


Happy holidays! We’ll be sharing snippets from Latent Space LIVE! through the break bringing you the best of 2024! We want to express our deepest appreciation to event sponsors AWS, Daylight Computer, Thoth.ai, StrongCompute, Notable Capital, and most of all all our LS supporters who helped fund the gorgeous venue and A/V production!
Update: see followup discussion on HN and also the YouTube discussion.
For NeurIPS last year we did our standard conference podcast coverage interviewing selected papers (that we have now also done for ICLR and ICML), however we felt that we could be doing more to help AI Engineers 1) get more industry-relevant content, and 2) recap 2024 year in review from experts. As a result, we organized the first Latent Space LIVE!, our first in person miniconference, at NeurIPS 2024 in Vancouver.
Of perennial interest, particularly at academic conferences, is scaled-up architecture research as people hunt for the next Attention Is All You Need. We have many names for them: “efficient models”, “retentive networks”, “subquadratic attention” or “linear attention” but some of them don’t even have any lineage with attention - one of the best papers of this NeurIPS was Sepp Hochreiter’s xLSTM, which has a particularly poetic significance as one of the creators of the LSTM returning to update and challenge the OG language model architecture:
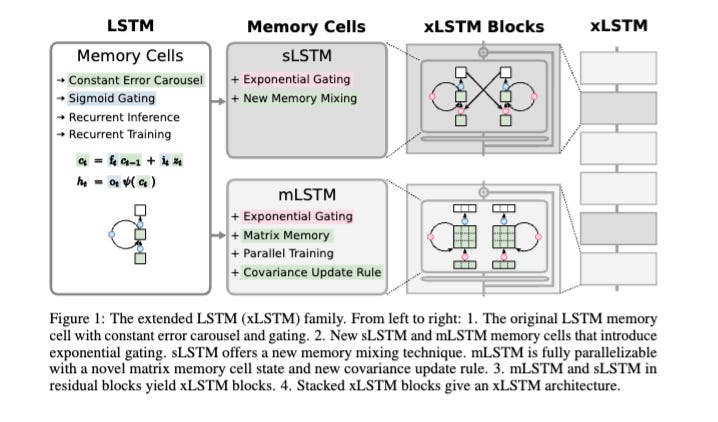
So, for lack of a better term, we decided to call this segment “the State of Post-Transformers” and fortunately everyone rolled with it.
We are fortunate to have two powerful friends of the pod to give us an update here:
Together AI: with CEO Vipul Ved Prakash and CTO Ce Zhang joining us to talk about how they are building Together together as a quote unquote full stack AI startup, from the lowest level kernel and systems programming to the highest level mathematical abstractions driving new model architectures and inference algorithms, with notable industry contributions from RedPajama v2, Flash Attention 3, Mamba 2, Mixture of Agents, BASED, Sequoia, Evo, Dragonfly, Dan Fu's ThunderKittens and many more research projects this year
Recursal AI: with CEO Eugene Cheah who has helped lead the independent RWKV project while also running Featherless AI. This year, the team has shipped RWKV v5, codenamed Eagle, to 1.5 billion Windows 10 and Windows 11 machines worldwide, to support Microsoft's on-device, energy-usage-sensitive Windows Copilot usecases, and has launched the first updates on RWKV v6, codenamed Finch and GoldFinch. On the morning of Latent Space Live, they also announced QRWKV6, a Qwen 32B model modified with RWKV linear attention layers.
We were looking to host a debate between our speakers, but given that both of them were working on post-transformers alternatives
Full Talk on Youtube
Links
All the models and papers they picked:
Earlier Cited Work
Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention
Hungry hungry hippos: Towards language modeling with state space models
Hyena hierarchy: Towards larger convolutional language models
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
S4: Efficiently Modeling Long Sequences with Structured State Spaces
Just Read Twice (Arora et al)
Recurrent large language models that compete with Transformers in language modeling perplexity are emerging at a rapid rate (e.g., Mamba, RWKV). Excitingly, these architectures use a constant amount of memory during inference. However, due to the limited memory, recurrent LMs cannot recall and use all the information in long contexts leading to brittle in-context learning (ICL) quality. A key challenge for efficient LMs is selecting what information to store versus discard. In this work, we observe the order in which information is shown to the LM impacts the selection difficulty.
To formalize this, we show that the hardness of information recall reduces to the hardness of a problem called set disjointness (SD), a quintessential problem in communication complexity that requires a streaming algorithm (e.g., recurrent model) to decide whether inputted sets are disjoint. We empirically and theoretically show that the recurrent memory required to solve SD changes with set order, i.e., whether the smaller set appears first in-context.
Our analysis suggests, to mitigate the reliance on data order, we can put information in the right order in-context or process prompts non-causally. Towards that end, we propose: (1) JRT-Prompt, where context gets repeated multiple times in the prompt, effectively showing the model all data orders. This gives 11.0±1.3 points of improvement, averaged across 16 recurrent LMs and the 6 ICL tasks, with 11.9× higher throughput than FlashAttention-2 for generation prefill (length 32k, batch size 16, NVidia H100). We then propose (2) JRT-RNN, which uses non-causal prefix-linear-attention to process prompts and provides 99% of Transformer quality at 360M params., 30B tokens and 96% at 1.3B params., 50B tokens on average across the tasks, with 19.2× higher throughput for prefill than FA2.
Jamba: A 52B Hybrid Transformer-Mamba Language Model
We present Jamba, a new base large language model based on a novel hybrid Transformer-Mamba mixture-of-experts (MoE) architecture.
Specifically, Jamba interleaves blocks of Transformer and Mamba layers, enjoying the benefits of both model families. MoE is added in some of these layers to increase model capacity while keeping active parameter usage manageable.
This flexible architecture allows resource- and objective-specific configurations. In the particular configuration we have implemented, we end up with a powerful model that fits in a single 80GB GPU.
Built at large scale, Jamba provides high throughput and small memory footprint compared to vanilla Transformers, and at the same time state-of-the-art performance on standard language model benchmarks and long-context evaluations. Remarkably, the model presents strong results for up to 256K tokens context length.
We study various architectural decisions, such as how to combine Transformer and Mamba layers, and how to mix experts, and show that some of them are crucial in large scale modeling. We also describe several interesting properties of these architectures which the training and evaluation of Jamba have revealed, and plan to release checkpoints from various ablation runs, to encourage further exploration of this novel architecture. We make the weights of our implementation of Jamba publicly available under a permissive license.
SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers
We introduce Sana, a text-to-image framework that can efficiently generate images up to 4096×4096 resolution. Sana can synthesize high-resolution, high-quality images with strong text-image alignment at a remarkably fast speed, deployable on laptop GPU. Core designs include:
(1) Deep compression autoencoder: unlike traditional AEs, which compress images only 8×, we trained an AE that can compress images 32×, effectively reducing the number of latent tokens.
(2) Linear DiT: we replace all vanilla attention in DiT with linear attention, which is more efficient at high resolutions without sacrificing quality.
(3) Decoder-only text encoder: we replaced T5 with modern decoder-only small LLM as the text encoder and designed complex human instruction with in-context learning to enhance the image-text alignment.
(4) Efficient training and sampling: we propose Flow-DPM-Solver to reduce sampling steps, with efficient caption labeling and selection to accelerate convergence.
As a result, Sana-0.6B is very competitive with modern giant diffusion model (e.g. Flux-12B), being 20 times smaller and 100+ times faster in measured throughput. Moreover, Sana-0.6B can be deployed on a 16GB laptop GPU, taking less than 1 second to generate a 1024×1024 resolution image. Sana enables content creation at low cost.
RWKV: Reinventing RNNs for the Transformer Era
Transformers have revolutionized almost all natural language processing (NLP) tasks but suffer from memory and computational complexity that scales quadratically with sequence length. In contrast, recurrent neural networks (RNNs) exhibit linear scaling in memory and computational requirements but struggle to match the same performance as Transformers due to limitations in parallelization and scalability.
We propose a novel model architecture, Receptance Weighted Key Value (RWKV), that combines the efficient parallelizable training of transformers with the efficient inference of RNNs.
Our approach leverages a linear attention mechanism and allows us to formulate the model as either a Transformer or an RNN, thus parallelizing computations during training and maintains constant computational and memory complexity during inference.
We scale our models as large as 14 billion parameters, by far the largest dense RNN ever trained, and find RWKV performs on par with similarly sized Transformers, suggesting future work can leverage this architecture to create more efficient models. This work presents a significant step towards reconciling trade-offs between computational efficiency and model performance in sequence processing tasks.
LoLCATs: On Low-Rank Linearizing of Large Language Models
Recent works show we can linearize large language models (LLMs) -- swapping the quadratic attentions of popular Transformer-based LLMs with subquadratic analogs, such as linear attention -- avoiding the expensive pretraining costs. However, linearizing LLMs often significantly degrades model quality, still requires training over billions of tokens, and remains limited to smaller 1.3B to 7B LLMs.
We thus propose Low-rank Linear Conversion via Attention Transfer (LoLCATs), a simple two-step method that improves LLM linearizing quality with orders of magnitudes less memory and compute.
We base these steps on two findings.
First, we can replace an LLM's softmax attentions with closely-approximating linear attentions, simply by training the linear attentions to match their softmax counterparts with an output MSE loss ("attention transfer").
Then, this enables adjusting for approximation errors and recovering LLM quality simply with low-rank adaptation (LoRA).
LoLCATs significantly improves linearizing quality, training efficiency, and scalability. We significantly reduce the linearizing quality gap and produce state-of-the-art subquadratic LLMs from Llama 3 8B and Mistral 7B v0.1, leading to 20+ points of improvement on 5-shot MMLU.
Furthermore, LoLCATs does so with only 0.2% of past methods' model parameters and 0.4% of their training tokens.
Finally, we apply LoLCATs to create the first linearized 70B and 405B LLMs (50x larger than prior work).
When compared with prior approaches under the same compute budgets, LoLCATs significantly improves linearizing quality, closing the gap between linearized and original Llama 3.1 70B and 405B LLMs by 77.8% and 78.1% on 5-shot MMLU.
Timestamps
[00:02:27] Intros
[00:03:16] Why Scale Context Lengths? or work on Efficient Models
[00:06:07] The Story of SSMs
[00:09:33] Idea 1: Approximation -> Principled Modeling
[00:12:14] Idea 3: Selection
[00:15:07] Just Read Twice
[00:16:51] Idea 4: Test Time Compute
[00:17:32] Idea 2: Hardware & Kernel Support
[00:19:49] RWKV vs SSMs
[00:24:24] RWKV Arch
[00:26:15] QWRKWv6 launch
[00:30:00] What's next
[00:33:21] Hot Takes - does anyone really need long context?
Transcript
[00:00:00] AI Charlie: We're back at Latent Space Live, our first mini conference held at NeurIPS 2024 in Vancouver. This is Charlie, your AI co host. As a special treat this week, we're recapping the best of 2024 going domain by domain. We sent out a survey to the over 900 of you who told us what you wanted, and then invited the best speakers in the Latent Space Network to cover each field.
[00:00:24] AI Charlie: 200 of you joined us in person throughout the day, with over 2200 watching live online. Thanks Our next keynote covers the State of Transformers alternative architectures, with a special joint presentation with Dan Fu of Together AI and Eugene Chia of Recursal AI and Featherless AI. We've featured both Together and Recursal on the pod before, with CEO Veepal Vedprakash introducing them.
[00:00:49] AI Charlie: And CTO CE Zhang joining us to talk about how they are building together together as a quote unquote full stack AI startup from the lowest level kernel and systems [00:01:00] programming to the highest level mathematical abstractions driving new model architectures and inference algorithms with notable industry contributions from Red Pajama V2, Flash Attention 3, Mamba 2, Mixture of Agents.
[00:01:15] AI Charlie: Based, Sequoia, Evo, Dragonfly, Danfoo's Thunder Kittens, and many more research projects this year. As for Recursal and Featherless, we were the first podcast to feature RWKV last year, and this year the team has shipped RWKV v5, codenamed Eagle, to 1. 5 billion Windows 10 and Windows 11 machines worldwide to support Microsoft's on device, end Energy Usage Sensitive Windows Copilot Use Cases and has launched the first updates on RWKV v6, codenamed Finch and Goldfinch.
[00:01:53] AI Charlie: On the morning of Latent Space Live, they also announced QRdata UKv6, a QEN32B model [00:02:00] modified with RDWKV linear attention layers. Eugene has also written the most single most popular guest post on the Latent Space blog this year. Yes, we do take guest posts on what he has discovered about the H100 GPU inference NeoCloud market since the successful launch of Featherless AI this year.
[00:02:20] AI Charlie: As always, don't forget to check the show notes for the YouTube link to their talk as well as their slides. Watch out and take care.
[00:02:27] Intros
[00:02:27] Dan Fu: Yeah, so thanks so much for having us. So this is going to be a little bit of a two part presentation. My name is Dan. I'm at Together AI, and I'll be joining UCSD as faculty in about a year. And Eugene, you want to introduce yourself?
[00:02:46] Eugene Cheah: Eugene, I lead the art activity team, and I, I'm CEO of Featherless, and we both work on this new post transformer architecture space.
[00:02:55] Dan Fu: Yeah, so yeah, so today we're really excited to talk to you a little bit [00:03:00] about that. So first I'm going to give a broad overview of kind of the last few years of progress in non post transformer architectures. And then afterwards Eugene will tell us a little bit about the latest and the greatest and the latest frontier models in this space.
[00:03:16] Why Scale Context Lengths? or work on Efficient Models
[00:03:16] Dan Fu: So, the story starts with Scaling. So this is probably a figure or something like this that you've seen very recently. Over the last five to six years, we've seen models really scale up in parameter size, and that's brought with it a bunch of new capabilities, like the ability to talk to you and tell you sometimes how to use your Colab screens.
[00:03:35] Dan Fu: But another place where we've seen scaling especially recently is scaling in context length. So this can mean Having more text inputs for your models, but it can also mean things like taking a lot of visual token inputs image inputs to your models or generating lots of outputs. And one thing that's been really exciting over the last few months or so is that we're, we're seeing scaling, not only during training time, but also [00:04:00] during test time.
[00:04:00] Dan Fu: So this is one of the, the, this is the iconic image from the OpenAI 01 release. Not only are we starting to scale train time compute, but we're also starting to scale test time compute. Now if you're familiar with our attention and our transformer architectures today, this graph on the right might look a little bit scary.
[00:04:19] Dan Fu: And one of the reasons is that the implications are a little bit Interesting. So what does it mean if we want to continue having smarter and smarter models? Do we just need to start building bigger, bigger data centers, spending more flops? Is this this little Dolly 3, we need more flops, guys? Is this going to be the future of all of AI?
[00:04:39] Dan Fu: Or is there a better way, another path forward? Maybe we can get the same capabilities that we've gotten used to, But for a lot less compute, a lot less flops. And one of the things that we're going to talk about today is specifically looking at that core attention operator in some of these models.
[00:04:57] Dan Fu: And the reason is that so this is just some, some [00:05:00] basic you know, scaling curves, but attention has compute that scales quadratically in the context length. So that means that if you're doing something like test time compute and you want to spend a bunch of tokens thinking about what comes next, the longer that that goes the, the, the more tokens you spend on that, that compute grows quadratically in that.
[00:05:19] Dan Fu: One of the questions that we're interested in is, can we take that basic sequence model, that basic sequence primitive at the bottom, and get it to scale better? Can we scale in, let's say, n to the 3 halves or n log n? So in, in the first part of the talk, so we just went over the introduction. What I'm gonna do over the next few slides is just talk about some of the key advances and ideas that have shown over the past few years since maybe early 2020 to, to now that shown promise that this might actually be possible.
[00:05:48] Dan Fu: That you can actually get potentially the same quality that we want while scale, while scaling better. So to do that, we're and, and basically the, the story that we're gonna look is we're gonna start to see [00:06:00] how. So this is a basic graph of just the past couple years of progress of perplexity where that blue line, that dotted blue line, is attention.
[00:06:07] The Story of SSMs
[00:06:07] Dan Fu: It's your basic transformer, full dense attention. And then the dots coming down are some of the methods that you'll see in this presentation today. We're going to turn the clock back all the way to 2020. So this, this, this question of can we make attention subquadratic? Basically, as soon as we said attention is all you need, People started asking this question.
[00:06:28] Dan Fu: So we have this quadratic attention operator. Can we do better? I'll briefly talk about why attention is quadratic. And the basic thing that happens, if you're not familiar, is that you have these inputs, these keys and queries. And what you do in this attention matrix, this S matrix over here, is that you're using, you're comparing every token in your input to every other token.
[00:06:49] Dan Fu: So when I try to do something like upload a whole book to Gemini, what happens beyond the Maybe not Gemini, because we don't necessarily know what architecture is. But let's say we upload it to LLAMA, what happens beyond [00:07:00] the scenes, behind the scenes, is that it's going to take every single word in that book and compare it to every other word.
[00:07:05] Dan Fu: And this has been a really, it's, it's led to some pretty impressive things. But it's kind of a brute forcing of the way that you would try to interpret a interpret something. And what attention does in particular is the, and then what attention, sorry, don't want to. Okay, no, no laser pointer. What, what attention does afterwards is that instead of always operating in this quadratic thing, it takes a row wise softmax over this matrix, and then multiplies it by this values matrix.
[00:07:32] Dan Fu: So, one of the key points to notice is that the output size is always going to be the same as the inputs, at least in standard self attention. So one of the first things that folks tried to do around 2020 is this thing called linear attention, which is just, just noticing that if we take out this softmax from here, if we take out this non linearity in the middle of the attention operation, and then if you compute the keys and the values operation first, you actually never hit this quadratic bottleneck.
[00:07:57] Dan Fu: So that, that's potentially a way [00:08:00] to get a lot more computationally efficient. And there are various ways to do this by basically using feature maps or try to approximate this overall attention computation. But some of this work sort of started to hit a wall in 2020. And the basic challenges were, were two.
[00:08:16] Dan Fu: So one was quality. It was back then, it was kind of hard to, to get good quality with these linear attention operators. The other one was actually hardware efficiency. So these, this feature map that was just shown by a simplify simplify here. Actually ends up being quite computationally expensive if you just implement it naively.
[00:08:34] Dan Fu: So you started having these operators that not only were you sure, you're not really sure if they have the same quality, but also they're actually just wall clock slower. So you kind of end up getting the worst of both worlds. So this was the the stage. So that kind of sets the stage for four years ago.
[00:08:49] Dan Fu: Keep this in mind because linear attention is actually going to come back in a few years once we have a better understanding. But one of the works that started kicking off this, this [00:09:00] mini revolution in post transformer architectures was this idea called states based model. So here the seminal work is, is one about our work queue in 2022.
[00:09:09] Dan Fu: And this, this piece of work really brought together a few ideas from, from some long running research research lines of work. The first one was, and this is really one of the keys to, to closing the gap in quality was just using things that, that if you talk to a, a, an electrical engineer off the street, they might know off, off the, like the back of their hand.
[00:09:33] Idea 1: Approximation -> Principled Modeling
[00:09:33] Dan Fu: But taking some of those properties with how we model dynamical systems in signal processing and then using those ideas to model the inputs, the, the text tokens in, for example a transformer like Next Token Prediction Architecture. So some of those early states-based model papers were looking at this relatively, relatively simple recurrent update model that comes from maybe chapter one of a signal processing class.
[00:09:59] Dan Fu: But then using [00:10:00] some principle theory about how you should do that recurrent update in order to really get the most that you can out of your hidden state, out of your out of your sequence. So that, that was one key idea for quality and. When this was eventually realized, you started to see a bunch of benchmarks that were pretty sticky for a few years.
[00:10:20] Dan Fu: Things like long range arena, some long sequence evaluation benchmarks, There was stuff in time series, time series analysis. They started to, you started to see the quality tick up in meaningful ways. But the other key thing that What's so influential about these states based models is that they also had a key idea about how you can compute these things efficiently.
[00:10:45] Dan Fu: So if you go back to your machine learning 101 class where you learned about RNNs, one thing that you may have learned is that they don't paralyze as well as detention, because if you just run them naively, you have to do this kind of sequential update to process new tokens, [00:11:00] whereas in attention, you can process all the tokens in parallel at one time.
[00:11:04] Dan Fu: One of the key insights behind the S4 paper was that these recurrent models, you could take them and you could also formulate them as a convolution. And in particular, with a convolution, you could, instead of using a PyTorch conv1d operation, you can compute that with the FFT. And that would give you n log n compute in the in the sequence length n with an operator that was relatively well optimized for modern hardware.
[00:11:28] Dan Fu: So those are really, I'd say, the two key ideas in 2022 that started allowing these breakthroughs to happen in these non transformer architectures. So, these ideas about how to principally model sorry, how to model the recurrent updates of a mo of, of a sequence in a principled way, and also these key ideas in how you can compute it efficiently by turning it into a convolution and then scaling it up with the FFT.
[00:11:53] Dan Fu: Along those same lines, so afterwards we started putting out some work on specialized kernels, so just [00:12:00] like we have flash attention for transformers, we also have works like flash fft conf, and if you look at these lines of work oftentimes when, whenever you see a new architecture, you see a new primitive one of the, one of the table stakes now is, do you have an efficient kernel so that you can actually get wall clock speed up?
[00:12:14] Idea 3: Selection
[00:12:14] Dan Fu: So by 2022, We are starting to have these models that had promising quality primitives, but and, and also promising wall clocks. So you could actually see regimes where they were better than transformers in meaningful ways. That being said, there were, there's still sometimes a quality gap, particularly for language modeling.
[00:12:33] Dan Fu: And because languages, It's so core to what we do in sequence modeling these days the, the next, the next key idea that I'm going to talk about is this idea of selection mechanisms. And this is basically an idea of, so you have this recurrent state that you're keeping around that just summarizes everything that, that came before.
[00:12:50] Dan Fu: And to get a good sequence model, one of the things that you really need to be able to do is have the model learn what's the best way to pick out pieces from that recurrent [00:13:00] state. So one of the, one of the major ideas here in a line of work called H3, Hungry Hungry Hippos, and also these hyena models were One way you can do this is by just adding some simple element wise gates.
[00:13:13] Dan Fu: So versions of these ideas have been around for decades. If you squint at the LSTM paper you, you can probably find, find this gating mechanism. But turns out you can take those old ideas, add them into these new. state space models, and then you can see quality start to pick up. If you've heard of the Mamba model, this also takes the selection to the next level by actually making some changes in that fundamental recurrent state space.
[00:13:40] Dan Fu: So, it's not only just this gating that happens around the SSM layer, but also you can actually make The ABCD matrices of your state space model, you can make them data dependent, which will allow you to even better select out different pieces from your hidden state depending on what you're seeing. I'll also point out if you look at the [00:14:00] bottom right of this figure, there's this little triangle with a GPU SRAM, GPU HBM, and this, this is just continuing that trend of when you have a new architecture you, you, you also release it with a kernel to, to, to show that it is hardware efficient, that it, that it can be hardware efficient on modern hardware.
[00:14:17] Dan Fu: The, the, one of the next cool things that happened is once we had this understanding of these are the basic pieces, these are the basic principles behind some of the sequence models linear attention actually started to come back. So in earlier this year, there was a model called BASED the, from Simran Arora and, and some other folks, that combined a more principled version of linear attention that basically the, the, the, the two second summary is that it used a Taylor approximation of the softmax attention, combined that with a simple sliding window attention and was starting to able, starting to be able to expand the Pareto frontier of how much data can you recall from your sequence, versus how small is your recurrent state size.
[00:14:58] Dan Fu: So those orange dots [00:15:00] are, at the top there, are just showing smaller sequences that can recall more memory.
[00:15:07] Just Read Twice
[00:15:07] Dan Fu: And the last major idea I think that has been influential in this line of work and is very relatively late breaking just a few months ago, is just the basic idea that when you have these models that are fundamentally more efficient in the sequence length, you maybe don't want to prompt them or use them in exactly the same way.
[00:15:26] Dan Fu: So this was a really cool paper called Just Read Twice, also from Simran. That basically said, hey, all these efficient models can process tokens so much more efficiently than transformers that they can sometimes have unfair advantages compared to a simple transformer token. So, or sorry, a simple transformer model.
[00:15:44] Dan Fu: So take, for example the standard, the standard use case of you have some long document, you're going to pass it in as input, and then you're going to ask some question about it. One problem you might imagine for a recurrent model where you have a fixed state size is, let's say that [00:16:00] you're. Article is very long, and you're trying to ask about some really niche thing.
[00:16:04] Dan Fu: You can imagine it might be hard for the model to know ahead of time what information to put into the hidden state. But these, these, these models are so much more efficient that you can do something really stupid, like, you can just put the document write down the document, write down the question, write down the document again, and then write down the question again, and then this time, the second time that you go over that document, you know exactly what to look for.
[00:16:25] Dan Fu: And the cool thing about this is, so this is, And this this results in better quality, especially on these recall intensive tasks. But the other interesting thing is it really takes advantage of the more efficient architectures that, that we're having here. So one of the other, I think, influential ideas in this line of work is if you change the fundamental compute capabilities of your model and the way that it scales, you can actually start to query it at test time differently.
[00:16:51] Idea 4: Test Time Compute
[00:16:51] Dan Fu: And this actually, of course, goes back to those slides on test time compute. So while everybody's looking at, say, test time compute for big transformer models, [00:17:00] I think potentially a really interesting research question is, how can you take those and how does it change with this new next generation of models?
[00:17:09] Dan Fu: So the, I'll just briefly summarize what some of those key ideas were and then talk and then show you briefly kind of what the state of the art is today. So, so the four key ideas are instead of just doing a simple linear attention approximation, instead take ideas that we know from other fields like signal processing, do a more principled approach to your modeling of the sequence.
[00:17:32] Idea 2: Hardware & Kernel Support
[00:17:32] Dan Fu: Another key idea throughout all these lines of work is you really want. Hardware and kernel support from day one. So, so even if your model is theoretically more efficient if somebody goes and runs it and it's two times slower one of the things that, that we've learned is that if, if you're in that situation, it's, it's just gonna be dead on arrival.
[00:17:49] Dan Fu: So you want to be designing your architectures one of the key, key machine learning ideas that has been important for the quality is just making sure that you encode different ways that you can [00:18:00] select from your hidden state and, and really focus on that as a key decider of quality. And finally, I think one of the, the, the emerging new, new things for, for this line of work and something that's quite interesting is, What are the right test time paradigms for these models?
[00:18:15] Dan Fu: How do they change relative to relative to what you might do for a standard transformer? I'll briefly end this section. So I've labeled this slide where we are yesterday because Eugene is going to talk about some new models that he released literally this morning. But as of yesterday, some of the really cool results out of the, these efficient alternative models were so AI2 trained this hybrid MOE called Jamba.
[00:18:40] Dan Fu: That, that, that seems, that is currently the state of the art for these non transformer architectures. There's this NVIDIA and MIT put out this new diffusion model called SANA recently that one of their key key observations is that you can take a standard diffusion transformer diffusion model, replace the layers with linear [00:19:00] attention, and then that lets you scale to much larger much larger images, much, much Much larger sequences more efficiently.
[00:19:07] Dan Fu: And and one thing that I don't think anybody would have called when a few years ago is that one of those gated SSM, gated states based models ended up on the cover of Science because a great group of folks went and trained some DNA models. So that's Michael Polley, Eric Yuen from from Stanford and the Arc Institute.
[00:19:26] Dan Fu: So it's, we're really at an exciting time in 2024 where these non transformer, post transformer architectures are showing promise across a wide range. Across a wide range of, of modalities, of applications, and, and of tasks. And with that, I'll pass it on to Eugene, who can tell you a little bit about the latest and greatest with RWKV.
[00:19:49] RWKV vs SSMs
[00:19:49] Eugene Cheah: So, that's useful? Yeah. You're talking to here. Oh, I'm talking to here. Okay. So, yeah, two streams. Yeah. So, I think one common questions that we tend to get asked, right, is what's the difference between [00:20:00] RWKV and state space? So I think one of the key things to really understand, right the difference between the two groups, right, is that we are actually more like an open source, random internet meets academia kind of situation.
[00:20:11] Eugene Cheah: Like, most of us never wrote any paper, but we, we basically look at RNNs and linear intention when intention is all you need came out, and then we decided to like, hey there is a quadratic scaling problem. Why don't we try fixing that instead? So, so, so we end up developing our own branch, but we end up sharing ideas back and forth.
[00:20:30] Eugene Cheah: So, and, and we do all this actively in Discord, GitHub, etc. This was so bad for a few years, right, that basically, the average group's H index was so close to zero, right, Illuter. ai actually came in and helped us write our first paper. Great, now our H index is now three, apparently. So, so, so, but, but the thing is, like, a lot of these experiments led to results, and, and, essentially, essentially, we we took the same ideas from linear attention, [00:21:00] and we built on it.
[00:21:01] Eugene Cheah: So, to take a step back into, like, how does RWKB handle its own attention mechanic and achieve the same goals of, like, O and compute, respectively, and in focus of our overall goal to make AI accessible to everyone, regardless of language, nation, or compute, that's our goal. We actually train our models primarily on over a hundred languages, which is another topic altogether.
[00:21:23] Eugene Cheah: And our goal is to train to even 200 languages to cover all languages in the world. But at the same time, we work on this architecture, To lower the compute cost so that people can run it on Raspberry Pis and on anything. So, how did RWKB break the dependency of LSTM token flow? Because I think to understand architecture, right, it's probably easier to understand it from the RNN lens.
[00:21:46] Eugene Cheah: Because that's where we built on. We all, we all state space kind of like try to, try to start anew and took lessons from that and say, So there's a little bit of divergence there. And AKA, this our version of linear attention. So to take step back [00:22:00] all foundation models, be it transformers or non transformers at a very high level, right?
[00:22:05] Eugene Cheah: Pumps in the token. I mean, text that things into embeddings and go through a lot of layers. Generate a lot of states where the QKV cache or be iron in states or RW KB states. And outputs and embedding, they are not the same thing. And we just take more layers and more embeddings. And somehow that magically works.
[00:22:23] Eugene Cheah: So, if you, if you remember your ancient RNN lessons which we, which we, which we we call best learning these days the general idea is that you have the embedding information flowing all the way up, and when, and you take that information and you flow it back down, and then you process it as part of your LSTM layers.
[00:22:41] Eugene Cheah: So, this is how it generally works. Kapati is quoted saying that RNNs are actually unreasonably effective. The problem is this is not scalable. To start doing work on the second token, you need to wait for the first token. And then you need to, and likewise for the third token and fourth token, yada yada.
[00:22:55] Eugene Cheah: That is CPU land, not GPU land. So, so, so, you [00:23:00] can have a H100 and you can't even use 1 percent of it. So, so that's kind of why RNNs didn't really take off in the direction that we wanted, like, billions of parameters when it comes to training. So, what did RDAP KV version 0 do? Boom. We just did the dumbest, lamest thing.
[00:23:13] Eugene Cheah: Sorry, this is the bottleneck for RNN. We did the dumb thing of removing that line. And it kind of worked. It trained. It sucked, but it kind of worked. Then we were like, hey, then no one cared because the loss was crap, but how do we improve that? And that's essentially where we move forward, because if you see this kind of flow, right, you can actually get your GPU saturated quickly, where it essentially cascades respectively.
[00:23:41] Eugene Cheah: So I'm just waiting for this to loop again. So it's like, once you get your first layer, your token to be computed finish. You start to cascade your compute all the way until you are, Hey, I'm using 100 percent of the GPU. So we, we worked on it, and we started going along the principle of that as long as we keep this general architecture [00:24:00] where, where we can cascade and, and be highly efficient with our architecture, nothing is sacred in our architecture.
[00:24:06] Eugene Cheah: And we have done some crazy ideas. In fact, you ask us, if you ask me to explain some things in the paper, right, officially in the paper, I'll say we had this idea and we wrote it this way. The reality is someone came with a code, we tested it, it worked, and then we rationalized later. So, so the general
[00:24:24] RWKV Arch
[00:24:24] Eugene Cheah: The idea behind rwkbr is that we generally have two major blocks that we do.
[00:24:30] Eugene Cheah: We call time mix and channel mix. And time mix generally handles handles long term memory states, where essentially, where essentially where we apply the matrix multiplication and Cilu activation functions into processing an input embedding and an output embedding. I'm oversimplifying it because this, This calculation changed every version and we have, like, version 7 right now.
[00:24:50] Eugene Cheah: ChannelMix is similar to Base in the sense that it does shorter term attention, where it just looks at the sister token, or the token before it, because [00:25:00] there's a shift in the token shift matrix. I don't really want to go too much into the papers itself, because, like, we do have three papers on this.
[00:25:09] Eugene Cheah: Basically, RWKB, RNN for the transformer, ERA, Ego and Pinch, RWKB, Matrix Value State. This is the updated version 5, version 6. And Goldfinch is our, is, is, is, is our hybrid model respectively. We are writing the paper already for V seven and which is, which is for R wk V seven. Called, named Goose, or architectures are named by Bird.
[00:25:30] Eugene Cheah: And, I'm going to cover as well, qrwkb, and mama100k, and rwkb, and Where did that lead to? Great! Because we are all GPU poor and to be clear, like, most of this research is done, like, only on a handful H100s, which I had one Google researcher told me that was, like, his experiment budget for a single researcher.
[00:25:48] Eugene Cheah: So, our entire organization has less compute than a single researcher in Google. So We, we, one of the things that we explored into was to how do we convert transformer models instead? Because [00:26:00] someone already paid that billion dollars, a million dollars onto training, so why don't we take advantage of those weights?
[00:26:05] Eugene Cheah: And, and to, I believe, together AI worked on the lockets for, for the Lambda side of things, and, and we took some ideas from there as well, and we essentially did that for RWKB.
[00:26:15] QWRKWv6 launch
[00:26:15] Eugene Cheah: And that led to, Q RWKB6, which we just dropped today, a 32 bit instruct preview model, where we took the Quen 32 bit instruct model, freeze the feedforward layer, remove the QKB attention layer, and replace it with RWKB linear layers.
[00:26:32] Eugene Cheah: So to be clear, this means we do not have the rwkv channel mix layer, we only have the time mix layer. But but once we do that, we train the rwkv layer. Important is that the feedforward layer needs to be frozen, so the new attention can be learned. And then we unfreeze the feedforward layer, and train all the layers together with a custom learning rate schedule, so that they can learn how to work together.
[00:26:54] Eugene Cheah: The end result, surprisingly, And, to be honest, to the frustration of the R. W. [00:27:00] KV MOE team, which ended up releasing the model on the same day, was that, with just a few hours of training on two nodes, we managed to get it to be on par, kind of, with the original QUAN32B model. So, in fact, when the first run, right, that completely confused us, it was like, and I was telling Daniel Goldstein, Smirky, who kind of leads most of our research coordination, When you pitched me this idea, you told me at best you'll get the same level of performance.
[00:27:26] Eugene Cheah: You didn't tell me the challenge and score and Winograd score will shoot up. I don't know what's happening there. But it did. MMLU score dropping, that was expected. Because if you think about it, when we were training all the layers, right, we were essentially Like, Frankenstein this thing, and we did brain damage to the feedforward network layer 2 with the new RWKB layers.
[00:27:47] Eugene Cheah: But, 76%, hey, somehow it's retained, and we can probably further train this. We didn't even spend more than 3 days training this, so there's a lot more that can be done, hence the preview. This brings up [00:28:00] a big question, because We are already now in the process of converting to 7TB. We are now, this is actually extremely compute efficient to test our attention mechanic.
[00:28:10] Eugene Cheah: It's like, it becomes a shortcut. We can, we are already planning to do our version 7 and our hybrid architecture for it. Because we don't need to train from scratch. And we get a really good model out of it. And the other thing that is uncomfortable to say is that because we are doing right now on the 70b is that if this scales correctly to 128k context length, I'm not even talking about a million 128, majority of enterprise workload today is just on 70b at under 32k context length.
[00:28:41] Eugene Cheah: That means if this works and the benchmark matches it, It means we can replace the vast majority of current AI workload, unless you want super long context. And then sorry, can someone give us more GPUs? Because we do need the VRAM for super long context, sadly. So yeah, that's what we are working on, and essentially, [00:29:00] we are excited about this to just push it further.
[00:29:02] Eugene Cheah: And this conversion process, to be clear, I don't think it's going to be exclusive to RWKB. It probably will work for Mamba as well, I don't see why not. And we will probably see more ideas, or more experiments, or more hybrids, or Yeah, like, one of the weirdest things that I wanted to say outright, and I confirmed this with the Black Mamba team and the Jamba team, which because we did the GoFinch hybrid model, is that none of us understand why a hard hybrid with a state based model to be R.
[00:29:28] Eugene Cheah: QA state space and transformer performs better when, than the baseline of both. It's like, it's like when you train one, you expect, and then you replace, you expect the same results. That's our pitch. That's our claim. But somehow when we jam both together, it outperforms both. And that's like one area of emulation that, like, we only have four experiments, plus four teams, that a lot more needs to be done.
[00:29:51] Eugene Cheah: But, but these are things that excite me, essentially, because that is what it's potentially we can move ahead for. Which brings us to what comes next.
[00:30:00] What's next
[00:30:00] [00:30:00]
[00:30:00] Dan Fu: So, this part is kind of just some, where we'll talk a little bit about stuff that, that we're excited about. Maybe have some wild speculation on, on what, what's, what's coming next.
[00:30:12] Dan Fu: And, of course this is also the part that will be more open to questions. So, a couple things that, that I'm excited about is continued hardware model co design for, for these models. So one of the things that we've put out recently is this library called ThunderKittens. It's a CUDA library.
[00:30:29] Dan Fu: And one of the things that, that we found frustrating is every time that we built one of these new architectures, and I'm sure you had the exact same experience, we'd have to go and spend two months in CUDA land, like writing these, these new efficient things. And. If we decided to change one thing in PyTorch, like one line of PyTorch code is like a week of CUDA code at least.
[00:30:47] Dan Fu: So one of our goals with, with a library like Thunderkitten, so we, we just broke down what are the key principles, what are the key hardware things what are the key, Compute pieces that you get from the hardware. So for example on [00:31:00] H100 everything is really revolves around a warp group matrix multiply operation.
[00:31:06] Dan Fu: So you really want your operation to be able to split into relatively small matrix, matrix multiply operations. So like multiplying two 64 by 64 matrices, for example. And so if you know that ahead of time when you're designing your model, that probably gives you you know, some information about how you set the state sizes, how you set the update, how you set the update function.
[00:31:27] Dan Fu: So with Thunderkittens we basically built a whole library just around this basic idea that all your basic compute primitives should not be a float, but it should be a matrix, and everything should just be matrix compute. And we've been using that to, to try to both re implement some existing architectures, and also start to design code.
[00:31:44] Dan Fu: Some new ones that are really designed with this core with a tensor core primitive in mind. Another thing that that we're, that at least I'm excited about is we, over the last four or five years, we've really been looking at language models as the next thing. But if you've been paying [00:32:00] attention to Twitter there's been a bunch of new next generation models that are coming out.
[00:32:04] Dan Fu: So there, there are. So, video generation models that can run real time, that are supported by your mouse and your keyboard, that I'm told if you play with them that, you know, that they only have a few seconds of memory. Can we take that model, can we give it a very long context length so that you could actually maybe generate an entire game state at a time?
[00:32:25] Dan Fu: What does that look like for the model? You're certainly not going to do a giant quadratic attention computation to try to run that. Maybe, maybe use some of these new models, or some of these new video generation models that came out. So Sora came out I don't know, two days ago now. But with super long queue times and super long generation times.
[00:32:43] Dan Fu: So that's probably a quadratic attention operation at the, at the bottom of it. What if we could remove that and get the same quality, but a lot faster generation time? Or some of the demos that we saw from Paige earlier today. You know, if I have a super long conversation with my [00:33:00] Gemini bot, what if I wanted to remember everything that it's seen in the last week?
[00:33:06] Dan Fu: I mean, maybe you don't for personal reasons, but what if I did, you know? What does that mean for the architecture? And I think, you know, that's certainly something I'm pretty excited about. I'm sure you're excited about it too. So, I think we were supposed to have some hot takes, but I honestly don't remember what our hot takes were.
[00:33:21] Hot Takes - does anyone really need long context?
[00:33:21] Eugene Cheah: Yeah, including the next slide. Hot takes, yes, these are our
[00:33:25] Dan Fu: hot takes.
[00:33:25] Eugene Cheah: I think the big one on Twitter that we saw, that we shared, was the question is like, is RAG relevant? In the case of, like, the future of, like, state based models?
[00:33:38] Dan Fu: Let's see, I haven't played too much with RAG. But when I have. I'll say I found it was a little bit challenging to do research on it because we had this experience over and over again, where you could have any, an embedding model of any quality, so you could have a really, really bad embedding model, or you could have a really, really [00:34:00] good one, By any measure of good.
[00:34:03] Dan Fu: And for the final RAG application, it kind of didn't matter. That's what I'll say about RAG while I'm being recorded. I know it doesn't actually answer the question, but
[00:34:13] Eugene Cheah: Yeah, so I think a lot of folks are like, extremely excited of the idea of RWKB or State Space potentially having infinite context.
[00:34:21] Eugene Cheah: But I think the reality is that when we say infinite context, we just mean a different kind of infinite context, or you, or as it's previously covered, you need to test the model differently. So, think of it more along the lines of the human. Like, I don't remember what I ate for breakfast yesterday.
[00:34:37] Eugene Cheah: Yeah, that's the statement that I'll say. And And we humans are not quadratic transformers. If we did, if let's say we increased our brain size for every second we live, we would have exploded by the time we are 5 years old or something like that. And, and I think, I think basically fundamentally for us, right, be it whether we, regardless of whether RWKB, statespace, XLSTM, [00:35:00] etc, our general idea is that instead of that expanding state, that increase in computational cost, what if we have a fixed state size?
[00:35:08] Eugene Cheah: And Information theory detects that that fixed state size will have a limit. Just how big of a limit is a question, like, we, like, RWKB is running at 40 megabytes for, for its state. Its future version might run into 400 megabytes. That is like millions of tokens in, if you're talking about mathematically, the maximum possibility.
[00:35:29] Eugene Cheah: It's just that I guess we were all more inefficient about it, so maybe we hit 100, 000. And that's kind of like the work we are doing, trying to like push it and maximize it. And that's where the models will start differing, because it will choose to forget things, it will choose to remember things. And that's why I think that there might be some element of right, but it may not be the same right.
[00:35:49] Eugene Cheah: It may be the model learn things, and it's like, hmm, I can't remember that, that article. Let me do a database search, to search. Just like us humans, when we can't remember the article in the company. We do a search on Notion. [00:36:00]
[00:36:00] Dan Fu: I think something that would be really interesting is if you could have facts that are, so right now, the one intuition about language models is that all those parameters are around just to store random facts about the world.
[00:36:14] Dan Fu: And this intuition comes from the observation that if you take a really small language model, it can do things like talk to you, or kind of has like the The style of conversation, it can learn that, but where it will usually fall over compared to a much larger one is it'll just be a lot less factual about things that it knows or that it can do.
[00:36:32] Dan Fu: But that points to all those weights that we're spending, all that SGD that we're spending to train these models are just being used to store facts. And we have things like databases that are pretty good at storing facts. So I think one thing that would be really interesting is if we could actually have some sort of outside data store that a language model can can look at that that maybe is you know, has has some sort of gradient descent in it, but but would be quite interesting.
[00:36:58] Dan Fu: And then maybe you could edit it, delete [00:37:00] facts, you know, change who's president so that it doesn't, it doesn't get lost.
[00:37:04] Vibhu: Can we open up Q& A and hot takes for the audience? I have a hot take Q& A. Do these scale? When, when 405B state space model, RAG exists, no one does long context, who's throwing in 2 million token questions, hot takes?
[00:37:24] Dan Fu: The, the who's throwing in 2 million token question, I think, is, is a really good question. So I actually, I was going to offer that as a hot take. I mean, my hot take was going to be that long context doesn't matter. I know I just gave a whole talk about it, but you know, what, what's the point of doing research if you can't, you know, play both sides.
[00:37:40] Dan Fu: But I think one of the, so I think for both of us, the reason that we first got into this was just from the first principled questions of there's this quadratic thing. Clearly intelligence doesn't need to be quadratic. What is going on? Can we understand it better? You know, since then it's kind of turned into a race, which has [00:38:00] been exciting to watch, like, how much context you can take in.
[00:38:03] Dan Fu: But I think it's right. Nobody is actually putting in a two million context prompt into these models. And, and, you know, if they are, maybe we can go, go You know, design a better model to do that particular thing. Yeah, what do you think about that? So you've also been working on this. Do you think long context matters?
[00:38:19] Eugene Cheah: So I'm going to burn a bit. How many of you remember the news of Google Gemini supporting 3 million contacts, right? Raise your hand.
[00:38:28] Vibhu: Yeah, 2 million.
[00:38:29] Eugene Cheah: Oh, it's 2 million.
[00:38:31] Eugene Cheah: Yeah, how many of you actually tried that? See?
[00:38:34] Vibhu: I use it a lot. You? You work for MindsTV. I use it a lot.
[00:38:41] Eugene Cheah: So, for some people that has used, and I think, I think that's the, that's might be, like, this is where my opinion starts to differ, because I think the big labs may have a bigger role in this, because Like, even for RWKB, even when we train non contacts, the reason why I say VRAM is a problem is that because when we did the, we need to backprop [00:39:00] against the states, we actually need to maintain the state in between the tokens by the token length.
[00:39:05] Eugene Cheah: So that means we need to actually roll out the whole 1 million contacts if we are actually training 1 million. Which is the same for transformers, actually, but it just means we don't magically reuse the VRAM consumption in the training time space. So that is one of the VRAM bottlenecks, and I'm neither OpenAI nor Google, so donate GPUs if you have too much of them.
[00:39:27] Eugene Cheah: But then, putting it back to another paradigm, right, is that I think O1 style reasoning might be actually pushing that direction downwards. In my opinion, this is my partial hot take is that if, let's say you have a super big model, And let's say you have a 70B model that may take double the tokens, but gets the same result.
[00:39:51] Eugene Cheah: Strictly speaking, a 70B, and this is even for transformer or non transformer, right? We we'll take less less resources than that 400 B [00:40:00] model, even if it did double the amount thinking. And if that's the case, and we are still all trying to figure this out, maybe the direction for us is really getting the sub 200 B to be as fast as efficient as possible.
[00:40:11] Eugene Cheah: We a very efficient architecture that some folks happen to be working on to, to just reason it out over larger and larger context thing.
[00:40:20] Question: Yeah. One thing I'm super interested in is. Models that can watch forever? Obviously you cannot train something on infinite context length. How are y'all thinking about that, where you run on a much longer context length than is possible to train on?
[00:40:38] Dan Fu: Yeah, it's a, it's a great question. So I think when I think you guys probably had tweets along these lines, too. When we first started doing these things, because these are all recurrent models in theory you could just run it forever. You could just run it forever. And at the very least it won't, it won't like error out on your crash.
[00:40:57] Dan Fu: There's another question of whether it can actually [00:41:00] use what it's seen in that infinite context. And I think there, so one place where probably the research and architectures ran faster Then another research is actually the benchmarks for long context. So you turn it on forever. You want to do everything or watch everything.
[00:41:16] Dan Fu: What is it that you actually wanted to do? Can we actually build some benchmarks for that? Then measure what's happening. And then ask the question, can the models do it? Is there something else that they need? Yeah, I think that if I were to turn back the clock to 2022, that's probably one of the things I would have done differently, which would have been actually get some long context benchmarks out at the same time as we started pushing context length on all these models.
[00:41:41] Eugene Cheah: I will also say the use case. So like, I think we both agree that there's no Infinite memory and the model needs to be able to learn and decide. I think what we have observed for, I think this also fits the state space model, is that one of the key advantages of this alternate attention mechanic that is not based on token position is that the model don't suddenly become crazy when you go past the [00:42:00] 8k training context tank, or a million context tank.
[00:42:03] Eugene Cheah: It's actually still stable. It's still able to run, it's still able to rationalize. It just starts forgetting things. But some of these things are still there in latent memory. Some of these things are still somewhat there. That's the whole point of why reading twice works. Things like that. And one of the biggest pushes in this direction is that I think both Statespace and RWKB have Separate papers by other researchers where they use this architecture for time series data.
[00:42:26] Eugene Cheah: Weather modeling. So, you are not asking what was the weather five days ago. You're asking what's the weather tomorrow based on the infinite length that we, as long as this Earth and the computer will keep running. So, so, and they found that it is like, better than existing, like, transformer or existing architecture in modeling this weather data.
[00:42:47] Eugene Cheah: Control for the param size and stuff. I'm quite sure there are people with larger models. So, so there are things that, that in this case, right, there is future applications if your question is just what's next and not what's 10 years ago.
[00:42:59] Dan Fu: Thanks so [00:43:00] much for having us.

Share this post