




As alluded to on the pod, LangChain has just launched LangChain Hub: “the go-to place for developers to discover new use cases and polished prompts.” It’s available to everyone with a LangSmith account, no invite code necessary. Check it out!
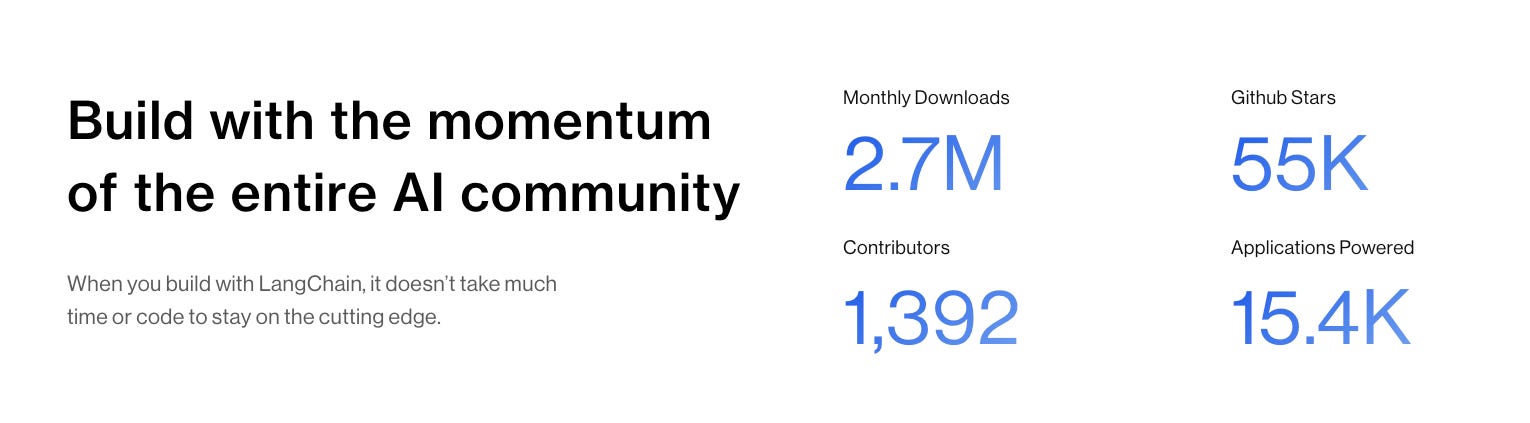
In 2023, LangChain has speedrun the race from 2:00 to 4:00 to 7:00 Silicon Valley Time. From the back to back $10m Benchmark seed and (rumored) $20-25m Sequoia Series A in April, to back to back critiques of “LangChain is Pointless” and “The Problem with LangChain” in July1, to teaching with Andrew Ng and keynoting at basically every AI conference this fall (including ours), it has been an extreme rollercoaster for Harrison and his growing team creating one of the most popular (>60k stars at time of writing) building blocks for AI Engineers.
LangChain’s Origins
The first commit to LangChain shows its humble origins as a light wrapper around Python’s formatter.format for prompt templating. But as Harrison tells the story, even his first experience with text-davinci-002 in early 2022 was focused on chatting with data from their internal company Notion2 and Slack, what is now known as Retrieval Augmented Generation (RAG).
As the Generative AI meetup scene came to life post Stable Diffusion3, Harrison saw a need for common abstractions for what people were building with text LLMs at the time:
LLM Math, aka Riley Goodside’s “You Can’t Do Math” REPL-in-the-loop (PR #8)
Self-Ask With Search, Ofir Press’ agent pattern (PR #9) (later ReAct, PR #24)
Adapters for OpenAI, Cohere, and HuggingFaceHub
All this was built and launched in a few days from Oct 16-25, 2022.

Turning research ideas/exciting usecases into software quickly and often has been in the LangChain DNA from Day 1 and likely a big driver of LangChain’s success, to date amassing the largest community of AI Engineers and being the default launch framework for every big name from Nvidia to OpenAI:
Dancing with Giants
But AI Engineering is built atop of constantly moving tectonic shifts:
ChatGPT launched in November (“The Day the AGI Was Born”) and the API released in March. Before the ChatGPT API, OpenAI did not have a chat endpoint. In order to build a chatbot with history, you had to make sure to chain all messages and prompt for completion. LangChain made it easy to do that out of the box, which was a huge driver of usage.
Today, OpenAI has gone all-in on the chat API and is deprecating the old completions models, essentially baking in the chat pattern as the default way most engineers should interact with LLMs… and reducing (but not eliminating) the value of ConversationChains.
And there have been more updates since: Plugins released in API form as Functions in June (one of our top pods ever… reducing but not eliminating the value of OutputParsers) and Finetuning in August (arguably reducing some need for Retrieval and Prompt tooling).
With each update, OpenAI and other frontier model labs realign the roadmaps of this nascent industry, and Harrison credits the modular design of LangChain in staying relevant. LangChain has not been merely responsive either: LangChain added Agents in November, well before they became the hottest topic of the AI Summer, and now Agents feature as one of LangChain’s top two usecases.
LangChain’s problem for podcasters and newcomers alike is its sheer scope - it is the world’s most complete AI framework, but it also has a sprawling surface area that is difficult to fully grasp or document in one sitting. This means it’s time for the trademark Latent Space move (ChatGPT, GPT4, Auto-GPT, and Code Interpreter Advanced Data Analysis GPT4.5): the executive summary!
What is LangChain?
As Harrison explains, LangChain is an open source framework for building context-aware reasoning applications, available in Python and JS/TS.
It launched in Oct 2022 with the central value proposition of “composability”4, aka the idea that every AI engineer will want to switch LLMs, and combine LLMs with other things into “chains”, using a flexible interface that can be saved via a schema.

Today, LangChain’s principal offerings can be grouped as:
Components: isolated modules/abstractions
Model I/O
Models (for LLM/Chat/Embeddings, from OpenAI, Anthropic, Cohere, etc)
Prompts (Templates, ExampleSelectors5, OutputParsers)
Retrieval (revised and reintroduced in March)
Document Loaders (eg from CSV, JSON, Markdown, PDF)
Text Splitters (15+ various strategies6 for chunking text to fit token limits)
Retrievers (generic interface for turning an unstructed query into a set of documents - for self-querying7, contextual compression, ensembling)
Vector Stores (retrievers that search by similarity of embeddings)
Indexers (sync documents from any source into a vector store without duplication)
Memory (for long running chats, whether a simple Buffer, Knowledge Graph, Summary, or Vector Store)
Use-Cases: compositions of Components
Chains: combining a PromptTemplate, LLM Model and optional OutputParser
with Router, Sequential, and Transform Chains for advanced usecases
savable, sharable schemas that can be loaded from LangChainHub
Agents: a chain that has access to a suite of tools, of nondeterministic8 length because the LLM is used as a reasoning engine to determine which actions to take and in which order. Notable 100LOC explainer here.
Tools (interfaces that an agent can use to interact with the world - preset list here. Includes things like ChatGPT plugins, Google Search, WolframAlpha. Groups of tools are bundled up as toolkits)
AgentExecutor (the agent runtime, basically the
whileloop, with support for controls, timeouts, memory sharing, etc)
LangChain has also added a Callbacks system for instrumenting each stage of LLM, Chain, and Agent calls (which enables LangSmith, LangChain’s first cloud product), and most recently an Expression Language, a declarative way to compose chains.
LangChain the company incorporated in January 2023, announced their seed round in April, and launched LangSmith in July. At time of writing, the company has 93k followers9, their Discord has 31k members and their weekly webinars are attended by thousands of people live.
The full-featuredness of LangChain means it is often the first starting point for building any mainstream LLM use case10, because they are most likely to have working guides for the new developer. Logan (our first guest!) from OpenAI has been a notable fan of both LangChain and LangSmith (they will be running the first LangChain + OpenAI workshop at AI Eng Summit).
However, LangChain is not without its critics, with Aravind Srinivas, Jim Fan, Max Woolf, Mckay Wrigley11 and the general Reddit/HN community describing frustrations with the value of their abstractions, and many are attempting to write their own (the common experience of adding and then removing LangChain is something we covered in our Agents writeup). Harrison compares this with the timeless ORM debate on the value of abstractions.

LangSmith
Last month, Harrison launched LangSmith, their LLM observability tool and first cloud product. LangSmith makes it easy to monitor all the different primitives that LangChain offers (agents, chains, LLMs) as well as making it easy to share and evaluate them both through heuristics (i.e. manually written ones) and “LLM evaluating LLM” flows.

The top HN comment in the “LangChain is Pointless” thread observed that orchestration is the smallest part of the work, and the bulk of it is prompt tuning and data serialization. When asked this directly our pod, Harrison agreed:
“I agree that those are big pain points that get exacerbated when you have these complex chains and agents where you can't really see what's going on inside of them. And I think that's partially why we built Langsmith…” (48min mark)
You can watch the full launch on the LangChain YouTube:
It’s clear that the target audience for LangChain is expanding to folks who are building complex, production applications rather than focusing on the simpler “Q&A your docs” use cases that made it popular in the first place. As the AI Engineer space matures, there will be more and more tools graduating from supporting “hobby” projects to more enterprise-y use cases.
In this episode we run through some of the history of LangChain, how it’s growing from an open source project to one of the highest valued AI startups out there, and its future. We hope you enjoy it!

Show Notes
awesome-langchain:
Harrison’s links
Timestamps
[00:00:00] Introduction
[00:00:48] Harrison's background and how sports led him into ML
[00:04:54] The inspiration for creating LangChain - abstracting common patterns seen in other GPT-3 projects
[00:05:51] Overview of LangChain - a framework for building context-aware reasoning applications
[00:10:09] Components of LangChain - modules, chains, agents, etc.
[00:14:39] Underappreciated parts of LangChain - text splitters, retrieval algorithms like self-query
[00:18:46] Hiring at LangChain
[00:20:27] Designing the LangChain architecture - balancing flexibility and structure
[00:24:09] The difference between chains and agents in LangChain
[00:25:08] Prompt engineering and LangChain
[00:26:16] Announcing LangSmith
[00:30:50] Writing custom evaluators in LangSmith
[00:33:19] Reducing hallucinations - fixing retrieval vs generation issues
[00:38:17] The challenges of long context windows
[00:40:01] LangChain's multi-programming language strategy
[00:45:55] Most popular LangChain blog posts - deep dives into specific topics
[00:50:25] Responding to LangChain criticisms
[00:54:11] Harrison's advice to AI engineers
[00:55:43] Lightning Round
Transcript
Alessio: Hey everyone, welcome to the Latent Space Podcast. This is Alessio, partner and CTO at Residence at Decibel Partners, and I'm joined by my co-host Swyx, founder of Smol.ai. [00:00:19]
Swyx: Welcome. Today we have Harrison Chase in the studio with us. Welcome Harrison. [00:00:23]
Harrison: Thank you guys for having me. I'm excited to be here. [00:00:25]
Swyx: It's been a long time coming. We've been asking you for a little bit and we're really glad that you got some time to join us in the studio. Yeah. [00:00:32]
Harrison: I've been dodging you guys for a while. [00:00:34]
Swyx: About seven months. You pulled me in here. [00:00:37]
Alessio: About seven months. But it's all good. I totally understand. [00:00:38]
Swyx: We like to introduce people through the official backgrounds and then ask you a little bit about your personal side. So you went to Harvard, class of 2017. You don't list what you did in Harvard. Was it CS? [00:00:48]
Harrison: Stats and CS. [00:00:50]
Swyx: That's awesome. I love me some good stats. [00:00:52]
Harrison: I got into it through stats, through doing sports analytics. And then there was so much overlap between stats and CS that I found myself doing more and more of that. [00:00:59]
Swyx: And it's interesting that a lot of the math that you learn in stats actually comes over into machine learning which you applied at Kensho as a machine learning engineer and Robust Intelligence, which seems to be the home of a lot of AI founders.
Harrison: It does. Yeah.
Swyx: And you started LangChain, I think around November 2022 and incorporated in January. Yeah. [00:01:19]
Harrison: I was looking it up for the podcast and the first tweet was on, I think October 24th. So just before the end of November or end of October. [00:01:26]
Swyx: Yeah. So that's your LinkedIn. What should people know about you on the personal side that's not obvious on LinkedIn? [00:01:33]
Harrison: A lot of how I got into this is all through sports actually. Like I'm a big sports fan, played a lot of soccer growing up and then really big fan of the NBA and NFL. And so freshman year at college showed up and I knew I liked math. I knew I liked sports. One of the clubs that was there was the Sports Analytics Collective. And so I joined that freshman year, I was doing a lot of stuff in like Excel, just like basic stats, but then like wanted to do more advanced stuff. So learn to code, learn kind of like data science and machine learning through that way. Kind of like just kept on going down that path. I think sports is a great entryway to data science and machine learning. There's a lot of like numbers out there. People like really care. Like I remember, I think sophomore, junior year, I was in the Sports Collective and the main thing we had was a blog. And so we wrote a blog. It wasn't me. One of the other people in the club wrote a blog predicting the NFL season. I think they made some kind of like with stats and I think their stats showed that like the Dolphins would end up beating the Patriots and New England got like pissed about it, of course. So people like really care and they'll give you feedback about whether you're like models doing well or poorly. And so you get that. And then you also get like instantaneous kind of like, well, not instantaneous, but really quick feedback. Like if you predict a game, the game happens that night. Like you don't have to wait a year to see what happens. So I think sports is a great kind of like entryway for kind of like data science. [00:02:43]
Alessio: There was actually my first article on the Twilio blog with a Python script to like predict pricing of like Daily Fantasy players based on my past week performance. Yeah, I don't know. It's a good getaway drug. [00:02:56]
Swyx: And on my end, the way I got into finance was through sports betting. So maybe we all have some ties in there. Was like Moneyball a big inspiration? The movie? [00:03:06]
Harrison: Honestly, not really. I don't really like baseball. That's like the big thing. [00:03:10]
Swyx: Let's call it a lot of stats. Cool. Well, we can dive right into LangChain, which is what everyone is excited about. But feel free to make all the sports analogies you want. That really drives home a lot of points. What was your GPT aha moment? When did you start working on GPT itself? Maybe not LangChain, just anything to do with the GPT API? [00:03:29]
Harrison: I think it probably started around the time we had a company hackathon. I think that was before I launched LangChain. I'm trying to remember the exact sequence of events, but I do remember that at the hackathon I worked with Will, who's now actually at LangChain as well, and then two other members of Robust. And we made basically a bot where you could ask questions of Notion and Slack. And so I think, yeah, RAG, basically. And I think I wanted to try that out because I'd heard that it was getting good. I'm trying to remember if I did anything before that to realize that it was good. So then I would focus on that on the hackathon. I can't remember or not, but that was one of the first times that I built something [00:04:06]
Swyx: with GPT-3. There wasn't that much opportunity before because the API access wasn't that widespread. You had to get into some kind of program to get that. [00:04:16]
Harrison: DaVinci-002 was not terrible, but they did an upgrade to get it to there, and they didn't really publicize that as much. And so I think I remember playing around with it when the first DaVinci model came out. I was like, this is cool, but it's not amazing. You'd have to do a lot of work to get it to do something. But then I think that February or something, I think of 2022, they upgraded it and it was it got better, but I think they made less of an announcement around it. And so I just, yeah, it kind of slipped under the radar for me, at least. [00:04:45]
Alessio: And what was the step into LangChain? So you did the hackathon, and then as you were building the kind of RAG product, you felt like the developer experience wasn't that great? Or what was the inspiration? [00:04:54]
Harrison: No, honestly, so around that time, I knew I was going to leave my previous job. I was trying to figure out what I was going to do next. I went to a bunch of meetups and other events. This was like the September, August, September of that year. So after Stable Diffusion, but before ChatGPT. So there was interest in generative AI as a space, but not a lot of people hacking on language models yet. But there were definitely some. And so I would go to these meetups and just chat with people and basically saw some common abstractions in terms of what they were building, and then thought it would be a cool side project to factor out some of those common abstractions. And that became kind of like LangChain. I looked up again before this, because I remember I did a tweet thread on Twitter to announce LangChain. And we can talk about what LangChain is. It's a series of components. And then there's some end-to-end modules. And there was three end-to-end modules that were in the initial release. One was NatBot. So this was the web agent by Nat Friedman. Another was LLM Math Chain. So it would construct- [00:05:51]
Swyx: GPT-3 cannot do math. [00:05:53]
Harrison: Yeah, exactly. And then the third was Self-Ask. So some type of RAG search, similar to React style agent. So those were some of the patterns in terms of what I was seeing. And those all came from open source or academic examples, because the people who were actually working on this were building startups. And they were doing things like question answering over your databases, question answering over SQL, things like that. But I couldn't use their code as kind of like inspiration to factor things out. [00:06:18]
Swyx: I talked to you a little bit, actually, roundabout, right after you announced LangChain. I'm honored. I think I'm one of many. This is your first open source project. [00:06:26]
Harrison: No, that's not actually true. I released, because I like sports stats. And so I remember I did release some really small, random Python package for scraping data from basketball reference or something. I'm pretty sure I released that. So first project to get a star on GitHub, let's say that. [00:06:45]
Swyx: Did you reference anything? What was the inspirations, like other frameworks that you look to when open sourcing LangChain or announcing it or anything like that? [00:06:53]
Harrison: I mean, the only main thing that I looked for... I remember reading a Hacker News post a little bit before about how a readme on the project goes a long way. [00:07:02]
Swyx: Readme's help. [00:07:03]
Harrison: Yeah. And so I looked at it and was like, put some status checks at the top and have the title and then one or two lines and then just right into installation. And so that's the main thing that I looked at in terms of how to structure it. Because yeah, I hadn't done open source before. I didn't really know how to communicate that aspect of the marketing or getting people to use it. I think I had some trouble finding it, but I finally found it and used that as a lot [00:07:25]
Swyx: of the inspiration there. Yeah. It was one of the subjects of my write-up how it was surprising to me that significant open source experience actually didn't seem to matter in the new wave of AI tooling. Most like auto-GPTs, Torrents, that was his first open source project ever. And that became auto-GPT. Yeah. I don't know. To me, it's just interesting how open source experience is kind of fungible or not necessary. Or you can kind of learn it on the job. [00:07:49]
Alessio: Overvalued. [00:07:50]
Swyx: Overvalued. Okay. You said it, not me. [00:07:53]
Alessio: What's your description of LangChain today? I think when I built the LangChain Hub UI in January, there were a few things. And I think you were one of the first people to talk about agents that were already in there before it got hot now. And it's obviously evolved into a much bigger framework today. Run people through what LangChain is today, how they should think about it, and all of that. [00:08:14]
Harrison: The way that we describe it or think about it internally is that LangChain is basically... I started off saying LangChain's a framework for building LLM applications, but that's really vague and not really specific. And I think part of the issue is LangChain does do a lot, so it's hard to be somewhat specific. But I think the way that we think about it internally, in terms of prioritization, what to focus on, is basically LangChain's a framework for building context-aware reasoning applications. And so that's a bit of a mouthful, but I think that speaks to a lot of the core parts of what's in LangChain. And so what concretely that means in LangChain, there's really two things. One is a set of components and modules. And these would be the prompt template abstraction, the LLM abstraction, chat model abstraction, vector store abstraction, text splitters, document loaders. And so these are combinations of things that we build and we implement, or we just have integrations with. So we don't have any language models ourselves. We don't have any vector stores ourselves, but we integrate with a lot of them. And then the text splitters, we have our own logic for that. The document loaders, we have our own logic for that. And so those are the individual modules. But then I think another big part of LangChain, and probably the part that got people using it the most, is the end-to-end chains or applications. So we have a lot of chains for getting started with question answering over your documents, chat question answering, question answering over SQL databases, agent stuff that you can plug in off the box. And that basically combines these components in a series of specific ways to do this. So if you think about a question answering app, you need a lot of different components kind of stacked. And there's a bunch of different ways to do question answering apps. So this is a bit of an overgeneralization, but basically, you know, you have some component that looks up an embedding from a vector store, and then you put that into the prompt template with the question and the context, and maybe you have the chat history as well. And then that generates an answer, and then maybe you parse that out, or you do something with the answer there. And so there's just this sequence of things that you basically stack in a particular way. And so we just provide a bunch of those assembled chains off the shelf to make it really easy to get started in a few lines of code. [00:10:09]
Alessio: And just to give people context, when you first released LangChain, OpenAI did not have a chat API. It was a completion-only API. So you had to do all the human assistant, like prompting and whatnot. So you abstracted a lot of that away. I think the most interesting thing to me is you're kind of the Switzerland of this developer land. There's a bunch of vector databases that are killing each other out there to get people to embed data in them, and you're like, I love you all. You all are great. How do you think about being an opinionated framework versus leaving a lot of choice to the user? I mean, in terms of spending time into this integration, it's like you only have 10 people on the team. Obviously that takes time. Yeah. What's that process like for you all? [00:10:50]
Harrison: I think right off the bat, having different options for language models. I mean, language models is the main one that right off the bat we knew we wanted to support a bunch of different options for. There's a lot to discuss there. People want optionality between different language models. They want to try it out. They want to maybe change to ones that are cheaper as new ones kind of emerge. They don't want to get stuck into one particular one if a better one comes out. There's some challenges there as well. Prompts don't really transfer. And so there's a lot of nuance there. But from the bat, having this optionality between the language model providers was a big important part because I think that was just something we felt really strongly about. We believe there's not just going to be one model that rules them all. There's going to be a bunch of different models that are good for a bunch of different use cases. I did not anticipate the number of vector stores that would emerge. I don't know how many we supported in the initial release. It probably wasn't as big of a focus as language models was. But I think it kind of quickly became so, especially when Postgres and Elastic and Redis started building their vector store implementations. We saw that some people might not want to use a dedicated vector store. Maybe they want to use traditional databases. I think to your point around what we're opinionated about, I think the thing that we believe most strongly is it's super early in the space and super fast moving. And so there's a lot of uncertainty about how things will shake out in terms of what role will vector databases play? How many will there be? And so I think a lot of it has always kind of been this optionality and ability to switch and not getting locked in. [00:12:19]
Swyx: There's other pieces of LangChain which maybe don't get as much attention sometimes. And the way that you explained LangChain is somewhat different from the docs. I don't know how to square this. So for example, you have at the top level in your docs, you have, we mentioned ModelIO, we mentioned Retrieval, we mentioned Chains. Then you have a concept called Agents, which I don't know if exactly matches what other people call Agents. And we also talked about Memory. And then finally there's Callbacks. Are there any of the less understood concepts in LangChain that you want to give some air to? [00:12:53]
Harrison: I mean, I think buried in ModelIO is some stuff around like few-shot example selectors that I think is really powerful. That's a workhorse. [00:13:01]
Swyx: Yeah. I think that's where I start with LangChain. [00:13:04]
Harrison: It's one of those things that you probably don't, if you're building an application, you probably don't start with it. You probably start with like a zero-shot prompt. But I think that's a really powerful one that's probably just talked about less because you don't need it right off the bat. And for those of you who don't know, that basically selects from a bunch of examples the ones that are maybe most relevant to the input at hand. So you can do some nice kind of like in-context learning there. I think that's, we've had that for a while. I don't think enough people use that, basically. Output parsers also used to be kind of important, but then function calling. There's this interesting thing where like the space is just like progressing so rapidly that a lot of things that were really important have kind of diminished a bit, to be honest. Output parsers definitely used to be an understated and underappreciated part. And I think if you're working with non-OpenAI models, they still are, but a lot of people are working with OpenAI models. But even within there, there's different things you can do with kind of like the function calling ability. Sometimes you want to have the option of having the text or the application you're building, it could return either. Sometimes you know that it wants to return in a structured format, and so you just want to take that structured format. Other times you're extracting things that are maybe a key in that structured format, and so you want to like pluck that key. And so there's just like some like annoying kind of like parsing of that to do. Agents, memory, and retrieval, we haven't talked at all. Retrieval, there's like five different subcomponents. You could also probably talk about all of those in depth. You've got the document loaders, the text splitters, the embedding models, the vector stores. Embedding models and vector stores, we don't really have, or sorry, we don't build, we integrate with those. Text splitters, I think we have like 15 or so. Like I think there's an under kind of like appreciated amount of those. [00:14:39]
Swyx: And then... Well, it's actually, honestly, it's overwhelming. Nobody knows what to choose. [00:14:43]
Harrison: Yeah, there is a lot. [00:14:44]
Swyx: Yeah. Do you have personal favorites that you want to shout out? [00:14:47]
Harrison: The one that we have in the docs is the default is like the recursive text splitter. We added a playground for text splitters the other week because, yeah, we heard a lot that like, you know, and like these affect things like the chunk overlap and the chunks, they affect things in really subtle ways. And so like I think we added a playground where people could just like choose different options. We have like, and a lot of the ideas are really similar. You split on different characters, depending on kind of like the type of text that you have marked down, you might want to split on differently than HTML. And so we added a playground where you can kind of like choose between those. I don't know if those are like underappreciated though, because I think a lot of people talk about text splitting as being a hard part, and it is a really important part of creating these retrieval applications. But I think we have a lot of really cool retrieval algorithms as well. So like self query is maybe one of my favorite things in LangChain, which is basically this idea of when you have a user question, the typical kind of like thing to do is you embed that question and then find the document that's most similar to that question. But oftentimes questions have things that just, you don't really want to look up semantically, they have some other meaning. So like in the example that I use, the example in the docs is like movies about aliens in the year 1980. 1980, I guess there's some semantic meaning for that, but it's a very particular thing that you care about. And so what the self query retriever does is it splits out the metadata filter and most vector stores support like a metadata filter. So it splits out this metadata filter, and then it splits out the semantic bit. And that's actually like kind of tricky to do because there's a lot of different filters that you can have like greater than, less than, equal to, you can have and things if you have multiple filters. So we have like a pretty complicated like prompt that does all that. That might be one of my favorite things in LangChain, period. Like I think that's, yeah, I think that's really cool. [00:16:26]
Alessio: How do you think about speed of development versus support of existing things? So we mentioned retrieval, like you got, or, you know, text splitting, you got like different options for all of them. As you get building LangChain, how do you decide which ones are not going to keep supporting, you know, which ones are going to leave behind? I think right now, as you said, the space moves so quickly that like you don't even know who's using what. What's that like for you? [00:16:50]
Harrison: Yeah. I mean, we have, you know, we don't really have telemetry on what people are using in terms of what parts of LangChain, the telemetry we have is like, you know, anecdotal stuff when people ask or have issues with things. A lot of it also is like, I think we definitely prioritize kind of like keeping up with the stuff that comes out. I think we added function calling, like the day it came out or the day after it came out, we added chat model support, like the day after it came out or something like that. That's probably, I think I'm really proud of how the team has kind of like kept up with that because this space is like exhausting sometimes. And so that's probably, that's a big focus of ours. The support, I think we've like, to be honest, we've had to get kind of creative with how we do that. Cause we have like, I think, I don't know how many open issues we have, but we have like 3000, somewhere between 2000 and 3000, like open GitHub issues. We've experimented with a lot of startups that are doing kind of like question answering over your docs and stuff like that. And so we've got them on the website and in the discord and there's a really good one, dosu on the GitHub that's like answering issues and stuff like that. And that's actually something we want to start leaning into more heavily as a company as well as kind of like building out an AI dev rel because we're 10 people now, 10, 11 people now. And like two months ago we were like six or something like that. Right. So like, and to have like 2,500 open issues or something like that, and like 300 or 400 PRs as well. Cause like one of the amazing things is that like, and you kind of alluded to this earlier, everyone's building in the space. There's so many different like touch points. LangChain is lucky enough to kind of like be a lot of the glue that connects it. And so we get to work with a lot of awesome companies, but that's also a lot of like work to keep up with as well. And so I don't really have an amazing answer, but I think like the, I think prioritize kind of like new things that, that come out. And then we've gotten creative with some of kind of like the support functions and, and luckily there's, you know, there's a lot of awesome people working on all those support coding, question answering things that we've been able to work with. [00:18:46]
Swyx: I think there is your daily rhythm, which I've seen you, you work like a, like a beast man, like mad impressive. And then there's sometimes where you step back and do a little bit of high level, like 50,000 foot stuff. So we mentioned, we mentioned retrieval. You did a refactor in March and there's, there's other abstractions that you've sort of changed your mind on. When do you do that? When do you do like the, the step back from the day to day and go, where are we going and change the direction of the ship? [00:19:11]
Harrison: It's a good question so far. It's probably been, you know, we see three or four or five things pop up that are enough to make us think about it. And then kind of like when it reaches that level, you know, we don't have like a monthly meeting where we sit down and do like a monthly plan or something. [00:19:27]
Swyx: Maybe we should. I've thought about this. Yeah. I'd love to host that meeting. [00:19:32]
Harrison: It's really been a lot of, you know, one of the amazing things is we get to interact with so many different people. So it's been a lot of kind of like just pattern matching on what people are doing and trying to see those patterns before they punch us in the face or something like that. So for retrieval, it was the pattern of seeing like, Hey, yeah, like a lot of people are using vector sort of stuff. But there's also just like other methods and people are offering like hosted solutions and we want our abstractions to work with that as well. So we shouldn't bake in this paradigm of doing like semantic search too heavily, which sounds like basic now, but I think like, you know, to start a lot of it was people needed help doing these things. But then there was like managed things that did them, hybrid retrieval mechanisms, all of that. I think another example of this, I mean, Langsmith, which we can maybe talk about was like very kind of like, I think we worked on that for like three or four months before announcing it kind of like publicly, two months maybe before giving it to kind of like anyone in beta. But this was a lot of debugging these applications as a pain point. We hear that like just understanding what's going on is a pain point. [00:20:27]
Alessio: I mean, you two did a webinar on this, which is called Agents vs. Chains. It was fun, baby. [00:20:32]
Swyx: Thanks for having me on. [00:20:33]
Harrison: No, thanks for coming. [00:20:34]
Alessio: That was a good one. And on the website, you list like RAG, which is retrieval of bank debt generation and agents as two of the main goals of LangChain. The difference I think at the Databricks keynote, you said chains are like predetermined steps and agents is models reasoning to figure out what steps to take and what actions to take. How should people think about when to use the two and how do you transition from one to the other with LangChain? Like is it a path that you support or like do people usually re-implement from an agent to a chain or vice versa? [00:21:05]
Swyx: Yeah. [00:21:06]
Harrison: You know, I know agent is probably an overloaded term at this point, and so there's probably a lot of different definitions out there. But yeah, as you said, kind of like the way that I think about an agent is basically like in a chain, you have a sequence of steps. You do this and then you do this and then you do this and then you do this. And with an agent, there's some aspect of it where the LLM is kind of like deciding what to do and what steps to do in what order. And you know, there's probably some like gray area in the middle, but you know, don't fight me on this. And so if we think about those, like the benefits of the chains are that they're like, you can say do this and you just have like a more rigid kind of like order and the way that things are done. They have more control and they don't go off the rails and basically everything that's bad about agents in terms of being uncontrollable and expensive, you can control more finely. The benefit of agents is that I think they handle like the long tail of things that can happen really well. And so for an example of this, let's maybe think about like interacting with a SQL database. So you can have like a SQL chain and you know, the first kind of like naive approach at a SQL chain would be like, okay, you have the user question. And then you like write the SQL query, you do some rag, you pull in the relevant tables and schemas, you write a SQL query, you execute that against the SQL database. And then you like return that as the answer, or you like summarize that with an LLM and return that to the answer. And that's basically the SQL chain that we have in LangChain. But there's a lot of things that can go wrong in that process. Starting from the beginning, you may like not want to even query the SQL database at all. Maybe they're saying like, hi, or something, or they're misusing the application. Then like what happens if you have some step, like a big part of the application that people with LangChain is like the context aware part. So there's generally some part of bringing in context to the language model. So if you bring in the wrong context to the language model, so it doesn't know which tables to query, what do you do then? If you write a SQL query, it's like syntactically wrong and it can't run. And then if it can run, like what if it returns an unexpected result or something? And so basically what we do with the SQL agent is we give it access to all these different tools. So it has another tool, it can run the SQL query as another, and then it can respond to the user. But then if it kind of like, it can decide which order to do these. And so it gives it flexibility to handle all these edge cases. And there's like, obviously downsides to that as well. And so there's probably like some safeguards you want to put in place around agents in terms of like not letting them run forever, having some observability in there. But I do think there's this benefit of, you know, like, again, to the other part of what LangChain is like the reasoning part, like each of those steps individually involves some aspect of reasoning, for sure. Like you need to reason about what the SQL query is, you need to reason about what to return. But there's then there's also reasoning about the order of operations. And so I think to me, the key is kind of like giving it an appropriate amount to reason about while still keeping it within checks. And so to the point, like, I would probably recommend that most people get started with chains and then when they get to the point where they're hitting these edge cases, then they think about, okay, I'm hitting a bunch of edge cases where the SQL query is just not returning like the relevant things. Maybe I should add in some step there and let it maybe make multiple queries or something like that. Basically, like start with chain, figure out when you're hitting these edge cases, add in the reasoning step to that to handle those edge cases appropriately. That would be kind of like my recommendation, right? [00:24:09]
Swyx: If I were to rephrase it, in my words, an agent would be a reasoning node in a chain, right? Like you start with a chain, then you just add a reasoning node, now it's an agent. [00:24:17]
Harrison: Yeah, the architecture for your application doesn't have to be just a chain or just an agent. It can be an agent that calls chains, it can be a chain that has an agent in different parts of them. And this is another part as well. Like the chains in LangChain are largely intended as kind of like a way to get started and take you some amount of the way. But for your specific use case, in order to kind of like eke out the most performance, you're probably going to want to do some customization at the very basic level, like probably around the prompt or something like that. And so one of the things that we've focused on recently is like making it easier to customize these bits of existing architectures. But you probably also want to customize your architectures as well. [00:24:52]
Swyx: You mentioned a bit of prompt engineering for self-ask and then for this stuff. There's a bunch of, I just talked to a prompt engineering company today, PromptOps or LLMOps. Do you have any advice or thoughts on that field in general? Like are you going to compete with them? Do you have internal tooling that you've built? [00:25:08]
Harrison: A lot of what we do is like where we see kind of like a lot of the pain points being like we can talk about LangSmith and that was a big motivation for that. And like, I don't know, would you categorize LangSmith as PromptOps? [00:25:18]
Swyx: I don't know. It's whatever you want it to be. Do you want to call it? [00:25:22]
Harrison: I don't know either. Like I think like there's... [00:25:24]
Swyx: I think about it as like a prompt registry and you store them and you A-B test them and you do that. LangSmith, I feel like doesn't quite go there yet. Yeah. It's obviously the next step. [00:25:34]
Harrison: Yeah, we'll probably go. And yeah, we'll do more of that because I think that's definitely part of the application of a chain or agent is you start with a default one, then you improve it over time. And like, I think a lot of the main new thing that we're dealing with here is like language models. And the main new way to control language models is prompts. And so like a lot of the chains and agents are powered by this combination of like prompt language model and then some output parser or something doing something with the output. And so like, yeah, we want to make that core thing as good as possible. And so we'll do stuff all around that for sure. [00:26:05]
Swyx: Awesome. We might as well go into LangSmith because we're bringing it up so much. So you announced LangSmith I think last month. What are your visions for it? Is this the future of LangChain and the company? [00:26:16]
Harrison: It's definitely part of the future. So LangSmith is basically a control center for kind of like your LLM application. So the main features that it kind of has is like debugging, logging, monitoring, and then like testing and evaluation. And so debugging, logging, monitoring, basically you set three environment variables and it kind of like logs all the runs that are happening in your LangChain chains or agents. And it logs kind of like the inputs and outputs at each step. And so the main use case we see for this is in debugging. And that's probably the main reason that we started down this path of building it is I think like as you have these more complex things, debugging what's actually going on becomes really painful whether you're using LangChain or not. And so like adding this type of observability and debuggability was really important. Yeah. There's a debugging aspect. You can see the inputs, outputs at each step. You can then quickly enter into like a playground experience where you can fiddle around with it. The first version didn't have that playground and then we'd see people copy, go to open AI playground, paste in there. Okay. Well, that's a little annoying. And then there's kind of like the monitoring, logging experience. And we recently added some analytics on like, you know, how many requests are you getting per hour, minute, day? What's the feedback like over time? And then there's like a testing debugging, sorry, testing and evaluation component as well where basically you can create datasets and then test and evaluate these datasets. And I think importantly, all these things are tied to each other and then also into LangChain, the framework. So what I mean by that is like we've tried to make it as easy as possible to go from logs to adding a data point to a dataset. And because we think a really powerful flow is you don't really get started with a dataset. You can accumulate a dataset over time. And so being able to find points that have gotten like a thumbs up or a thumbs down from a user can be really powerful in terms of creating a good dataset. And so that's maybe like a connection between the two. And then the connection in the other way is like all the runs that you have when you test or evaluate something, they're logged in the same way. So you can debug what exactly is going on and you don't just have like a final score. You have like this nice trace and thing where you can jump in. And then we also want to do more things to hook this into a LangChain proper, the framework. So I think like some of like the managing the prompts will tie in here already. Like we talked about example selectors using datasets as a few short examples is a path that we support in a somewhat janky way right now, but we're going to like make better over time. And so there's this connection between everything. Yeah. [00:28:42]
Alessio: And you mentioned the dataset in the announcement blog post, you touched on heuristic evaluation versus LLMs evaluating LLMs. I think there's a lot of talk and confusion about this online. How should people prioritize the two, especially when they might start with like not a good set of evals or like any data at all? [00:29:01]
Harrison: I think it's really use case specific in the distinction that I draw between heuristic and LLM. LLMs, you're using an LLM to evaluate the output heuristics, you have some common heuristic that you can use. And so some of these can be like really simple. So we were doing some kind of like measuring of an extraction chain where we wanted it to output JSON. Okay. One evaluation can be, can you use JSON.loads to load it? And like, right. And that works perfectly. You don't need an LLM to do that. But then for like a lot of like the question answering, like, is this factually accurate? And you have some ground truth fact that you know it should be answering with. I think, you know, LLMs aren't perfect. And I think there's a lot of discussion around the pitfalls of using LLMs to evaluate themselves. And I'm not saying they're perfect by any means, but I do think they're, we've found them to be kind of like better than blue or any of those metrics. And the way that I also like to use those is also just like guide my eye about where to look. So like, you know, I might not trust the score of like 0.82, like exactly correct, but like I can look to see like which data points are like flagged as passing or failing. And sometimes the evaluators messing up, but it's like good to like, you know, I don't have to look at like a hundred data points. I can focus on like 10 or something like that. [00:30:10]
Alessio: And then can you create a heuristic once in Langsmith? Like what's like your connection to that? [00:30:16]
Harrison: Yeah. So right now, all the evaluation, we actually do client side. And part of this is basically due to the fact that a lot of the evaluation is really application specific. So we thought about having evaluators, you could just click off and run in a server side or something like that. But we still think it's really early on in evaluation. We still think there's, it's just really application specific. So we prioritized instead, making it easy for people to write custom evaluators and then run them client side and then upload the results so that they can manually inspect them because I think manual inspection is still a pretty big part of evaluation for better or worse. [00:30:50]
Swyx: We have this sort of components of observability. We have cost, latency, accuracy, and then planning. Is that listed in there? [00:30:57]
Alessio: Well, planning more in the terms of like, if you're an agent, how to pick the right tool and whether or not you are picking the right tool. [00:31:02]
Swyx: So when you talk to customers, how would you stack rank those needs? Are they cost sensitive? Are they latency sensitive? I imagine accuracy is pretty high up there. [00:31:13]
Harrison: I think accuracy is definitely the top that we're seeing right now. I think a lot of the applications, people are, especially the ones that we're working with, people are still struggling to get them to work at a level where they're reliable [00:31:24]
Swyx: enough. [00:31:25]
Harrison: So that's definitely the first. Then I think probably cost becomes the next one. I think a few places where we've started to see this be like one of the main things is the AI simulation that came out. [00:31:36]
Swyx: Generative agents. Yeah, exactly. [00:31:38]
Harrison: Which is really fun to run, but it costs a lot of money. And so one of our team members, Lance, did an awesome job hooking up like a local model to it. You know, it's not as perfect, but I think it helps with that. Another really big place for this, we believe, is in like extraction of structured data from unstructured data. And the reason that I think it's so important there is that usually you do extraction of some type of like pre-processing or indexing process over your documents. I mean, there's a bunch of different use cases, but one use case is for that. And generally that's over a lot of documents. And so that starts to rack up a bill kind of quickly. And I think extraction is also like a simpler task than like reasoning about which tools to call next in an agent. And so I think it's better suited for that. Yeah. [00:32:15]
Swyx: On one of the heuristics I wanted to get your thoughts on, hallucination is one of the big problems there. Do you have any recommendations on how people should reduce hallucinations? [00:32:25]
Harrison: To reduce hallucinations, we did a webinar on like evaluating RAG this past week. And I think there's this great project called RAGOS that evaluates four different things across two different spectrums. So the two different spectrums are like, is the retrieval part right? Or is the generation, or sorry, like, is it messing up in retrieval or is it messing up in generation? And so I think to fix hallucination, it probably depends on where it's messing up. If it's messing up in generation, then you're getting the right information, but it's still hallucinating. Or you're getting like partially right information and hallucinating some bits, a lot of that's prompt engineering. And so that's what we would recommend kind of like focusing on the prompt engineering part. And then if you're getting it wrong in the, if you're just not retrieving the right stuff, then there's a lot of different things that you can probably do, or you should look at on the retrieval bit. And honestly, that's where it starts to become a bit like application specific as well. Maybe there's some temporal stuff going on. Maybe you're not parsing things correctly. Yeah. [00:33:19]
Swyx: Okay. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. [00:33:35]
Harrison: Yeah. Yeah. [00:33:37]
Swyx: Yeah. [00:33:38]
Harrison: Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. [00:33:56]
Swyx: Yeah. Yeah. [00:33:58]
Harrison: Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. [00:34:04]
Swyx: Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. [00:34:17]
Harrison: Yeah. Yeah. Yeah. Yeah. Yeah. Yeah, I mean, there's probably a larger discussion around that, but openAI definitely had a huge headstart, right? And that's... Clawds not even publicly available yet, I don't think. [00:34:28]
Swyx: The API? Yeah. Oh, well, you can just basically ask any of the business reps and they'll give it to you. [00:34:33]
Harrison: You can. But it's still a different signup process. I think there's... I'm bullish that other ones will catch up especially like Anthropic and Google. The local ones are really interesting. I think we're seeing a big... [00:34:46]
Swyx: Lama Two? Yeah, we're doing the fine-tuning hackathon tomorrow. Thanks for promoting that. [00:34:50]
Harrison: No, thanks for it. I'm really excited about that stuff. I mean, that's something that like we've been, you know, because like, as I said, like the only thing we know is that the space is moving so fast and changing so rapidly. And like, local models are, have always been one of those things that people have been bullish on. And it seems like it's getting closer and closer to kind of like being viable. So I'm excited to see what we can do with some fine-tuning. [00:35:10]
Swyx: Yeah. I have to confess, I did not know that you cared. It's not like a judgment on Langchain. I was just like, you know, you write an adapter for it and you're done, right? Like how much further does it go for Langchain? In terms of like, for you, it's one of the, you know, the model IO modules and that's it. But like, you seem very personally, very passionate about it, but I don't know what the Langchain specific angle for this is, for fine-tuning local models, basically. Like you're just passionate about local models and privacy and all that, right? And open source. [00:35:41]
Harrison: Well, I think there's a few different things. Like one, like, you know, if we think about what it takes to build a really reliable, like context-aware reasoning application, there's probably a bunch of different nodes that are doing a bunch of different things. And I think it is like a really complex system. And so if you're relying on open AI for every part of that, like, I think that starts to get really expensive. Also like, probably just like not good to have that much reliability on any one thing. And so I do think that like, I'm hoping that for like, you know, specific parts at the end, you can like fine-tune a model and kind of have a more specific thing for a specific task. Also, to be clear, like, I think like, I also, at the same time, I think open AI is by far the easiest way to get started. And if I was building anything, I would absolutely start with open AI. So. [00:36:27]
Swyx: It's something I think a lot of people are wrestling with. But like, as a person building apps, why take five vendors when I can take one vendor, right? Like, as long as I trust Azure, I'm just entrusting all my data to Azure and that's it. So I'm still trying to figure out the real case for local models in production. And I don't know, but fine-tuning, I think, is a good one. That's why I guess open AI worked on fine-tuning. [00:36:49]
Harrison: I think there's also like, you know, like if there is, if there's just more options available, like prices are going to go down. So I'm happy about that. So like very selfishly, there's that aspect as well. [00:37:01]
Alessio: And in the Lancsmith announcement, I saw in the product screenshot, you have like chain, tool and LLM as like the three core atoms. Is that how people should think about observability in this space? Like first you go through the chain and then you start dig down between like the model itself and like the tool it's using? [00:37:19]
Harrison: We've added more. We've added like a retriever logging so that you can see like what query is going in and what are the documents you're getting out. Those are like the three that we started with. I definitely think probably the main ones, like basically the LLM. So the reason I think the debugging in Lancsmith and debugging in general is so needed for these LLM apps is that if you're building, like, again, let's think about like what we want people to build in with LangChain. These like context aware reasoning applications. Context aware. There's a lot of stuff in the prompt. There's like the instructions. There's any previous messages. There's any input this time. There's any documents you retrieve. And so there's a lot of like data engineering that goes into like putting it into that prompt. This sounds silly, but just like making sure the data shows up in the right format is like really important. And then for the reasoning part of it, like that's obviously also all in the prompt. And so being able to like, and there's like, you know, the state of the world right now, like if you have the instructions at the beginning or at the end can actually make like a big difference in terms of whether it forgets it or not. And so being able to kind of like. [00:38:17]
Swyx: Yeah. And it takes on that one, by the way, this is the U curve in context, right? Yeah. [00:38:21]
Harrison: I think it's real. Basically I've found long context windows really good for when I want to extract like a single piece of information about something basically. But if I want to do reasoning over perhaps multiple pieces of information that are somewhere in like the retrieved documents, I found it not to be that great. [00:38:36]
Swyx: Yeah. I have said that that piece of research is the best bull case for Lang chain and all the vector companies, because it means you should do chains. It means you should do retrieval instead of long context, right? People are trying to extend long context to like 100K, 1 million tokens, 5 million tokens. It doesn't matter. You're going to forget. You can't trust it. [00:38:54]
Harrison: I expect that it will probably get better over time as everything in this field. But I do also think there'll always be a need for kind of like vector stores and retrieval in some fashions. [00:39:03]
Alessio: How should people get started with Langsmith Cookbooks? Wanna talk maybe a bit about that? [00:39:08]
Swyx: Yeah. [00:39:08]
Harrison: Again, like I think the main thing that even I find valuable about Langsmith is just like the debugging aspect of it. And so for that, it's very simple. You can kind of like turn on three environment variables and it just logs everything. And you don't look at it 95% of the time, but that 5% you do when something goes wrong, it's quite handy to have there. And so that's probably the easiest way to get started. And we're still in a closed beta, but we're letting people off the wait list every day. And if you really need access, just DM me and we're happy to give you access there. And then yeah, there's a lot that you can do with Langsmith that we've been talking about. And so Will on our team has been leading the charge on a really great like Langsmith Cookbooks repo that covers everything from collecting feedback, whether it's thumbs up, thumbs down, or like multi-scale or comments as well, to doing evaluation, doing testing. You can also use Langsmith without Langchain. And so we've got some notebooks on that in there. But we have Python and JavaScript SDKs that aren't dependent on Langchain in any way. [00:40:01]
Swyx: And so you can use those. [00:40:01]
Harrison: And then we'll also be publishing a notebook on how to do that just with the REST APIs themselves. So yeah, definitely check out that repo. That's a great resource that Will's put together. [00:40:10]
Swyx: Yeah, awesome. So we'll zoom out a little bit from Langsmith and talk about Langchain, the company. You're also a first-time founder. Yes. And you've just hired your 10th employee, Julia, who I know from my data engineering days. You mentioned Will Nuno, I think, who maintains Langchain.js. I'm very interested in like your multi-language strategy, by the way. Ankush, your co-founder, Lance, who did AutoEval. What are you staffing up for? And maybe who are you hiring? [00:40:34]
Harrison: Yeah, so 10 employees, 12 total. We've got three more joining over the next three weeks. We've got Julia, who's awesome leading a lot of the product, go-to-market, customer success stuff. And then we've got Bri, who's also awesome leading a lot of the marketing and ops aspects. And then other than that, all engineers. We've staffed up a lot on kind of like full stack infra DevOps, kind of like as we've started going into the hosted platform. So internally, we're split about 50-50 between the open source and then the platform stuff. And yeah, we're looking to hire particularly on kind of like the things, we're actually looking to hire across most fronts, to be honest. But in particular, we probably need one or two more people on like open source, both Python and JavaScript and happy to dive into the multi-language kind of like strategy there. But again, like strong focus there on engineering, actually, as opposed to maybe like, we're not a research lab, we're not a research shop. [00:41:48]
Swyx: And then on the platform side, [00:41:49]
Harrison: like we definitely need some more people on the infra and DevOps side. So I'm using this as an opportunity to tell people that we're hiring and that you should reach out if that sounds like you. [00:41:58]
Swyx: Something like that, jobs, whatever. I don't actually know if we have an official job. [00:42:02]
Harrison: RIP, what happened to your landing page? [00:42:04]
Swyx: It used to be so based. The Berkshire Hathaway one? Yeah, so what was the story, the quick story behind that? Yeah, the quick story behind that is we needed a website [00:42:12]
Harrison: and I'm terrible at design. [00:42:14]
Swyx: And I knew that we couldn't do a good job. [00:42:15]
Harrison: So if you can't do a good job, might as well do the worst job possible. Yeah, and like lean into it. And have some fun with it, yeah. [00:42:21]
Swyx: Do you admire Warren Buffett? Yeah, I admire Warren Buffett and admire his website. And actually you can still find a link to it [00:42:26]
Harrison: from our current website if you look hard enough. So there's a little Easter egg. Before we dive into more of the open source community things, [00:42:33]
Alessio: let's dive into the language thing. How do you think about parity between the Python and JavaScript? Obviously, they're very different ecosystems. So when you're working on a LangChain, is it we need to have the same abstraction in both language or are you to the needs? The core stuff, we want to have the same abstractions [00:42:50]
Harrison: because we basically want to be able to do serialize prompts, chains, agents, all the core stuff as tightly as possible and then use that between languages. Like even, yeah, like even right now when we log things to LangChain, we have a playground experience where you can run things that runs in JavaScript because it's kind of like in the browser. But a lot of what's logged is like Python. And so we need that core equivalence for a lot of the core things. Then there's like the incredibly long tail of like integrations, more researchy things. So we want to be able to do that. Python's probably ahead on a lot of like the integrations front. There's more researchy things that we're able to include quickly because a lot of people release some of their code in Python and stuff like that. And so we can use that. And there's just more of an ecosystem around the Python project. But the core stuff will have kind of like the same abstractions and be translatable. That didn't go exactly where I was thinking. So like the LangChain of Ruby, the LangChain of C-sharp, [00:43:44]
Swyx: you know, there's demand for that. I mean, I think that's a big part of it. But you are giving up some real estate by not doing it. Yeah, it comes down to kind of like, you know, ROI and focus. And I think like we do think [00:43:58]
Harrison: there's a strong JavaScript community and we wanted to lean into that. And I think a lot of the people that we brought on early, like Nuno and Jacob have a lot of experience building JavaScript tooling in that community. And so I think that's a big part of it. And then there's also like, you know, building JavaScript tooling in that community. Will we do another language? Never say never, but like... [00:44:21]
Swyx: Python JS for now. Yeah. Awesome. [00:44:23]
Alessio: You got 83 articles, which I think might be a record for such a young company. What are like the hottest hits, the most popular ones? [00:44:32]
Harrison: I think the most popular ones are generally the ones where we do a deep dive on something. So we did something a few weeks ago around evaluating CSV question answering applications, which I think is a really interesting one because most question answering, like everyone does question answering, but it's generally over unstructured data over your documents and you do the whole rag thing. And that doesn't work amazing for structured data. And so this was something that we heard, the origin of this was basically we heard from the community, you guys should improve this. And so we're like, okay, let's improve it. And then we're like, okay, well, in order to see if we improve it, we need to like evaluate it and see how we're doing. And so we kind of like wrote up a lot of our thought process there. And I think, and a lot of people like reached out about that and thought that was interesting and we're going through similar challenges and had, we posted another one a few days after that someone wrote basically as a response, which is awesome because it had a completely different strategy. And it was a really, it was a really, that was a really good piece as well. So that was like a deep dive on something like evaluation bit. I think like we did one on retrieval a while back, which was basically like, hey, we, and this was around when we changed our abstractions, like, hey, we changed our abstractions to this. This is why we did it. This is what we see coming down the pipeline. These are like the different types of retrieval that we see. I think a lot of people read and liked that one. A lot of the blogs that we do are also highlighting cool partnerships or cool applications. But in terms of, if you go by like number of views, I think the ones that get the most views are the more like deep dive ones. [00:45:55]
Swyx: Yeah. And I also noticed that you do guest posts as well. [00:45:58]
Harrison: Actually, you know, which one, and this is a guest post that got a lot of views, the multi-on one, the multi-on agent one. When we did, we did a blog where we integrated with them and that got a ton of views. [00:46:06]
Swyx: What do you think that is? [00:46:07]
Harrison: I think it's, I mean, it's one of like the few agents that's actually available and like out in the world. [00:46:15]
Swyx: They're still behind a wait list. Still behind a wait list, [00:46:17]
Harrison: but they're very active on social media. I don't know if I'm off the wait list. [00:46:21]
Swyx: I mean, you're on their blogs. They're on your blog, so I hope they give you access at some point. But that's interesting. A lot of interest in agents. I think they just opened up an API as well. Yeah, exactly. [00:46:32]
Harrison: That was the blog that we did. I was, yeah, I was a bit surprised to see that as well, but I think there's generally a lot of interest in agents and it's also really hard to get them to work. And I think multi-on is one of the first that has that. [00:46:45]
Swyx: Yeah. So my angle to this is a lot of people want to work with you. Yes. You're bombarded. I'm sure your email is just unmanageable. How should people be good partners with you? Like I work at a company and I'm like, hey, I'd love to do something on the LangChain blog or integrate to LangChain. I know Harrison's a busy guy. Like, what do I do? [00:47:03]
Harrison: Like the stuff that gets my attention honestly is like the in-depth, really thought out stuff. Obviously I love this stuff. Like this stuff is awesome. And there's so many different, there's so much to do as well. And like the biggest thing that we have trouble with internally is like figuring out what to do. [00:47:17]
Swyx: What's noise and what's signal. [00:47:19]
Harrison: Not even that, but just like what to focus on. Like there's so many different directions we could do and we want to go in like so many because there's so many interesting things, but we can't do. So if anyone kind of like takes the time to like go deep in a particular area, I love talking to them and I love reading what they write. And I love sharing what they write on the blog. Like that to me is awesome. So I think like... [00:47:37]
Swyx: Do good stuff. Be so good they can't ignore you. It sounds basic, right? [00:47:40]
Harrison: So that's why I didn't want to say it. [00:47:42]
Swyx: No, it's great. [00:47:42]
Harrison: But I think like these deep dots, yeah, there's just so much to do and these don't do shallow stuff, I guess would be. [00:47:48]
Swyx: I think that's a good call that people need reminding. [00:47:50]
Alessio: What about the other side of open source? So on Acker News, there were a couple blog posts recently, like the problem with LangChain and LangChain is pointless, all these different things. So the TLDR of some of them were, the LangChain API is like kind of verbose and complicated versus like sometimes I can just do this in like 10 lines of code. How do you balance that in terms of allowing for the complex use cases versus making maybe the ergonomics like simpler, but then trading that off later? [00:48:21]
Harrison: There's a lot to balance and there's a lot to do. And I think like posts like that are very valuable to hear basically what people are saying. And like, we have a lot of open issues. So it's not like these things hadn't been said before, but I think like that was a good emphasis on what people are saying. And I think there was a lot of things in there. I think part of it's kind of like around and we took all of it very seriously. And yeah, I think there's a lot to dive into there. There's like the documentation piece. And so I think we did a revamp of the documentation to address that. There's also like a comment in this, I think this was around, I think the top comment on the LangChain is pointless one was like basically like orchestration is like 5% of the work. And then like the other 95% is like prompt engineering and like data engineering. And those are the hard bits. I think maybe orchestration is a little bit more than 5%, but I like agree that those are like really big pain points that get exacerbated when you have these complex chains and agents where you can't really see what's going on inside of them. And I think that's partially why we built Langsmith to help out with exactly that. We also needed to do better things like make the prompts more visible and make it allow for more customizability around that. And so we've tried to add some stuff there. In terms of balancing, there's also LangChain is pointless. I don't need a wrapper. I can just call the underlying API. I think if all you're trying to do is call the underlying API, then like, yeah, that's gonna be the cleanest and simplest thing to do. And we try to get as close to that experience as possible, but we're not optimizing for calling the API. We're optimizing for helping people build context-aware reasoning applications as easily as possible. And so there's some level of abstractions that you need to add in order to assist in that. Yeah, that's definitely a balance that's tricky to strike, but I think there's also some aspect of it. Like, I do think one of the big benefits that LangChain provides is a standard interface for language models so that you can switch between them. And this kind of gets into like an ORM debate, like are ORMs generally kind of like useful or not? And so I think in this case they are. I think there's probably a larger kind of like philosophical kind of like question about that [00:50:25]
Swyx: that people have strong opinions on. Just the prompts don't transfer like you also mentioned. Yeah, yeah, there's that, yeah. [00:50:32]
Harrison: And then between kind of like allowing for, I think one helpful thing that we did in terms of like distinguishing between basically the base interfaces and then more complex stuff is part of the separation around the docs is there's like the components piece, which has the model IO, the retrieval, the agents, the callbacks, things like that. And then there's all the use cases. And so I think like the use cases, because they are like these assembly of all these things in a particular order, they start to get more complex. And it's, you know, we try our best to kind of like make clear how you can configure things. But yeah, there's a lot of different options that you might want to configure. And so I think that split has kind of helped us internally at least. And I think externally as well, because we've heard good comments about the improved documentation. I think that's made it a little bit more clear. And then another thing, one of the things that we also released soon after, and we'd been thinking about a little bit is basically like a LangChain expression language, which allows for actual composability of pieces. So LangChain, I think, has always been very good about interchangeability. Let's ignore the prompting issues, but like you could always plug in like one LLM for another one. You could swap in one vector for another one, but the chains themselves haven't actually been super actually composable. Like we had the sequential chain, but that was a bit like clunky to use. And then we had a router chain, but that was a bit, you know, that was also a bit clunky to use. And so one of the things, and so there's a million different things to do, and we didn't prioritize that. [00:51:53]
Swyx: I think after this, [00:51:53]
Harrison: we definitely bumped it up and prioritized in priority. And luckily Nuno had been doing a lot of awesome work on it already, so it wasn't too much of a lift. But yeah, now there's this way where a lot of the chains that we've been releasing are written in this LangChain expression language where they're actually truly composable, and you can see what's going on under the hood. And it's basically, it uses kind of like the pipe kind of like terminology to coordinate things and move things around. So yeah, I mean, I think there were a lot of good points in those Hacker News things, and you know, we can't respond to everything, but we try to like look at everything and take everything seriously. [00:52:25]
Swyx: You're being very diplomatic. But so first of all, I like the expression language. I think that that is the path towards sort of language agnostic LangChain kind of, or whatever, DSL. But also like, what was just kind of plain wrong or plain offensive, or like, I don't know, people can get very vitriolic sometimes on Hacker News. [00:52:40]
Harrison: Yeah, I mean, I think the comments that I appreciated were the ones where they gave specific things. And I think the ones where they said, you know, LangChain sucks. Like, okay. Can't do much of that. [00:52:51]
Swyx: Yeah, exactly. Verifacing on my question would be like, you're not the first and you won't be the last to have that kind of very intense scrutiny. What would be your advice to other people, other maintainers of projects for going through something like this? [00:53:03]
Harrison: I would probably say, try to drill into like what is actually underlying things [00:53:08]
Swyx: as much as possible. [00:53:08]
Harrison: And if there is actual substance that's being delivered, whether you agree with it or not, like, I think that's valuable to know. And then for the other stuff, like try to maybe follow up, but maybe try not to let it get under your skin too much. [00:53:22]
Swyx: Thanks for tackling that. [00:53:24]
Alessio: And I know we're getting to the time and we'll wrap up soon, but since you're going to speak at the AI Engineers Conference, what's your advice to AI engineers, especially when to start with LangChain and when they're just experimenting with a model, [00:53:38]
Swyx: when are they, [00:53:38]
Alessio: as you mentioned, if you just want to do an API call, don't use LangChain. Yeah. [00:53:43]
Harrison: I mean, my advice would just like build as many things as possible. Like, I think it's still really early in the space. No one really knows what they're doing to some extent. Like, it's a bit weird to say, but there's so many things to like discover. So I would just say like, build as many things as possible. Cause I think like the best thing is you stumble upon a really good idea and you build something really awesome. And the worst thing that happens is you just learn a lot about a field and the technology that's going to be incredibly important and rapidly kind of like changing. [00:54:11]
Alessio: What would you build if you weren't doing LangChain? [00:54:13]
Harrison: I mean, the things that are most interesting to me are kind of like things around like long-term memory and like longer running agents. So I'd probably build, and these are things that we've been wanting to build [00:54:23]
Swyx: internally as well. [00:54:23]
Harrison: But like, I think a chatbot that like actually remembers things about you as like silly as that sounds, like people like chatbots a lot and they have their delivered limited by their context window. And so I think really diving into like a specific application of memory there. [00:54:38]
Swyx: I've been trying to build a chatbot [00:54:39]
Harrison: that remembers things about you. That would be one. And then like, I know a lot of people are doing this, but like a personal assistant for like managing like email calendar, basic stuff, which I think is, I think that's like a fantastic application for these like agent like things, because if you think about personal assistants today, you usually interact, I don't have one, but I'm told you interact with them over email. And the nice thing about that, as opposed to like chat, there's not as stringent an expectation on latency as there is on chat. And so you can do a lot of things like reflection and kind of like making sure that you're on the right track and really put more safeguards and thinking about these agents as opposed to relying on like chas and interface, like the bot we have that's on GitHub answering questions on the issues, I think probably gives better answers than the bots that we have that are on chat on the website. And I think that's not because, there's just different constraints that you have in different types of problems. And I think I would be like, I think the personal assistant one's really interesting because you remove the constraint of chat, which I think at this point in time is probably pretty limited in terms of functionality. [00:55:43]
Swyx: Yeah. I've been calling this sort of long inference. If you didn't have to care about ANC and you could take like a day, a month, a year to work on something, what could you do? And yeah, that's super interesting. [00:55:56]
Harrison: I think that's a really promising place to explore. [00:55:58]
Swyx: Yeah. Have you looked at, regarding the long conversation thing, you and I have tried it about this many times. Have you looked into what character and inflection are doing? Because they're probably working on it. [00:56:08]
Harrison: I've thought about memory a bunch. Like I think it comes down to like, it comes down to like state, like what's the state you're tracking? Like what's the data structure for that? And I think that could also maybe be a bit like application specific. But if we're talking about a generic chat bot, that's kind of generic. I don't know. Yeah, I don't know how they're thinking about that. My sense is that inflection like thinks about that a bit more than character. Like I think in Inception, sorry, inflection's whole thing is they like, the bot knows you. [00:56:33]
Swyx: It's one chat. There's no history. You just talk to it. Yeah. [00:56:37]
Harrison: So they've definitely got some state that they're tracking. I'd be really curious to know what that is. Character, I don't think has lent into it too much. I think they let you do some stuff in terms of like uploading background. And I'm not entirely sure how they use that, whether they just like put that in the prompt or do some retrieval over that. But I think they're definitely, they haven't lent into it as much as inflection, I would say. [00:56:57]
Swyx: So given like, you are one of the most interested people in this space, would this be like a second product for you? If you ever want to explore that or do you want to just partner with people and you're putting out the call for people to come to you if they have solutions for that? [00:57:10]
Harrison: If I wasn't working on LangChain, I would be building an application company, for sure, first of all. Like, I don't think, like I think like there's, which I know is very hypocritical to say. [00:57:20]
Swyx: Like you're Mr. DevTools and Infra and Observability. [00:57:24]
Harrison: Yeah, I don't know. If you're building an application company that's working on something related to long-term memory or long-term agents, I would love to chat and just geek out [00:57:31]
Swyx: about a lot of this stuff. I'll show you Smalltalk at some point. Yes. Cool. Awesome. [00:57:37]
Alessio: Yeah, let's do a lightning round. [00:57:38]
Swyx: So the first one is on acceleration. What has happened in AI that you thought would take much longer than it actually ended up taking? [00:57:45]
Harrison: The function call and ability from OpenAI, like tool usage. [00:57:48]
Swyx: Yeah. [00:57:48]
Harrison: They did that really fast, I thought. [00:57:50]
Swyx: Yeah. But it's just a question of fine-tuning, no? Yeah. It's not even like reliable. [00:57:54]
Harrison: It's not terrible. They're a pretty big organization that's serving a lot of traffic. And like, this was a, yeah, it's like, it is like just fine-tuning, but I think like you still have to like collect that data set and fine-tune it and evaluate it and then release it at scale and figure out the right API. [00:58:09]
Swyx: No shade on OpenAI. Like they're moving everyone's bar as to how quickly like a 400% organization can go. Do you think it eliminates like approaches like JSONformer and all the other approaches that people, like guardrails, you know, previous guest, eliminates your output validation thing? Yeah. [00:58:26]
Harrison: I think JSONformer and stuff like that are still really interesting for like local models, for sure. And there's like 90% of people use OpenAI or something and like my made up numbers. [00:58:37]
Swyx: No, it's probably real. [00:58:38]
Harrison: And the best way to get structured output is by using the function calling ability. So yeah, absolutely. [00:58:46]
Alessio: What do you think is the most interesting unsolved question in AI? [00:58:50]
Harrison: I'm really interested like how multimodal is going to work. Like with just what that looks like. [00:58:55]
Swyx: Have you had a look at the GPT-4 vision? No, not really. [00:58:59]
Harrison: Yeah, not beyond what they- [00:59:01]
Swyx: They're doing private betas right now. So I'm very excited. [00:59:04]
Harrison: I'm excited about that as well. Yeah, I mean, I think that's, you know, you talk about like, again, this whole space is just changing so fast, but you talk about something that could like really change how, because like, you know, a lot of lang chain is kind of like a data orchestration tool in some sense. And so if you had a whole new type of data in there. [00:59:20]
Swyx: So maybe we do this thought exercise, right? Tomorrow, OpenAI releases the GPT-4 vision API. What does lang chain do? [00:59:25]
Harrison: Immediately we add support for it in like the wrapper. So however you interact, like honestly, this is another like fun thing. Everyone's API now looks like OpenAI's. [00:59:35]
Swyx: Yeah, which is great. [00:59:36]
Harrison: Which you have to do, yeah. So like our wrapper looks similar to OpenAI. So I don't think it will be that difficult to include support for it at the basic model level. And so we do that. And now that we've released the expression language bit, like a lot of the core chains, we have examples of rewriting them just in this expression language. So like for retrieval, if we're now talking about like, okay, you can do like retrieval question answering over for multimodal things, we'd probably have to figure out how those are getting stored and what's being done with them. But then from there, that should be, yeah, so probably looking to like, yeah, how are people kind of like storing and consuming this type of information? But then that step should be pretty easy to plug into the kind of like chain. [01:00:17]
Swyx: Multimodal stores? Yeah, I don't know. I always wonder what that would actually look like because a lot of multimodality in LLMs is really just an LLM, a text LLM calling a different model. And that's just no different than any API call, essentially unchanged. [01:00:32]
Harrison: I think it's probably something that you don't know until you let like a million people play around with it. [01:00:37]
Swyx: Then there'll be new LangChain for multimodal. What's one message you want everyone to remember today? [01:00:43]
Harrison: I would probably say just like build. I think it's a fantastic time to be building. [01:00:47]
Swyx: All right, just build. Yeah. [01:00:49]
Alessio: Thank you Harrison for coming on. [01:00:51]
Swyx: Thanks so much. [01:00:51]
Harrison: Thank you guys for having me. [01:00:52]
Swyx: It's a lot of fun. [01:00:53]
Smaller prompt tooling libraries, like Deepset’s Haystack, have also recently come under fire, and other early attempts, like Manifest, Promptable and Everyprompt, have come and gone. Microsoft’s Semantic Kernel started in the C# arena but has since branched out to Python and Java.
Harrison’s initial Notion + LLMs exploration was later rebuilt with LangChain: https://github.com/hwchase17/notion-qa
Stable Diffusion just celebrated its 1yr anniversary!
Framing the original tweet as one of the milestones of AI Engineering
Something Harrison calls out in our pod as underappreciated, do check it out!
Harrison recently launched a Text Splitting Playground to help users understand them
Also mentioned on the pod - A very underrated interface to vector stores that allows making hybrid semantic search with metadata filtering
“The difference between chains and agents is that chains are deterministic in how data flow through them, while agents rely on an LLM to control that flow". swyx participated in a Chains vs Agents webinar with Harrison.
Curiously, an order of magnitude less on their LinkedIn
Another worthwhile diagram from Harry Zhang here:

A former LangChain teacher, notably!


Share this post