


Happy holidays! We’ll be sharing snippets from Latent Space LIVE! through the break bringing you the best of 2024! We want to express our deepest appreciation to event sponsors AWS, Daylight Computer, Thoth.ai, StrongCompute, Notable Capital, and most of all all our LS supporters who helped fund the gorgeous venue and A/V production!
For NeurIPS last year we did our standard conference podcast coverage interviewing selected papers (that we have now also done for ICLR and ICML), however we felt that we could be doing more to help AI Engineers 1) get more industry-relevant content, and 2) recap 2024 year in review from experts. As a result, we organized the first Latent Space LIVE!, our first in person miniconference, at NeurIPS 2024 in Vancouver.
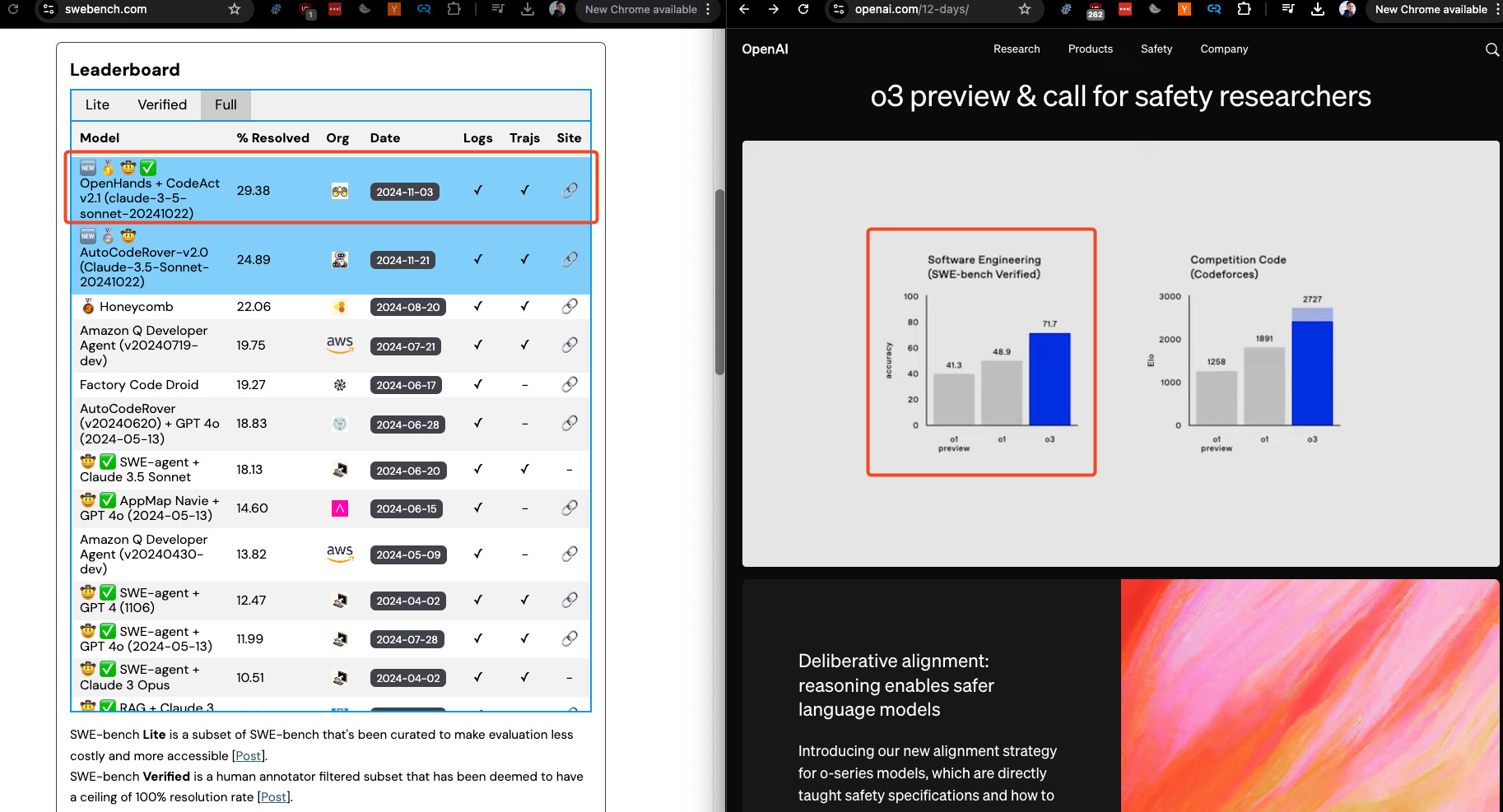
Our next keynote covers The State of LLM Agents, with the triumphant return of Professor Graham Neubig’s return to the pod (his ICLR episode here!). OpenDevin is now a startup known as AllHands! The renamed OpenHands has done extremely well this year, as they end the year sitting comfortably at number 1 on the hardest SWE-Bench Full leaderboard at 29%, though on the smaller SWE-Bench Verified, they are at 53%, behind Amazon Q, devlo, and OpenAI's self reported o3 results at 71.7%.
Many are saying that 2025 is going to be the year of agents, with OpenAI, DeepMind and Anthropic setting their sights on consumer and coding agents, vision based computer-using agents and multi agent systems. There has been so much progress on the practical reliability and applications of agents in all domains, from the huge launch of Cognition AI's Devin this year, to the sleeper hit of Cursor Composer and Codeium's Windsurf Cascade in the IDE arena, to the explosive revenue growth of Stackblitz's Bolt, Lovable, and Vercel's v0, and the unicorn rounds and high profile movements of customer support agents like Sierra (now worth $4 billion) and search agents like Perplexity (now worth $9 billion). We wanted to take a little step back to understand the most notable papers of the year in Agents, and Graham indulged with his list of 8 perennial problems in building agents in 2024.
Must-Read Papers for the 8 Problems of Agents
The agent-computer interface: CodeAct: Executable Code Actions Elicit Better LLM Agents. Minimial viable tools: Execution Sandbox, File Editor, Web Browsing
The human-agent interface: Chat UI, GitHub Plugin, Remote runtime, …?
Choosing an LLM: See Evaluation of LLMs as Coding Agents on SWE-Bench at 30x - must understand instructions, tools, code, environment, error recovery
Planning: Single Agent Systems vs Multi Agent (CoAct: A Global-Local Hierarchy for Autonomous Agent Collaboration) - Explicit vs Implicit, Curated vs Generated
Reusable common workflows: SteP: Stacked LLM Policies for Web Actions and Agent Workflow Memory - Manual prompting vs Learning from Experience
Exploration: Agentless: Demystifying LLM-based Software Engineering Agents and BAGEL: Bootstrapping Agents by Guiding Exploration with Language
Search: Tree Search for Language Model Agents - explore paths and rewind
Evaluation: Fast Sanity Checks (miniWoB and Aider) and Highly Realistic (WebArena, SWE-Bench) and SWE-Gym: An Open Environment for Training Software Engineering Agents & Verifiers
Full Talk on YouTube
Timestamps
00:00 Welcome to Latent Space Live at NeurIPS 2024
00:29 State of LLM Agents in 2024
02:20 Professor Graham Newbig's Insights on Agents
03:57 Live Demo: Coding Agents in Action
08:20 Designing Effective Agents
14:13 Choosing the Right Language Model for Agents
16:24 Planning and Workflow for Agents
22:21 Evaluation and Future Predictions for Agents
25:31 Future of Agent Development
25:56 Human-Agent Interaction Challenges
26:48 Expanding Agent Use Beyond Programming
27:25 Redesigning Systems for Agent Efficiency
28:03 Accelerating Progress with Agent Technology
28:28 Call to Action for Open Source Contributions
30:36 Q&A: Agent Performance and Benchmarks
33:23 Q&A: Web Agents and Interaction Methods
37:16 Q&A: Agent Architectures and Improvements
43:09 Q&A: Self-Improving Agents and Authentication
47:31 Live Demonstration and Closing Remarks
Transcript
[00:00:29] State of LLM Agents in 2024
[00:00:29] Speaker 9: Our next keynote covers the state of LLM agents. With the triumphant return of Professor Graham Newbig of CMU and OpenDevon, now a startup known as AllHands. The renamed OpenHands has done extremely well this year, as they end the year sitting comfortably at number one on the hardest SWE Benchful leaderboard at 29%.
[00:00:53] Speaker 9: Though, on the smaller SWE bench verified, they are at 53 percent behind Amazon Q [00:01:00] Devlo and OpenAI's self reported O3 results at 71. 7%. Many are saying that 2025 is going to be the year of agents, with OpenAI, DeepMind, and Anthropic setting their sights on consumer and coding agents. Vision based computer using agents and multi agent systems.
[00:01:22] Speaker 9: There has been so much progress on the practical reliability and applications of agents in all domains, from the huge launch of Cognition AI's Devon this year, to the sleeper hit of Cursor Composer and recent guest Codium's Windsurf Cascade in the IDE arena. To the explosive revenue growth of recent guests StackBlitz's Bolt, Lovable, and Vercel's vZero.
[00:01:44] Speaker 9: And the unicorn rounds and high profile movements of customer support agents like Sierra, now worth 4 billion, and search agents like Perplexity, now worth 9 billion. We wanted to take a little step back to understand the most notable papers of the year in [00:02:00] agents, and Graham indulged with his list of eight perennial problems in building agents.
[00:02:06] Speaker 9: As always, don't forget to check our show notes for all the selected best papers of 2024, and for the YouTube link to their talk. Graham's slides were especially popular online, and we are honoured to have him. Watch out and take care!
[00:02:20] Professor Graham Newbig's Insights on Agents
[00:02:20] Speaker: Okay hi everyone. So I was given the task of talking about agents in 2024, and this is An impossible task because there are so many agents, so many agents in 2024. So this is going to be strongly covered by like my personal experience and what I think is interesting and important, but I think it's an important topic.
[00:02:41] Speaker: So let's go ahead. So the first thing I'd like to think about is let's say I gave you you know, a highly competent human, some tools. Let's say I gave you a web browser and a terminal or a file system. And the ability to [00:03:00] edit text or code. What could you do with that? Everything. Yeah.
[00:03:07] Speaker: Probably a lot of things. This is like 99 percent of my, you know, daily daily life, I guess. When I'm, when I'm working. So, I think this is a pretty powerful tool set, and I am trying to do, and what I think some other people are trying to do, is come up with agents that are able to, you know, manipulate these things.
[00:03:26] Speaker: Web browsing, coding, running code in successful ways. So there was a little bit about my profile. I'm a professor at CMU, chief scientist at All Hands AI, building open source coding agents. I'm maintainer of OpenHands, which is an open source coding agent framework. And I'm also a software developer and I, I like doing lots of coding and, and, you know, shipping new features and stuff like this.
[00:03:51] Speaker: So building agents that help me to do this, you know, is kind of an interesting thing, very close to me.
[00:03:57] Live Demo: Coding Agents in Action
[00:03:57] Speaker: So the first thing I'd like to do is I'd like to try [00:04:00] some things that I haven't actually tried before. If anybody has, you know, tried to give a live demo, you know, this is, you know very, very scary whenever you do it and it might not work.
[00:04:09] Speaker: So it might not work this time either. But I want to show you like three things that I typically do with coding agents in my everyday work. I use coding agents maybe five to 10 times a day to help me solve my own problems. And so this is a first one. This is a data science task. Which says I want to create scatter plots that show the increase of the SWE bench score over time.
[00:04:34] Speaker: And so I, I wrote a kind of concrete prompt about this. Agents work better with like somewhat concrete prompts. And I'm gonna throw this into open hands and let it work. And I'll, I'll go back to that in a second. Another thing that I do is I create new software. And I, I've been using a [00:05:00] service a particular service.
[00:05:01] Speaker: I won't name it for sending emails and I'm not very happy with it. So I want to switch over to this new service called resend. com, which makes it easier to send emails. And so I'm going to ask it to read the docs for the resend. com API and come up with a script that allows me to send emails. The input to the script should be a CSV file and the subject and body should be provided in Jinja2 templates.
[00:05:24] Speaker: So I'll start another agent and and try to get it to do that for me.
[00:05:35] Speaker: And let's go with the last one. The last one I do is. This is improving existing software and in order, you know, once you write software, you usually don't throw it away. You go in and, like, actually improve it iteratively. This software that I have is something I created without writing any code.
[00:05:52] Speaker: It's basically software to monitor how much our our agents are contributing to the OpenHance repository. [00:06:00] And on the, let me make that a little bit bigger, on the left side, I have the number of issues where it like sent a pull request. I have the number of issues where it like sent a pull request, whether it was merged in purple, closed in red, or is still open in green. And so these are like, you know, it's helping us monitor, but one thing it doesn't tell me is the total number. And I kind of want that feature added to this software.
[00:06:33] Speaker: So I'm going to try to add that too. So. I'll take this, I'll take this prompt,
[00:06:46] Speaker: and here I want to open up specifically that GitHub repo. So I'll open up that repo and paste in the prompt asking it. I asked it to make a pie chart for each of these and give me the total over the entire time period that I'm [00:07:00] monitoring. So we'll do that. And so now I have let's see, I have some agents.
[00:07:05] Speaker: Oh, this one already finished. Let's see. So this one already finished. You can see it finished analyzing the Swebench repository. It wrote a demonstration of, yeah, I'm trying to do that now, actually.
[00:07:30] Speaker: It wrote a demonstration of how much each of the systems have improved over time. And I asked it to label the top three for each of the data sets. And so it labeled OpenHands as being the best one for SWE Bench Normal. For SWE Bench Verified, it has like the Amazon QAgent and OpenHands. For the SWE Bench Lite, it has three here over three over here.
[00:07:53] Speaker: So you can see like. That's pretty useful, right? If you're a researcher, you do data analysis all the time. I did it while I was talking to all [00:08:00] of you and making a presentation. So that's, that's pretty nice. I, I doubt the other two are finished yet. That would be impressive if the, yeah. So I think they're still working.
[00:08:09] Speaker: So maybe we'll get back to them at the end of the presentation. But so these are the kinds of the, these are the kinds of things that I do every day with coding agents now. And it's or software development agents. It's pretty impressive.
[00:08:20] Designing Effective Agents
[00:08:20] Speaker: The next thing I'd like to talk about a little bit is things I worry about when designing agents.
[00:08:24] Speaker: So we're designing agents to, you know, do a very difficult task of like navigating websites writing code, other things like this. And within 2024, there's been like a huge improvement in the methodology that we use to do this. But there's a bunch of things we think about. There's a bunch of interesting papers, and I'd like to introduce a few of them.
[00:08:46] Speaker: So the first thing I worry about is the agent computer interface. Like, how do we get an agent to interact with computers? And, How do we provide agents with the tools to do the job? And [00:09:00] within OpenHands we are doing the thing on the right, but there's also a lot of agents that do the thing on the left.
[00:09:05] Speaker: So the thing on the left is you give like agents kind of granular tools. You give them tools like or let's say your instruction is I want to determine the most cost effective country to purchase the smartphone model, Kodak one the countries to consider are the USA, Japan, Germany, and India. And you have a bunch of available APIs.
[00:09:26] Speaker: And. So what you do for some agents is you provide them all of these tools APIs as tools that they can call. And so in this particular case in order to solve this problem, you'd have to make about like 30 tool calls, right? You'd have to call lookup rates for Germany, you'd have to look it up for the US, Japan, and India.
[00:09:44] Speaker: That's four tool goals. And then you go through and do all of these things separately. And the method that we adopt in OpenHands instead is we provide these tools, but we provide them by just giving a coding agent, the ability to call [00:10:00] arbitrary Python code. And. In the arbitrary Python code, it can call these tools.
[00:10:05] Speaker: We expose these tools as APIs that the model can call. And what that allows us to do is instead of writing 20 tool calls, making 20 LLM calls, you write a program that runs all of these all at once, and it gets the result. And of course it can execute that program. It can, you know, make a mistake. It can get errors back and fix things.
[00:10:23] Speaker: But that makes our job a lot easier. And this has been really like instrumental to our success, I think. Another part of this is what tools does the agent need? And I, I think this depends on your use case, we're kind of extreme and we're only giving the agent five tools or maybe six tools.
[00:10:40] Speaker: And what, what are they? The first one is program execution. So it can execute bash programs, and it can execute Jupyter notebooks. It can execute cells in Jupyter notebooks. So that, those are two tools. Another one is a file editing tool. And the file editing tool allows you to browse parts of files.[00:11:00]
[00:11:00] Speaker: And kind of read them, overwrite them, other stuff like this. And then we have another global search and replace tool. So it's actually two tools for file editing. And then a final one is web browsing, web browsing. I'm kind of cheating when I call it only one tool. You actually have like scroll and text input and click and other stuff like that.
[00:11:18] Speaker: But these are basically the only things we allow the agent to do. What, then the question is, like, what if we wanted to allow it to do something else? And the answer is, well, you know, human programmers already have a bunch of things that they use. They have the requests PyPy library, they have the PDF to text PyPy library, they have, like, all these other libraries in the Python ecosystem that they could use.
[00:11:41] Speaker: And so if we provide a coding agent with all these libraries, it can do things like data visualization and other stuff that I just showed you. So it can also get clone repositories and, and other things like this. The agents are super good at using the GitHub API also. So they can do, you know, things on GitHub, like finding all of the, you know, [00:12:00] comments on your issues or checking GitHub actions and stuff.
[00:12:02] Speaker: The second thing I think about is the human agent interface. So this is like how do we get humans to interact with agents? Bye. I already showed you one variety of our human agent interface. It's basically a chat window where you can browse through the agent's results and things like this. This is very, very difficult.
[00:12:18] Speaker: I, I don't think anybody has a good answer to this, and I don't think we have a good answer to this, but the, the guiding principles that I'm trying to follow are we want to present enough info to the user. So we want to present them with, you know, what the agent is doing in the form of a kind of.
[00:12:36] Speaker: English descriptions. So you can see here you can see here every time it takes an action, it says like, I will help you create a script for sending emails. When it runs a bash command. Sorry, that's a little small. When it runs a bash command, it will say ran a bash command. It won't actually show you the whole bash command or the whole Jupyter notebook because it can be really large, but you can open it up and see if you [00:13:00] want to, by clicking on this.
[00:13:01] Speaker: So like if you want to explore more, you can click over to the Jupyter notebook and see what's displayed in the Jupyter notebook. And you get like lots and lots of information. So that's one thing.
[00:13:16] Speaker: Another thing is go where the user is. So like if the user's already interacting in a particular setting then I'd like to, you know, integrate into that setting, but only to a point. So at OpenHands, we have a chat UI for interaction. We have a GitHub plugin for tagging and resolving issues. So basically what you do is you Do at open hands agent and the open hands agent will like see that comment and be able to go in and fix things.
[00:13:42] Speaker: So if you say at open hands agent tests are failing on this PR, please fix the tests. It will go in and fix the test for you and stuff like this. Another thing we have is a remote runtime for launching headless jobs. So if you want to launch like a fleet of agents to solve, you know five different problems at once, you can also do [00:14:00] that through an API.
[00:14:00] Speaker: So we have we have these interfaces and this probably depends on the use case. So like, depending if you're a coding agent, you want to do things one way. If you're a like insurance auditing agent, you'll want to do things other ways, obviously.
[00:14:13] Choosing the Right Language Model for Agents
[00:14:13] Speaker: Another thing I think about a lot is choosing a language model.
[00:14:16] Speaker: And for agentic LMs we have to have a bunch of things work really well. The first thing is really, really good instruction following ability. And if you have really good instruction following ability, it opens up like a ton of possible applications for you. Tool use and coding ability. So if you provide tools, it needs to be able to use them well.
[00:14:38] Speaker: Environment understanding. So it needs, like, if you're building a web agent, it needs to be able to understand web pages either through vision or through text. And error awareness and recovery ability. So, if it makes a mistake, it needs to be able to, you know, figure out why it made a mistake, come up with alternative strategies, and other things like this.
[00:14:58] Speaker: [00:15:00] Under the hood, in all of the demos that I did now Cloud, we're using Cloud. Cloud has all of these abilities very good, not perfect, but very good. Most others don't have these abilities quite as much. So like GPT 4. 0 doesn't have very good error recovery ability. And so because of this, it will go into loops and do the same thing over and over and over again.
[00:15:22] Speaker: Whereas Claude does not do this. Claude, if you, if you use the agents enough, you get used to their kind of like personality. And Claude says, Hmm, let me try a different approach a lot. So, you know, obviously it's been trained in some way to, you know, elicit this ability. We did an evaluation. This is old.
[00:15:40] Speaker: And we need to update this basically, but we evaluated CLOD, mini LLAMA 405B, DeepSeq 2. 5 on being a good code agent within our framework. And CLOD was kind of head and shoulders above the rest. GPT 40 was kind of okay. The best open source model was LLAMA [00:16:00] 3. 1 405B. This needs to be updated because this is like a few months old by now and, you know, things are moving really, really fast.
[00:16:05] Speaker: But I still am under the impression that Claude is the best. The other closed models are, you know, not quite as good. And then the open models are a little bit behind that. Grok, I, we haven't tried Grok at all, actually. So, it's a good question. If you want to try it I'd be happy to help.
[00:16:24] Speaker: Cool.
[00:16:24] Planning and Workflow for Agents
[00:16:24] Speaker: Another thing is planning. And so there's a few considerations for planning. The first one is whether you have a curated plan or you have it generated on the fly. And so for solving GitHub issues, you can kind of have an overall plan. Like the plan is first reproduce. If there's an issue, first write tests to reproduce the issue or to demonstrate the issue.
[00:16:50] Speaker: After that, run the tests and make sure they fail. Then go in and fix the tests. Run the tests again to make sure they pass and then you're done. So that's like a pretty good workflow [00:17:00] for like solving coding issues. And you could curate that ahead of time. Another option is to let the language model basically generate its own plan.
[00:17:10] Speaker: And both of these are perfectly valid. Another one is explicit structure versus implicit structure. So let's say you generate a plan. If you have explicit structure, you could like write a multi agent system, and the multi agent system would have your reproducer agent, and then it would have your your bug your test writer agent, and your bug fixer agent, and lots of different agents, and you would explicitly write this all out in code, and then then use it that way.
[00:17:38] Speaker: On the other hand, you could just provide a prompt that says, please do all of these things in order. So in OpenHands, we do very light planning. We have a single prompt. We don't have any multi agent systems. But we do provide, like, instructions about, like, what to do first, what to do next, and other things like this.
[00:17:56] Speaker: I'm not against doing it the other way. But I laid [00:18:00] out some kind of justification for this in this blog called Don't Sleep on Single Agent Systems. And the basic idea behind this is if you have a really, really good instruction following agent it will follow the instructions as long as things are working according to your plan.
[00:18:14] Speaker: But let's say you need to deviate from your plan, you still have the flexibility to do this. And if you do explicit structure through a multi agent system, it becomes a lot harder to do that. Like, you get stuck when things deviate from your plan. There's also some other examples, and I wanted to introduce a few papers.
[00:18:30] Speaker: So one paper I liked recently is this paper called CoAct where you generate plans and then go in and fix them. And so the basic idea is like, if you need to deviate from your plan, you can You know, figure out that your plan was not working and go back and deviate from it.
[00:18:49] Speaker: Another thing I think about a lot is specifying common workflows. So we're trying to tackle a software development and I already showed like three use cases where we do [00:19:00] software development and when we. We do software development, we do a ton of different things, but we do them over and over and over again.
[00:19:08] Speaker: So just to give an example we fix GitHub actions when GitHub actions are failing. And we do that over and over and over again. That's not the number one thing that software engineers do, but it's a, you know, high up on the list. So how can we get a list of all of, like, the workflows that people are working on?
[00:19:26] Speaker: And there's a few research works that people have done in this direction. One example is manual prompting. So there's this nice paper called STEP that got state of the art on the WebArena Web Navigation Benchmark where they came up with a bunch of manual workflows for solving different web navigation tasks.
[00:19:43] Speaker: And we also have a paper recently called Agent Workflow Memory where the basic idea behind this is we want to create self improving agents that learn from their past successes. And the way it works is is we have a memory that has an example of lots of the previous [00:20:00] workflows that people have used. And every time the agent finishes a task and it self judges that it did a good job at that task, you take that task, you break it down into individual workflows included in that, and then you put it back in the prompt for the agent to work next time.
[00:20:16] Speaker: And this we demonstrated that this leads to a 22. 5 percent increase on WebArena after 40 examples. So that's a pretty, you know, huge increase by kind of self learning and self improvement.
[00:20:31] Speaker: Another thing is exploration. Oops. And one thing I think about is like, how can agents learn more about their environment before acting? And I work on coding and web agents, and there's, you know, a few good examples of this in, in both areas. Within coding, I view this as like repository understanding, understanding the code base that you're dealing with.
[00:20:55] Speaker: And there's an example of this, or a couple examples of this, one example being AgentList. [00:21:00] Where they basically create a map of the repo and based on the map of the repo, they feed that into the agent so the agent can then navigate the repo and and better know where things are. And for web agents there's an example of a paper called Bagel, and basically what they do is they have the agent just do random tasks on a website, explore the website, better understand the structure of the website, and then after that they they feed that in as part of the product.
[00:21:27] Speaker: Part seven is search. Right now in open hands, we just let the agent go on a linear search path. So it's just solving the problem once. We're using a good agent that can kind of like recover from errors and try alternative things when things are not working properly, but still we only have a linear search path.
[00:21:45] Speaker: But there's also some nice work in 2024 that is about exploring multiple paths. So one example of this is there's a paper called Tree Search for Language Agents. And they basically expand multiple paths check whether the paths are going well, [00:22:00] and if they aren't going well, you rewind back. And on the web, this is kind of tricky, because, like, how do you rewind when you accidentally ordered something you don't want on Amazon?
[00:22:09] Speaker: It's kind of, you know, not, not the easiest thing to do. For code, it's a little bit easier, because you can just revert any changes that you made. But I, I think that's an interesting topic, too.
[00:22:21] Evaluation and Future Predictions for Agents
[00:22:21] Speaker: And then finally evaluation. So within our development for evaluation, we want to do a number of things. The first one is fast sanity checks.
[00:22:30] Speaker: And in order to do this, we want things we can run really fast, really really cheaply. So for web, we have something called mini world of bits, which is basically these trivial kind of web navigation things. We have something called the Adder Code Editing Benchmark, where it's just about editing individual files that we use.
[00:22:48] Speaker: But we also want highly realistic evaluation. So for the web, we have something called WebArena that we created at CMU. This is web navigation on real real open source websites. So it's open source [00:23:00] websites that are actually used to serve shops or like bulletin boards or other things like this.
[00:23:07] Speaker: And for code, we use Swebench, which I think a lot of people may have heard of. It's basically a coding benchmark that comes from real world pull requests on GitHub. So if you can solve those, you can also probably solve other real world pull requests. I would say we still don't have benchmarks for the fur full versatility of agents.
[00:23:25] Speaker: So, for example We don't have benchmarks that test whether agents can code and do web navigation. But we're working on that and hoping to release something in the next week or two. So if that sounds interesting to you, come talk to me and I, I will tell you more about it.
[00:23:42] Speaker: Cool. So I don't like making predictions, but I was told that I should be somewhat controversial, I guess, so I will, I will try to do it try to do it anyway, although maybe none of these will be very controversial. Um, the first thing is agent oriented LLMs like large language models for [00:24:00] agents.
[00:24:00] Speaker: My, my prediction is every large LM trainer will be focusing on training models as agents. So every large language model will be a better agent model by mid 2025. Competition will increase, prices will go down, smaller models will become competitive as agents. So right now, actually agents are somewhat expensive to run in some cases, but I expect that that won't last six months.
[00:24:23] Speaker: I, I bet we'll have much better agent models in six months. Another thing is instruction following ability, specifically in agentic contexts, will increase. And what that means is we'll have to do less manual engineering of agentic workflows and be able to do more by just prompting agents in more complex ways.
[00:24:44] Speaker: Cloud is already really good at this. It's not perfect, but it's already really, really good. And I expect the other models will catch up to Cloud pretty soon. Error correction ability will increase, less getting stuck in loops. Again, this is something that Cloud's already pretty good at and I expect the others will, will follow.[00:25:00]
[00:25:01] Speaker: Agent benchmarks. Agent benchmarks will start saturating.
[00:25:05] Speaker: And Swebench I think WebArena is already too easy. It, it is, it's not super easy, but it's already a bit too easy because the tasks we do in there are ones that take like two minutes for a human. So not, not too hard. And kind of historically in 2023 our benchmarks were too easy. So we built harder benchmarks like WebArena and Swebench were both built in 2023.
[00:25:31] Future of Agent Development
[00:25:31] Speaker: In 2024, our agents were too bad, so we built agents and now we're building better agents. In 2025, our benchmarks will be too easy, so we'll build better benchmarks, I'm, I'm guessing. So, I would expect to see much more challenging agent benchmarks come out, and we're already seeing some of them.
[00:25:49] Speaker: In 2026, I don't know. I didn't write AGI, but we'll, we'll, we'll see.
[00:25:56] Human-Agent Interaction Challenges
[00:25:56] Speaker: Then the human agent computer interface. I think one thing that [00:26:00] we'll want to think about is what do we do at 75 percent success rate at things that we like actually care about? Right now we have 53 percent or 55 percent on Swebench verified, which is real world GitHub PRs.
[00:26:16] Speaker: My impression is that the actual. Actual ability of models is maybe closer to 30 to 40%. So 30 to 40 percent of the things that I want an agent to solve on my own repos, it just solves without any human intervention. 80 to 90 percent it can solve without me opening an IDE. But I need to give it feedback.
[00:26:36] Speaker: So how do we, how do we make that interaction smooth so that humans can audit? The work of agents that are really, really good, but not perfect is going to be a big challenge.
[00:26:48] Expanding Agent Use Beyond Programming
[00:26:48] Speaker: How can we expose the power of programming agents to other industries? So like as programmers, I think not all of us are using agents every day in our programming, although we probably will be [00:27:00] in in months or maybe a year.
[00:27:02] Speaker: But I, I think it will come very naturally to us as programmers because we know code. We know, you know. Like how to architect software and stuff like that. So I think the question is how do we put this in the hands of like a lawyer or a chemist or somebody else and have them also be able to, you know, interact with it as naturally as we can.
[00:27:25] Redesigning Systems for Agent Efficiency
[00:27:25] Speaker: Another interesting thing is how can we redesign our existing systems for agents? So we had a paper on API based web agents, and basically what we showed is If you take a web agent and the agent interacts not with a website, but with APIs, the accuracy goes way up just because APIs are way easier to interact with.
[00:27:42] Speaker: And in fact, like when I ask the, well, our agent, our agent is able to browse websites, but whenever I want it to interact with GitHub, I tell it do not browse the GitHub website. Use the GitHub API because it's way more successful at doing that. So maybe, you know, every website is going to need to have [00:28:00] an API because we're going to be having agents interact with them.
[00:28:03] Accelerating Progress with Agent Technology
[00:28:03] Speaker: About progress, I think progress will get faster. It's already fast. A lot of people are already overwhelmed, but I think it will continue. The reason why is agents are building agents. And better agents will build better agents faster. So I expect that you know, if you haven't interacted with a coding agent yet, it's pretty magical, like the stuff that it can do.
[00:28:24] Speaker: So yeah.
[00:28:28] Call to Action for Open Source Contributions
[00:28:28] Speaker: And I have a call to action. I'm honestly, like I've been working on, you know, natural language processing and, and Language models for what, 15 years now. And even for me, it's pretty impressive what like AI agents powered by strong language models can do. On the other hand, I believe that we should really make these powerful tools accessible.
[00:28:49] Speaker: And what I mean by this is I don't think like, you know, We, we should have these be opaque or limited to only a set, a certain set of people. I feel like they should be [00:29:00] affordable. They shouldn't be increasing the, you know, difference in the amount of power that people have. If anything, I'd really like them to kind of make it It's possible for people who weren't able to do things before to be able to do them well.
[00:29:13] Speaker: Open source is one way to do that. That's why I'm working on open source. There are other ways to do that. You know, make things cheap, make things you know, so you can serve them to people who aren't able to afford them. Easily, like Duolingo is one example where they get all the people in the US to pay them 20 a month so that they can give all the people in South America free, you know, language education, so they can learn English and become, you know like, and become, you know, More attractive on the job market, for instance.
[00:29:41] Speaker: And so I think we can all think of ways that we can do that sort of thing. And if that resonates with you, please contribute. Of course, I'd be happy if you contribute to OpenHands and use it. But another way you can do that is just use open source solutions, contribute to them, research with them, and train strong open source [00:30:00] models.
[00:30:00] Speaker: So I see, you know, Some people in the room who are already training models. It'd be great if you could train models for coding agents and make them cheap. And yeah yeah, please. I, I was thinking about you among others. So yeah, that's all I have. Thanks.
[00:30:20] Speaker 2: Slight, slightly controversial. Tick is probably the nicest way to say hot ticks. Any hot ticks questions, actual hot ticks?
[00:30:31] Speaker: Oh, I can also show the other agents that were working, if anybody's interested, but yeah, sorry, go ahead.
[00:30:36] Q&A: Agent Performance and Benchmarks
[00:30:36] Speaker 3: Yeah, I have a couple of questions. So they're kind of paired, maybe. The first thing is that you said that You're estimating that your your agent is successfully resolving like something like 30 to 40 percent of your issues, but that's like below what you saw in Swebench.
[00:30:52] Speaker 3: So I guess I'm wondering where that discrepancy is coming from. And then I guess my other second question, which is maybe broader in scope is that [00:31:00] like, if, if you think of an agent as like a junior developer, and I say, go do something, then I expect maybe tomorrow to get a Slack message being like, Hey, I ran into this issue.
[00:31:10] Speaker 3: How can I resolve it? And, and, like you said, your agent is, like, successfully solving, like, 90 percent of issues where you give it direct feedback. So, are you thinking about how to get the agent to reach out to, like, for, for planning when it's, when it's stuck or something like that? Or, like, identify when it runs into a hole like that?
[00:31:30] Speaker: Yeah, so great. These are great questions. Oh,
[00:31:32] Speaker 3: sorry. The third question, which is a good, so this is the first two. And if so, are you going to add a benchmark for that second question?
[00:31:40] Speaker: Okay. Great. Yeah. Great questions. Okay. So the first question was why do I think it's resolving less than 50 percent of the issues on Swebench?
[00:31:48] Speaker: So first Swebench is on popular open source repos, and all of these popular open source repos were included in the training data for all of the language models. And so the language [00:32:00] models already know these repos. In some cases, the language models already know the individual issues in Swebench.
[00:32:06] Speaker: So basically, like, some of the training data has leaked. And so it, it definitely will overestimate with respect to that. I don't think it's like, you know, Horribly, horribly off but I think, you know, it's boosting the accuracy by a little bit. So, maybe that's the biggest reason why. In terms of asking for help, and whether we're benchmarking asking for help yes we are.
[00:32:29] Speaker: So one one thing we're working on now, which we're hoping to put out soon, is we we basically made SuperVig. Sweep edge issues. Like I'm having a, I'm having a problem with the matrix multiply. Please help. Because these are like, if anybody's run a popular open source, like framework, these are what half your issues are.
[00:32:49] Speaker: You're like users show up and say like, my screen doesn't work. What, what's wrong or something. And so then you need to ask them questions and how to reproduce. So yeah, we're, we're, we're working on [00:33:00] that. I think. It, my impression is that agents are not very good at asking for help, even Claude. So like when, when they ask for help, they'll ask for help when they don't need it.
[00:33:11] Speaker: And then won't ask for help when they do need it. So this is definitely like an issue, I think.
[00:33:20] Speaker 4: Thanks for the great talk. I also have two questions.
[00:33:23] Q&A: Web Agents and Interaction Methods
[00:33:23] Speaker 4: It's first one can you talk a bit more about how the web agent interacts with So is there a VLM that looks at the web page layout and then you parse the HTML and select which buttons to click on? And if so do you think there's a future where there's like, so I work at Bing Microsoft AI.
[00:33:41] Speaker 4: Do you think there's a future where the same web index, but there's an agent friendly web index where all the processing is done offline so that you don't need to spend time. Cleaning up, like, cleaning up these TML and figuring out what to click online. And any thoughts on, thoughts on that?
[00:33:57] Speaker: Yeah, so great question. There's a lot of work on web [00:34:00] agents. I didn't go into, like, all of the details, but I think there's There's three main ways that agents interact with websites. The first way is the simplest way and the newest way, but it doesn't work very well, which is you take a screenshot of the website and then you click on a particular pixel value on the website.
[00:34:23] Speaker: And Like models are not very good at that at the moment. Like they'll misclick. There was this thing about how like clawed computer use started like looking at pictures of Yellowstone national park or something like this. I don't know if you heard about this anecdote, but like people were like, oh, it's so human, it's looking for vacation.
[00:34:40] Speaker: And it was like, no, it probably just misclicked on the wrong pixels and accidentally clicked on an ad. So like this is the simplest way. The second simplest way. You take the HTML and you basically identify elements in the HTML. You don't use any vision whatsoever. And then you say, okay, I want to click on this element.
[00:34:59] Speaker: I want to enter text [00:35:00] in this element or something like that. But HTML is too huge. So it actually, it usually gets condensed down into something called an accessibility tree, which was made for screen readers for visually impaired people. And So that's another way. And then the third way is kind of a hybrid where you present the screenshot, but you also present like a textual summary of the output.
[00:35:18] Speaker: And that's the one that I think will probably work best. What we're using is we're just using text at the moment. And that's just an implementation issue that we haven't implemented the. Visual stuff yet, but that's kind of like we're working on it now. Another thing that I should point out is we actually have two modalities for web browsing.
[00:35:35] Speaker: Very recently we implemented this. And the reason why is because if you want to interact with full websites you will need to click on all of the elements or have the ability to click on all of the elements. But most of our work that we need websites for is just web browsing and like gathering information.
[00:35:50] Speaker: So we have another modality where we convert all of it to markdown because that's like way more concise and easier for the agent to deal with. And then [00:36:00] can we create an index specifically for agents, maybe a markdown index or something like that would be, you know, would make sense. Oh, how would I make a successor to Swebench?
[00:36:10] Speaker: So I mean, the first thing is there's like live code bench, which live code bench is basically continuously updating to make sure it doesn't leak into language model training data. That's easy to do for Swebench because it comes from real websites and those real websites are getting new issues all the time.
[00:36:27] Speaker: So you could just do it on the same benchmarks that they have there. There's also like a pretty large number of things covering various coding tasks. So like, for example, Swebunch is mainly fixing issues, but there's also like documentation, there's generating tests that actually test the functionality that you want.
[00:36:47] Speaker: And there there was a paper by a student at CMU on generating tests and stuff like that. So I feel like. Swebench is one piece of the puzzle, but you could also have like 10 different other tasks and then you could have like a composite [00:37:00] benchmark where you test all of these abilities, not just that particular one.
[00:37:04] Speaker: Well, lots, lots of other things too, but
[00:37:11] Speaker 2: Question from across. Use your mic, it will help. Um,
[00:37:15] Speaker 5: Great talk. Thank you.
[00:37:16] Q&A: Agent Architectures and Improvements
[00:37:16] Speaker 5: My question is about your experience designing agent architectures. Specifically how much do you have to separate concerns in terms of tasks specific agents versus having one agent to do three or five things with a gigantic prompt with conditional paths and so on.
[00:37:35] Speaker: Yeah, so that's a great question. So we have a basic coding and browsing agent. And I won't say basic, like it's a good, you know, it's a good agent, but it does coding and browsing. And it has instructions about how to do coding and browsing. That is enough for most things. Especially given a strong language model that has a lot of background knowledge about how to solve different types of tasks and how to use different APIs and stuff like that.
[00:37:58] Speaker: We do have [00:38:00] a mechanism for something called micro agents. And micro agents are basically something that gets added to the prompt when a trigger is triggered. Right now it's very, very rudimentary. It's like if you detect the word GitHub anywhere, you get instructions about how to interact with GitHub, like use the API and don't browse.
[00:38:17] Speaker: Also another one that I just added is for NPM, the like JavaScript package manager. And NPM, when it runs and it hits a failure, it Like hits in interactive terminals where it says, would you like to quit? Yep. Enter yes. And if that does it, it like stalls our agent for the time out until like two minutes.
[00:38:36] Speaker: So like I added a new microagent whenever it started using NPM, it would Like get instructions about how to not use interactive terminal and stuff like that. So that's our current solution. Honestly, I like it a lot. It's simple. It's easy to maintain. It works really well and stuff like that. But I think there is a world where you would want something more complex than that.
[00:38:55] Speaker 5: Got it. Thank you.
[00:38:59] Speaker 6: I got a [00:39:00] question about MCP. I feel like this is the Anthropic Model Context Protocol. It seems like the most successful type of this, like, standardization of interactions between computers and agents. Are you guys adopting it? Is there any other competing standard?
[00:39:16] Speaker 6: Anything, anything thought about it?
[00:39:17] Speaker: Yeah, I think the Anth, so the Anthropic MCP is like, a way to It, it's essentially a collection of APIs that you can use to interact with different things on the internet. I, I think it's not a bad idea, but it, it's like, there's a few things that bug me a little bit about it.
[00:39:40] Speaker: It's like we already have an API for GitHub, so why do we need an MCP for GitHub? Right. You know, like GitHub has an API, the GitHub API is evolving. We can look up the GitHub API documentation. So it seems like kind of duplicated a little bit. And also they have a setting where [00:40:00] it's like you have to spin up a server to serve your GitHub stuff.
[00:40:04] Speaker: And you have to spin up a server to serve your like, you know, other stuff. And so I think it makes, it makes sense if you really care about like separation of concerns and security and like other things like this, but right now we haven't seen, we haven't seen that. To have a lot more value than interacting directly with the tools that are already provided.
[00:40:26] Speaker: And that kind of goes into my general philosophy, which is we're already developing things for programmers. You know,
[00:40:36] Speaker: how is an agent different than from a programmer? And it is different, obviously, you know, like agents are different from programmers, but they're not that different at this point. So we can kind of interact with the interfaces we create for, for programmers. Yeah. I might change my mind later though.
[00:40:51] Speaker: So we'll see.
[00:40:54] Speaker 7: Yeah. Hi. Thanks. Very interesting talk. You were saying that the agents you have right now [00:41:00] solve like maybe 30 percent of your, your issues out of the gate. I'm curious of the things that it doesn't do. Is there like a pattern that you observe? Like, Oh, like these are the sorts of things that it just seems to really struggle with, or is it just seemingly random?
[00:41:15] Speaker: It's definitely not random. It's like, if you think it's more complex than it's. Like, just intuitively, it's more likely to fail. I've gotten a bit better at prompting also, so like, just to give an example it, it will sometimes fail to fix a GitHub workflow because it will not look at the GitHub workflow and understand what the GitHub workflow is doing before it solves the problem.
[00:41:43] Speaker: So I, I think actually probably the biggest thing that it fails at is, um, er, that our, our agent plus Claude fails at is insufficient information gathering before trying to solve the task. And so if you provide all, if you provide instructions that it should do information [00:42:00] gathering beforehand, it tends to do well.
[00:42:01] Speaker: If you don't provide sufficient instructions, it will try to solve the task without, like, fully understanding the task first, and then fail, and then you need to go back and give feedback. You know, additional feedback. Another example, like, I, I love this example. While I was developing the the monitor website that I, I showed here, we hit a really tricky bug where it was writing out a cache file to a different directory than it was reading the cache file from.
[00:42:26] Speaker: And I had no idea what to do. I had no idea what was going on. I, I thought the bug was in a different part of the code, but what I asked it to do was come up with five possible reasons why this could be failing and decreasing order of likelihood and examine all of them. And that worked and it could just go in and like do that.
[00:42:44] Speaker: So like I think a certain level of like scaffolding about like how it should sufficiently Gather all the information that's necessary in order to solve a task is like, if that's missing, then that's probably the biggest failure point at the moment. [00:43:00]
[00:43:01] Speaker 7: Thanks.
[00:43:01] Speaker 6: Yeah.
[00:43:06] Speaker 6: I'm just, I'm just using this as a chance to ask you all my questions.
[00:43:09] Q&A: Self-Improving Agents and Authentication
[00:43:09] Speaker 6: You had a, you had a slide on here about like self improving agents or something like that with memory. It's like a really throwaway slide for like a super powerful idea. It got me thinking about how I would do it. I have no idea how.
[00:43:21] Speaker 6: So I just wanted you to chain a thought more on this.
[00:43:25] Speaker: Yeah, self, self improving. So I think the biggest reason, like the simplest possible way to create a self improving agent. The problem with that is to have a really, really strong language model that with infinite context, and it can just go back and look at like all of its past experiences and, you know, learn from them.
[00:43:46] Speaker: You might also want to remove the bad stuff just so it doesn't over index on it's like failed past experiences. But the problem is a really powerful language model is large. Infinite context is expensive. We don't have a good way to [00:44:00] index into it because like rag, Okay. At least in my experience, RAG from language to code doesn't work super well.
[00:44:08] Speaker: So I think in the end, it's like, that's the way I would like to solve this problem. I'd like to have an infinite context and somehow be able to index into it appropriately. And I think that would mostly solve it. Another thing you can do is fine tuning. So I think like RAG is one way to get information into your model.
[00:44:23] Speaker: Fine tuning is another way to get information into your model. So. That might be another way of continuously improving. Like you identify when you did a good job and then just add all of the good examples into your model.
[00:44:34] Speaker 6: Yeah. So, you know, how like Voyager tries to write code into a skill library and then you reuse as a skill library, right?
[00:44:40] Speaker 6: So that it improves in the sense that it just builds up the skill library over time.
[00:44:44] Speaker: Yep.
[00:44:44] Speaker 6: One thing I was like thinking about and there's this idea of, from, from Devin, your, your arch nemesis of playbooks. I don't know if you've seen them.
[00:44:52] Speaker: Yeah, I mean, we're calling them workflows, but they're simpler.
[00:44:55] Speaker 6: Yeah, so like, basically, like, you should, like, once a workflow works, you can kind of, [00:45:00] like, persist them as a skill library. Yeah. Right? Like I, I feel like that there's a, that's like some in between, like you said, you know, it's hard to do rag between language and code, but I feel like that is ragged for, like, I've done this before, last time I did it, this, this worked.
[00:45:14] Speaker 6: So I'm just going to shortcut. All the stuff that failed before.
[00:45:18] Speaker: Yeah, I totally, I think it's possible. It's just, you know, not, not trivial at the same time. I'll explain the two curves. So basically, the base, the baseline is just an agent that does it from scratch every time. And this curve up here is agent workflow memory where it's like adding the successful experiences back into the prompt.
[00:45:39] Speaker: Why is this improving? The reason why is because just it failed on the first few examples and for the average to catch up it, it took a little bit of time. So it's not like this is actually improving it. You could just basically view the this one is constant and then this one is like improving.
[00:45:56] Speaker: Like this, basically you can see it's continuing to go [00:46:00] up.
[00:46:01] Speaker 8: How do you think we're going to solve the authentication problem for agents right now?
[00:46:05] Speaker: When you say authentication, you mean like credentials, like, yeah.
[00:46:09] Speaker 8: Yeah. Cause I've seen a few like startup solutions today, but it seems like it's limited to the amount of like websites or actual like authentication methods that it's capable of performing today.
[00:46:19] Speaker: Yeah. Great questions. So. My preferred solution to this at the moment is GitHub like fine grained authentication tokens and GitHub fine grained authentication tokens allow you to specify like very free. On a very granular basis on this repo, you have permission to do this, on this repo, you have permission to do this.
[00:46:41] Speaker: You also can prevent people from pushing to the main branch unless they get approved. You can do all of these other things. And I think these were all developed for human developers. Or like, the branch protection rules were developed for human developers. The fine grained authentication tokens were developed for GitHub apps.
[00:46:56] Speaker: I think for GitHub, maybe [00:47:00] just pushing this like a little bit more is the way to do this. For other things, they're totally not prepared to give that sort of fine grained control. Like most APIs don't have something like a fine grained authentication token. And that goes into my like comment that we're going to need to prepare the world for agents, I think.
[00:47:17] Speaker: But I think like the GitHub authentication tokens are like a good template for how you could start doing that maybe, but yeah, I don't, I don't, I don't have an answer.
[00:47:25] Speaker 8: I'll let you know if I find one.
[00:47:26] Speaker: Okay. Yeah.
[00:47:31] Live Demonstration and Closing Remarks
[00:47:31] Speaker: I'm going to finish up. Let, let me just see.
[00:47:37] Speaker: Okay. So this one this one did write a script. I'm not going to actually read it for you. And then the other one, let's see.
[00:47:51] Speaker: Yeah. So it sent a PR, sorry. What is, what is the PR URL?[00:48:00]
[00:48:02] Speaker: So I don't, I don't know if this sorry, that's taking way longer than it should. Okay, cool. Yeah. So this one sent a PR. I'll, I'll tell you later if this actually like successfully Oh, no, it's deployed on Vercel, so I can actually show you, but let's, let me try this real quick. Sorry. I know I don't have time.
[00:48:24] Speaker: Yeah, there you go. I have pie charts now. So it's so fun. It's so fun to play with these things. Cause you could just do that while I'm giving a, you know, talk and things like that. So, yeah, thanks.
Share this post