC, Llama, CPP, Transformers, JS. So we have a lot of options and each of them have like great features. So you have so many options for doing that. Small models are also really powerful if you choose to specialize them.[00:24:00]
[00:24:00] Speaker: For example, here there's a startup called Numind, which took small LM and then they fine tuned it on text extraction datasets. And they managed to get a model that's not very far from models that are much larger. So I think text extraction is like one use case where small models can be really performant and it makes sense to use them instead of just using larger models.
[00:24:19] Speaker: You can also chat with these models in browser. For example, here, you can go there, you can load the model, you can even turn off your internet and just start chatting with the model locally. Speaking of text extraction, if you don't want to fine tune the models, there's a really good method of structure generation.
[00:24:36] Speaker: We can basically force the models to follow a JSON schema that you defined. For example, here, we try to force the model to follow a schema for extracting key information from GitHub issues. So you can input free text, which is a complaint about a GitHub repository, something not working. And then you can run it there and the model can extract anything that is relevant for your GitHub issue creation.
[00:24:58] Speaker: For example, the [00:25:00] priority, for example, here, priority is high, the type of the issue bug, and then a title and the estimation of how long this will take to fix. And you can just like do this in the browser, you can transform your text into a GitHub issue that's properly formatted.
[00:25:14] What's Next
[00:25:14] Speaker: So what's next for synthetic data and small models?
[00:25:18] Speaker: I think that domain specific synthetic data is going to be, it's already important, it's going to be even more important. For example, generating synthetic data for math. I think this really would help improve the reasoning of a lot of models. And a lot of people are doing it, for example, Quint 2. 12 math, everyone's trying to reproduce a one.
[00:25:37] Speaker: And so I think for synthetic data, trying to specialize it on some domains is going to be really important. And then for small models, I think specializing them through fine tuning, it's also going to be really important because I think a lot of companies are just trying to use these large models because they are better.
[00:25:53] Speaker: But on some tasks, I think you can already get decent performance with small models. So you don't need to Pay like a [00:26:00] cost that's much larger just to make your model better at your task by a few percent. And this is not just for text. And I think it also applies for other modalities like vision and audio.
[00:26:11] Speaker: And I think you should also watch out for on device frameworks and applications. For example, like the app I showed, or lama, all these frameworks are becoming really popular and I'm pretty sure that we're gonna get like more of them in 2025. And users really like that. Maybe for other, I should also say hot take.
[00:26:28] Speaker: I think that like in AI, we just started like with fine tuning, for example, trying to make BERT work on some specific use cases, and really struggling to do that. And then we had some models that are much larger. So we just switched to like prompt engineering to get the models And I think we're going back to fine tuning where we realize these models are really costly.
[00:26:47] Speaker: It's better to use just a small model or try to specialize it. So I think it's a little bit of a cycle and we're going to start to see like more fine tuning and less of just like a prompt engineering the models. So that was my talk. Thank you for following. And if you have [00:27:00] any questions, we can take them now.
There is the small concern of the asymmetry of Brandolini’s law.

Share this post