




Editor’s note: One of the top reasons we have hundreds of companies and thousands of AI Engineers joining the World’s Fair next week is, apart from discussing technology and being present for the big launches planned, to hire and be hired!
Listeners loved our previous Elicit episode and were so glad to welcome 2 more members of Elicit back for a guest post (and bonus podcast) on how they think through hiring. Don’t miss their AI engineer job description, and template which you can use to create your own hiring plan!
How to Hire AI Engineers
James Brady, Head of Engineering @ Elicit (ex Spring, Square, Trigger.io, IBM)
Adam Wiggins, Internal Journalist @ Elicit (Cofounder Ink & Switch and Heroku)
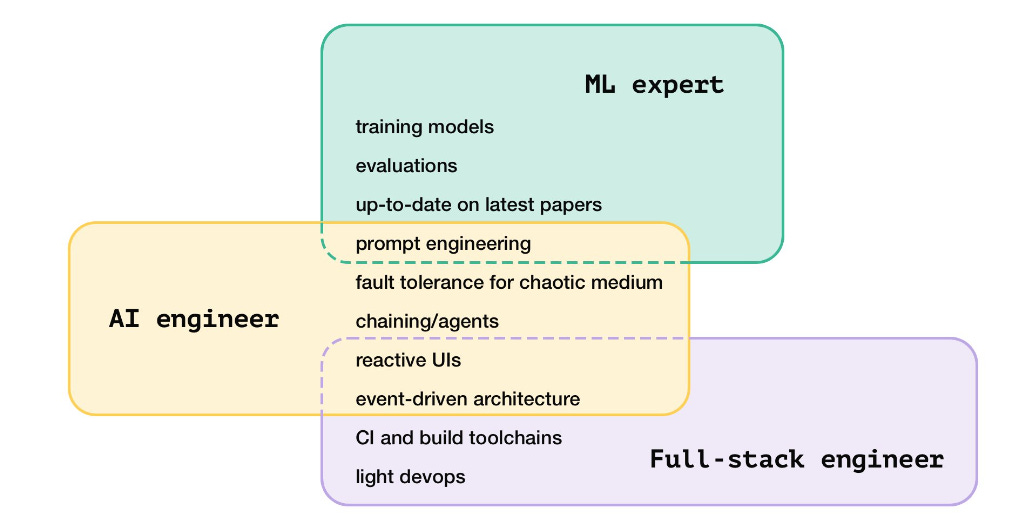
If you’re leading a team that uses AI in your product in some way, you probably need to hire AI engineers. As defined in this article, that’s someone with conventional engineering skills in addition to knowledge of language models and prompt engineering, without being a full-fledged Machine Learning expert.
But how do you hire someone with this skillset? At Elicit we’ve been applying machine learning to reasoning tools since 2018, and our technical team is a mix of ML experts and what we can now call AI engineers. This article will cover our process from job description through interviewing. (You can also flip the perspectives here and use it just as easily for how to get hired as an AI engineer!)
My own journey
Before getting into the brass tacks, I want to share my journey to becoming an AI engineer.
Up until a few years ago, I was happily working my job as an engineering manager of a big team at a late-stage startup. Like many, I was tracking the rapid increase in AI capabilities stemming from the deep learning revolution, but it was the release of GPT-3 in 2020 which was the watershed moment. At the time, we were all blown away by how the model could string together coherent sentences on demand. (Oh how far we’ve come since then!)
I’d been a professional software engineer for nearly 15 years—enough to have experienced one or two technology cycles—but I could see this was something categorically new. I found this simultaneously exciting and somewhat disconcerting. I knew I wanted to dive into this world, but it seemed like the only path was going back to school for a master’s degree in Machine Learning. I started talking with my boss about options for taking a sabbatical or doing a part-time distance learning degree.
In 2021, I instead decided to launch a startup focused on productizing new research ideas on ML interpretability. It was through that process that I reached out to Andreas—a leading ML researcher and founder of Elicit—to see if he would be an advisor. Over the next few months, I learned more about Elicit: that they were trying to apply these fascinating technologies to the real-world problems of science, and with a business model that aligned it with safety goals. I realized that I was way more excited about Elicit than I was about my own startup ideas, and wrote about my motivations at the time.
Three years later, it’s clear this was a seismic shift in my career on the scale of when I chose to leave my comfy engineering job at IBM to go through the Y Combinator program back in 2008. Working with this new breed of technology has been more intellectually stimulating, challenging, and rewarding than I could have imagined.
Deep ML expertise not required
It’s important to note that AI engineers are not ML experts, nor is that their best contribution to a tech team.
In our article Living documents as an AI UX pattern, we wrote:
It’s easy to think that AI advancements are all about training and applying new models, and certainly this is a huge part of our work in the ML team at Elicit. But those of us working in the UX part of the team believe that we have a big contribution to make in how AI is applied to end-user problems.
We think of LLMs as a new medium to work with, one that we’ve barely begun to grasp the contours of. New computing mediums like GUIs in the 1980s, web/cloud in the 90s and 2000s, and multitouch smartphones in the 2000s/2010s opened a whole new era of engineering and design practices. So too will LLMs open new frontiers for our work in the coming decade.
To compare to the early era of mobile development: great iOS developers didn’t require a detailed understanding of the physics of capacitive touchscreens. But they did need to know the capabilities and limitations of a multi-touch screen, the constrained CPU and storage available, the context in which the user is using it (very different from a webpage or desktop computer), etc.
In the same way, an AI engineer needs to work with LLMs as a medium that is fundamentally different from other compute mediums. That means an interest in the ML side of things, whether through their own self-study, tinkering with prompts and model fine-tuning, or following along in #llm-paper-club. But this understanding is so that they can work with the medium effectively versus, say, spending their days training new models.
Language models as a chaotic medium
So if we’re not expecting deep ML expertise from AI engineers, what are we expecting? This brings us to what makes LLMs different.
We’ll assume already that our ideal candidate is already inspired by, and full of ideas about, all the new capabilities AI can bring to software products.
But the flip side is all the things that make this new medium difficult to work with. LLM calls are annoying due to high latency (measured in tens of seconds sometimes, rather than milliseconds), extreme variance on latency, high error rates even under normal operation. Not to mention getting extremely different answers to the same prompt provided to the same model on two subsequent calls!
The net effect is that an AI engineer, even working at the application development level, needs to have a skillset comparable to distributed systems engineering. Handling errors, retries, asynchronous calls, streaming responses, parallelizing and recombining model calls, the halting problem, and fallbacks are just some of the day-in-the-life of an AI engineer. Chaos engineering gets new life in the era of AI.
Skills and qualities in candidates
Let’s put together what we don’t need (deep ML expertise) with what we do (work with capabilities and limitations of the medium). Thus we start to see what Elicit looks for in AI engineers:
Conventional software engineering skills. Especially back-end engineering on complex, data-intensive applications.
Professional, real-world experience with applications at scale.
Deep, hands-on experience across a few back-end web frameworks.
Light devops and an understanding of infrastructure best practices.
Queues, message buses, event-driven and serverless architectures, … there’s no single “correct” approach, but having a deep toolbox to draw from is very important.
A genuine curiosity and enthusiasm for the capabilities of language models.
One or more serious projects (side projects are fine) of using them in interesting ways on a unique domain.
…ideally with some level of factored cognition, e.g. breaking the problem down into chunks, making thoughtful decisions about which things to push to the language model and which stay within the realm of conventional heuristics and compute capabilities.
Personal studying with resources like Elicit’s ML reading list. Part of the role is collaborating with the ML engineers and researchers on our team. To do so, the candidate needs to “speak their language” somewhat, just as a mobile engineer needs some familiarity with backends in order to collaborate effectively on API creation with backend engineers.
An understanding of the challenges that come along with working with large models (high latency, variance, etc.) leading to a defensive, fault-first mindset.
Careful and principled handling of error cases, asynchronous code (and ability to reason about and debug it), streaming data, caching, logging and analytics for understanding behavior in production.
This is a similar mindset that one can develop working on conventional apps which are complex, data-intensive, or large-scale apps. The difference is that an AI engineer will need this mindset even when working on relatively small scales!
On net, a great AI engineer will combine two seemingly contrasting perspectives: knowledge of, and a sense of wonder for, the capabilities of modern ML models; but also the understanding that this is a difficult and imperfect foundation, and the willingness to build resilient and performant systems on top of it.
Here’s the resulting AI engineer job description for Elicit. And here’s a template that you can borrow from for writing your own JD.
Hiring process
Once you know what you’re looking for in an AI engineer, the process is not too different from other technical roles. Here’s how we do it, broken down into two stages: sourcing and interviewing.
Sourcing
We’re primarily looking for people with (1) a familiarity with and interest in ML, and (2) proven experience building complex systems using web technologies. The former is important for culture fit and as an indication that the candidate will be able to do some light prompt engineering as part of their role. The latter is important because language model APIs are built on top of web standards and—as noted above—aren’t always the easiest tools to work with.
Only a handful of people have built complex ML-first apps, but fortunately the two qualities listed above are relatively independent. Perhaps they’ve proven (2) through their professional experience and have some side projects which demonstrate (1).
Talking of side projects, evidence of creative and original prototypes is a huge plus as we’re evaluating candidates. We’ve barely scratched the surface of what’s possible to build with LLMs—even the current generation of models—so candidates who have been willing to dive into crazy “I wonder if it’s possible to…” ideas have a huge advantage.
Interviewing
The hard skills we spend most of our time evaluating during our interview process are in the “building complex systems using web technologies” side of things. We will be checking that the candidate is familiar with asynchronous programming, defensive coding, distributed systems concepts and tools, and display an ability to think about scaling and performance. They needn’t have 10+ years of experience doing this stuff: even junior candidates can display an aptitude and thirst for learning which gives us confidence they’ll be successful tackling the difficult technical challenges we’ll put in front of them.
One anti-pattern—something which makes my heart sink when I hear it from candidates—is that they have no familiarity with ML, but claim that they’re excited to learn about it. The amount of free and easily-accessible resources available is incredible, so a motivated candidate should have already dived into self-study.
Putting all that together, here’s the interview process that we follow for AI engineer candidates:
30-minute introductory conversation. Non-technical, explaining the interview process, answering questions, understanding the candidate’s career path and goals.
60-minute technical interview. This is a coding exercise, where we play product manager and the candidate is making changes to a little web app. Here are some examples of topics we might hit upon through that exercise:
Update API endpoints to include extra metadata. Think about appropriate data types. Stub out frontend code to accept the new data.
Convert a synchronous REST API to an asynchronous streaming endpoint.
Cancellation of asynchronous work when a user closes their tab.
Choose an appropriate data structure to represent the pending, active, and completed ML work which is required to service a user request.
60–90 minute non-technical interview. Walk through the candidate’s professional experience, identifying high and low points, getting a grasp of what kinds of challenges and environments they thrive in.
On-site interviews. Half a day in our office in Oakland, meeting as much of the team as possible: more technical and non-technical conversations.
The frontier is wide open
Although Elicit is perhaps further along than other companies on AI engineering, we also acknowledge that this is a brand-new field whose shape and qualities are only just now starting to form. We’re looking forward to hearing how other companies do this and being part of the conversation as the role evolves.
We’re excited for the AI Engineer World’s Fair as another next step for this emerging subfield. And of course, check out the Elicit careers page if you’re interested in joining our team.
Podcast version
Timestamps
[00:00:24] Intros
[00:05:25] Defining the Hiring Process
[00:08:42] Defensive AI Engineering as a chaotic medium
[00:10:26] Tech Choices for Defensive AI Engineering
[00:14:04] How do you Interview for Defensive AI Engineering
[00:19:25] Does Model Shadowing Work?
[00:22:29] Is it too early to standardize Tech stacks?
[00:32:02] Capabilities: Offensive AI Engineering
[00:37:24] AI Engineering Required Knowledge
[00:40:13] ML First Mindset
[00:45:13] AI Engineers and Creativity
[00:47:51] Inside of Me There Are Two Wolves
[00:49:58] Sourcing AI Engineers
[00:58:45] Parting Thoughts
Transcript
[00:00:00] swyx: Okay, so welcome to the Latent Space Podcast. This is another remote episode that we're recording. This is the first one that we're doing around a guest post. And I'm very honored to have two of the authors of the post with me, James and Adam from Elicit. Welcome, James. Welcome, Adam.
[00:00:22] James Brady: Thank you. Great to be here.
[00:00:23] Hey there.
[00:00:24] Intros
[00:00:24] swyx: Okay, so I think I will do this kind of in order. I think James, you're, you're sort of the primary author. So James, you are head of engineering at Elicit. You also, We're VP Eng at Teespring and Spring as well. And you also , you have a long history in sort of engineering. How did you, , find your way into something like Elicit where, , it's, you, you are basically traditional sort of VP Eng, VP technology type person moving into a more of an AI role.
[00:00:53] James Brady: Yeah, that's right. It definitely was something of a Sideways move if not a left turn. So the story there was I'd been doing, as you said, VP technology, CTO type stuff for around about 15 years or so, and Notice that there was this crazy explosion of capability and interesting stuff happening within AI and ML and language models, that kind of thing.
[00:01:16] I guess this was in 2019 or so, and decided that I needed to get involved. , this is a kind of generational shift. And Spent maybe a year or so trying to get up to speed on the state of the art, reading papers, reading books, practicing things, that kind of stuff. Was going to found a startup actually in in the space of interpretability and transparency, and through that met Andreas, who has obviously been on the, on the podcast before asked him to be an advisor for my startup, and he countered with, maybe you'd like to come and run the engineering team at Elicit, which it turns out was a much better idea.
[00:01:48] And yeah, I kind of quickly changed in that direction. So I think some of the stuff that we're going to be talking about today is how actually a lot of the work when you're building applications with AI and ML looks and smells and feels much more like conventional software engineering with a few key differences rather than really deep ML stuff.
[00:02:07] And I think that's one of the reasons why I was able to transfer skills over from one place to the other.
[00:02:12] swyx: Yeah, I
[00:02:12] James Brady: definitely
[00:02:12] swyx: agree with that. I, I do often say that I think AI engineering is about 90 percent software engineering with like the, the 10 percent of like really strong really differentiated AI engineering.
[00:02:22] And that might, that obviously that number might change over time. I want to also welcome Adam onto my podcast because you welcomed me onto your podcast two years ago.
[00:02:31] Adam Wiggins: Yeah, that was a wonderful episode.
[00:02:32] swyx: That was, that was a fun episode. You famously founded Heroku. You just wrapped up a few years working on Muse.
[00:02:38] And now you've described yourself as a journalist, internal journalist working on Elicit.
[00:02:43] Adam Wiggins: Yeah, well I'm kind of a little bit in a wandering phase here and trying to take this time in between ventures to see what's out there in the world and some of my wandering took me to the Elicit team. And found that they were some of the folks who were doing the most interesting, really deep work in terms of taking the capabilities of language models and applying them to what I feel like are really important problems.
[00:03:08] So in this case, science and literature search and, and, and that sort of thing. It fits into my general interest in tools and productivity software. I, I think of it as a tool for thought in many ways, but a tool for science, obviously, if we can accelerate that discovery of new medicines and things like that, that's, that's just so powerful.
[00:03:24] But to me, it's a. It's kind of also an opportunity to learn at the feet of some real masters in this space, people who have been working on it since it was, before it was cool, if you want to put it that way. So for me, the last couple of months have been this crash course, and why I sometimes describe myself as an internal journalist is I'm helping to write some, some posts, including Supporting James in this article here we're doing for latent space where I'm just bringing my writing skill and that sort of thing to bear on their very deep domain expertise around language models and applying them to the real world and kind of surface that in a way that's I don't know, accessible, legible, that, that sort of thing.
[00:04:03] And so, and the great benefit to me is I get to learn this stuff in a way that I don't think I would, or I haven't, just kind of tinkering with my own side projects.
[00:04:12] swyx: I forgot to mention that you also run Ink and Switch, which is one of the leading research labs, in my mind, of the tools for thought productivity space, , whatever people mentioned there, or maybe future of programming even, a little bit of that.
[00:04:24] As well. I think you guys definitely started the local first wave. I think there was just the first conference that you guys held. I don't know if you were personally involved.
[00:04:31] Adam Wiggins: Yeah, I was one of the co organizers along with a few other folks for, yeah, called Local First Conf here in Berlin.
[00:04:36] Huge success from my, my point of view. Local first, obviously, a whole other topic we can talk about on another day. I think there actually is a lot more what would you call it , handshake emoji between kind of language models and the local first data model. And that was part of the topic of the conference here, but yeah, topic for another day.
[00:04:55] swyx: Not necessarily. I mean , I, I selected as one of my keynotes, Justine Tunney, working at LlamaFall in Mozilla, because I think there's a lot of people interested in that stuff. But we can, we can focus on the headline topic. And just to not bury the lead, which is we're talking about hire, how to hire AI engineers, this is something that I've been looking for a credible source on for months.
[00:05:14] People keep asking me for my opinions. I don't feel qualified to give an opinion and it's not like I have. So that's kind of defined hiring process that I'm super happy with, even though I've worked with a number of AI engineers.
[00:05:25] Defining the Hiring Process
[00:05:25] swyx: I'll just leave it open to you, James. How was your process of defining your hiring, hiring roles?
[00:05:31] James Brady: Yeah. So I think the first thing to say is that we've effectively been hiring for this kind of a role since before you, before you coined the term and tried to kind of build this understanding of what it was.
[00:05:42] So, which is not a bad thing. Like it's, it was a, it was a good thing. A concept, a concept that was coming to the fore and effectively needed a name, which is which is what you did. So the reason I mentioned that is I think it was something that we kind of backed into, if you will. We didn't sit down and come up with a brand new role from, from scratch of this is a completely novel set of responsibilities and skills that this person would need.
[00:06:06] However, it is a A kind of particular blend of different skills and attitudes and and curiosities interests, which I think makes sense to kind of bundle together. So in the, in the post, the three things that we say are most important for a highly effective AI engineer are first of all, conventional software engineering skills, which is Kind of a given, but definitely worth mentioning.
[00:06:30] The second thing is a curiosity and enthusiasm for machine learning and maybe in particular language models. That's certainly true in our case. And then the third thing is to do with basically a fault first mindset, being able to build systems that can handle things going wrong in, in, in some sense.
[00:06:49] And yeah, the I think the kind of middle point, the curiosity about ML and language models is probably fairly self evident. They're going to be working with, and prompting, and dealing with the responses from these models, so that's clearly relevant. The last point, though, maybe takes the most explaining.
[00:07:07] To do with this fault first mindset and the ability to, to build resilient systems. The reason that is, is so important is because compared to normal APIs, where normal, think of something like a Stripe API or a search API or something like this. The latency when you're working with language models is, is wild, like you can get 10x variation.
[00:07:32] I mean, I was looking at the stats before, actually, before, before the podcast. We do often, normally, in fact, see a 10x variation in the P90 latency over the course of, Half an hour, an hour when we're prompting these models, which is way higher than if you're working with a, more kind of conventional conventionally backed API.
[00:07:49] And the responses that you get, the actual content and the responses are naturally unpredictable as well. They come back with different formats. Maybe you're expecting JSON. It's not quite JSON. You have to handle this stuff. And also the, the semantics of the messages are unpredictable too, which is, which is a good thing.
[00:08:08] Like this is one of the things that you're looking for from these language models, but it all adds up to needing to. Build a resilient, reliable, solid feeling system on top of this fundamentally, well, certainly currently fundamentally shaky foundation. The models do not behave in the way that you would like them to.
[00:08:28] And yeah, the ability to structure the code around them such that it does give the user this warm, reassuring, Snappy, solid feeling is is really what we're driving for there.
[00:08:42] Defensive AI Engineering as a chaotic medium
[00:08:42] Adam Wiggins: What really struck me as we, we dug in on the content for this article was that third point there. The, the language models is this kind of chaotic medium, this, this dragon, this wild horse you're, you're, you're riding and trying to guide in the direction that is going to be useful and reliable to users, because I think.
[00:08:58] So much of software engineering is about making things not only high performance and snappy, but really just making it stable, reliable, predictable, which is literally the opposite of what you get from from the language models. And yet, yeah, the output is so useful, and indeed, some of their Creativity, if you want to call it that, which is, is precisely their value.
[00:09:19] And so you need to work with this medium. And I guess the nuanced or the thing that came out of Elissa's experience that I thought was so interesting is quite a lot of working with that is things that come from distributed systems engineering. But you have really the AI engineers as we're defining them or, or labeling them on the illicit team is people who are really application developers.
[00:09:39] You're building things for end users. You're thinking about, okay, I need to populate this interface with some response to user input. That's useful to the tasks they're trying to do, but you have this. This is the thing, this medium that you're working with that in some ways you need to apply some of this chaos engineering, distributed systems engineering, which typically those people with those engineering skills are not kind of the application level developers with the product mindset or whatever, they're more deep in the guts of a, of a system.
[00:10:07] And so it's, those, those skills and, and knowledge do exist throughout the engineering discipline, but sort of putting them together into one person that is That feels like sort of a unique thing and working with the folks on the Elicit team who have that skills I'm quite struck by that unique that unique blend.
[00:10:23] I haven't really seen that before in my 30 year career in technology.
[00:10:26] Tech Choices for Defensive AI Engineering
[00:10:26] swyx: Yeah, that's a Fascinating I like the reference to chaos engineering. I have some appreciation, I think when you had me on your podcast, I was still working at Temporal and that was like a nice Framework, if you live within Temporal's boundaries, you can pretend that all those faults don't exist, and you can, you can code in a sort of very fault tolerant way.
[00:10:47] What is, what is you guys solutions around this, actually? Like, I think you're, you're emphasizing having the mindset, but maybe naming some technologies would help? Not saying that you have to adopt these technologies, but they're just, they're just quick vectors into what you're talking about when you're, when you're talking about distributed systems.
[00:11:03] Like, that's such a big, chunky word, , like are we talking, are Kubernetes or, and I suspect we're not, , like we're, we're talking something else now.
[00:11:10] James Brady: Yeah, that's right. It's more at the application level rather than at the infrastructure level, at least, at least the way that it works for us.
[00:11:17] So there's nothing kind of radically novel here. It is more a careful application of existing concepts. So the kinds of tools that we reach for to handle these kind of slightly chaotic objects that Adam was just talking about, are retries and fallbacks and timeouts and careful error handling. And, yeah, the standard stuff, really.
[00:11:39] There's also a great degree of dependence. We rely heavily on parallelization because, , these language models are not innately very snappy, and , there's just a lot of I. O. going back and forth. So All these things I'm talking about when I was in my earlier stages of a career, these are kind of the things that are the difficult parts that most senior software engineers will be better at.
[00:12:01] It is careful error handling, and concurrency, and fallbacks, and distributed systems, and, , eventual consistency, and all this kind of stuff and As Adam was saying, the kind of person that is deep in the guts of some kind of distributed systems, a really high, high scale backend kind of a problem would probably naturally have these kinds of skills.
[00:12:21] But you'll find them on, on day one, if you're building a, , an ML powered app, even if it's not got massive scale. I think one one thing that I would mention that we do do yeah, maybe, maybe two related things, actually. The first is we're big fans of strong typing. We share the types all the way from the Backend Python code all the way to the to the front end in TypeScript and find that is I mean We'd probably do this anyway But it really helps one reason around the shapes of the data which can going to be going back and forth and that's really important When you can't rely upon You you're going to have to coerce the data that you get back from the ML if you want if you want for it to be structured basically speaking and The second thing which is related is we use checked exceptions inside our Python code base, which means that we can use the type system to make sure we are handling, properly handling, all of the, the various things that could be going wrong, all the different exceptions that could be getting raised.
[00:13:16] So, checked exceptions are not, not really particularly popular. Actually there's not many people that are big fans of them. For our particular use case, to really make sure that we've not just forgotten to handle, , This particular type of error we have found them useful to to, to force us to think about all the different edge cases that can come up.
[00:13:32] swyx: Fascinating. How just a quick note of technology. How do you share types from Python to TypeScript? Do you, do you use GraphQL? Do you use something
[00:13:39] James Brady: else? We don't, we don't use GraphQL. Yeah. So we've got the We've got the types defined in Python, that's the source of truth. And we go from the OpenAPI spec, and there's a, there's a tool that you work and use to generate types dynamically, like TypeScript types from those OpenAPI definitions.
[00:13:57] swyx: Okay, excellent. Okay, cool. Sorry, sorry for diving into that rabbit hole a little bit. I always like to spell out technologies for people to dig their teeth into.
[00:14:04] How do you Interview for Defensive AI Engineering
[00:14:04] swyx: One thing I'll, one thing I'll mention quickly is that a lot of the stuff that you mentioned is typically not part of the normal interview loop.
[00:14:10] It's actually really hard to interview for because this is the stuff that you polish out in, as you go into production, the coding interviews are typically about the happy path. How do we do that? How do we, how do we design, how do you look for a defensive fault first mindset?
[00:14:24] Because you can defensive code all day long and not add functionality. to your to your application.
[00:14:29] James Brady: Yeah, it's a great question and I think that's exactly true. Normally the interview is about the happy path and then there's maybe a box checking exercise at the end of the candidate says of course in reality I would handle the edge cases or something like this and that unfortunately isn't isn't quite good enough when when the happy path is is very very narrow and yeah there's lots of weirdness on either side so basically speaking, it's just a case of, of foregrounding those kind of concerns through the interview process.
[00:14:58] It's, there's, there's no magic to it. We, we talk about this in the, in the po in the post that we're gonna be putting up on, on Laton space. The, there's two main technical exercises that we do through our interview process for this role. The first is more coding focus, and the second is more system designy.
[00:15:16] Yeah. White whiteboarding a potential solution. And in, without giving too much away in the coding exercise. You do need to think about edge cases. You do need to think about errors. The exercise consists of adding features and fixing bugs inside the code base. And in both of those two cases, it does demand, because of the way that we set the application up and the interview up, it does demand that you think about something other than the happy path.
[00:15:41] But your thinking is the right prompt of how do we get the candidate thinking outside of the, the kind of normal Sweet spot, smooth smooth, smoothly paved path. In terms of the system design interview, that's a little easier to prompt this kind of fault first mindset because it's very easy in that situation just to say, let's imagine that, , this node dies, how does the app still work?
[00:16:03] Let's imagine that this network is, is going super slow. Let's imagine that, I don't know, like you, you run out of, you run out of capacity in, in, in this database that you've sketched out here, how do you handle that, that, that sort of stuff. So. It's, in both cases, they're not firmly anchored to and built specifically around language models and ways language models can go wrong, but we do exercise the same muscles of thinking defensively and yeah, foregrounding the edge cases, basically.
[00:16:32] Adam Wiggins: James, earlier there you mentioned retries. And this is something that I think I've seen some interesting debates internally about things regarding, first of all, retries are, can be costly, right? In general, this medium, in addition to having this incredibly high variance and response rate, and, , being non deterministic, is actually quite expensive.
[00:16:50] And so, in many cases, doing a retry when you get a fail does make sense, but actually that has an impact on cost. And so there is Some sense to which, at least I've seen the AI engineers on our team, worry about that. They worry about, okay, how do we give the best user experience, but balance that against what the infrastructure is going to, , is going to cost our company, which I think is again, an interesting mix of, yeah, again, it's a little bit the distributed system mindset, but it's also a product perspective and you're thinking about the end user experience, but also the.
[00:17:22] The bottom line for the business, you're bringing together a lot of a lot of qualities there. And there's also the fallback case, which is kind of, kind of a related or adjacent one. I think there was also a discussion on that internally where, I think it maybe was search, there was something recently where there was one of the frontline search providers was having some, yeah, slowness and outages, and essentially then we had a fallback, but essentially that gave people for a while, especially new users that come in that don't the difference, they're getting a They're getting worse results for their search.
[00:17:52] And so then you have this debate about, okay, there's sort of what is correct to do from an engineering perspective, but then there's also what actually is the best result for the user. Is giving them a kind of a worse answer to their search result better, or is it better to kind of give them an error and be like, yeah, sorry, it's not working right at the moment, try again.
[00:18:12] Later, both are obviously non optimal, but but this is the kind of thing I think that that you run into or, or the kind of thing we need to grapple with a lot more than you would other kinds of, of mediums.
[00:18:24] James Brady: Yeah, that's a really good example. I think it brings to the fore the two different things that you could be optimizing for of uptime and response at all costs on one end of the spectrum and then effectively fragility, but kind of, if you get a response, it's the best response we can come up with at the other end of the spectrum.
[00:18:43] And where you want to land there kind of depends on, well, it certainly depends on the app, obviously depends on the user. I think it depends on the, feature within the app as well. So in the search case that you, that you mentioned there, in retrospect, we probably didn't want to have the fallback. And we've actually just recently on Monday, changed that to Show an error message rather than giving people a kind of degraded experience in other situations We could use for example a large language model from a large language model from provider B rather than provider A and Get something which is within the A few percentage points performance, and that's just a really different situation.
[00:19:21] So yeah, like any interesting question, the answer is, it depends.
[00:19:25] Does Model Shadowing Work?
[00:19:25] swyx: I do hear a lot of people suggesting I, let's call this model shadowing as a defensive technique, which is, if OpenAI happens to be down, which, , happens more often than people think then you fall back to anthropic or something.
[00:19:38] How realistic is that, right? Like you, don't you have to develop completely different prompts for different models and won't the, won't the performance of your application suffer from whatever reason, right? Like it may be caused differently or it's not maintained in the same way. I, I think that people raise this idea of fallbacks to models, but I don't think it's, I don't, I don't see it practiced very much.
[00:20:02] James Brady: Yeah, it is, you, you definitely need to have a different prompt if you want to stay within a few percentage points degradation Like I, like I said before, and that certainly comes at a cost, like fallbacks and backups and things like this It's really easy for them to go stale and kind of flake out on you because they're off the beaten track And In our particular case inside of Elicit, we do have fallbacks for a number of kind of crucial functions where it's going to be very obvious if something has gone wrong, but we don't have fallbacks in all cases.
[00:20:40] It really depends on a task to task basis throughout the app. So I can't give you a kind of a, a single kind of simple rule of thumb for, in this case, do this. And in the other, do that. But yeah, we've it's a little bit easier now that the APIs between the anthropic models and opening are more similar than they used to be.
[00:20:59] So we don't have two totally separate code paths with different protocols, like wire protocols to, to speak, which makes things easier, but you're right. You do need to have different prompts if you want to, have similar performance across the providers.
[00:21:12] Adam Wiggins: I'll also note, just observing again as a relative newcomer here, I was surprised, impressed, not sure what the word is for it, at the blend of different backends that the team is using.
[00:21:24] And so there's many The product presents as kind of one single interface, but there's actually several dozen kind of main paths. There's like, for example, the search versus a data extraction of a certain type, versus chat with papers, versus And each one of these, , the team has worked very hard to pick the right Model for the job and craft the prompt there, but also is constantly testing new ones.
[00:21:48] So a new one comes out from either, from the big providers or in some cases, Our own models that are , running on, on essentially our own infrastructure. And sometimes that's more about cost or performance, but the point is kind of switching very fluidly between them and, and very quickly because this field is moving so fast and there's new ones to choose from all the time is like part of the day to day, I would say.
[00:22:11] So it isn't more of a like, there's a main one, it's been kind of the same for a year, there's a fallback, but it's got cobwebs on it. It's more like which model and which prompt is changing weekly. And so I think it's quite, quite reasonable to to, to, to have a fallback that you can expect might work.
[00:22:29] Is it too early to standardize Tech stacks?
[00:22:29] swyx: I'm curious because you guys have had experience working at both, , Elicit, which is a smaller operation and, and larger companies. A lot of companies are looking at this with a certain amount of trepidation as, as, , it's very chaotic. When you have, when you have , one engineering team that, that, knows everyone else's names and like, , they, they, they, they meet constantly in Slack and knows what's going on.
[00:22:50] It's easier to, to sync on technology choices. When you have a hundred teams, all shipping AI products and all making their own independent tech choices. It can be, it can be very hard to control. One solution I'm hearing from like the sales forces of the worlds and Walmarts of the world is that they are creating their own AI gateway, right?
[00:23:05] Internal AI gateway. This is the one model hub that controls all the things and has our standards. Is that a feasible thing? Is that something that you would want? Is that something you have and you're working towards? What are your thoughts on this stuff? Like, Centralization of control or like an AI platform internally.
[00:23:22] James Brady: Certainly for larger organizations and organizations that are doing things which maybe are running into HIPAA compliance or other, um, legislative tools like that. It could make a lot of sense. Yeah. I think for the TLDR for something like Elicit is we are small enough, as you indicated, and need to have full control over all the levers available and switch between different models and different prompts and whatnot, as Adam was just saying, that that kind of thing wouldn't work for us.
[00:23:52] But yeah, I've spoken with and, um, advised a couple of companies that are trying to sell into that kind of a space or at a larger stage, and it does seem to make a lot of sense for them. So, for example, if you're trying to sell If you're looking to sell to a large enterprise and they cannot have any data leaving the EU, then you need to be really careful about someone just accidentally putting in, , the sort of US East 1 GPT 4 endpoints or something like this.
[00:24:22] I'd be interested in understanding better what the specific problem is that they're looking to solve with that, whether it is to do with data security or centralization of billing, or if they have a kind of Suite of prompts or something like this that people can choose from so they don't need to reinvent the wheel again and again I wouldn't be able to say without understanding the problems and their proposed solutions , which kind of situations that be better or worse fit for but yeah for illicit where really the The secret sauce, if there is a secret sauce, is which models we're using, how we're using them, how we're combining them, how we're thinking about the user problem, how we're thinking about all these pieces coming together.
[00:25:02] You really need to have all of the affordances available to you to be able to experiment with things and iterate rapidly. And generally speaking, whenever you put these kind of layers of abstraction and control and generalization in there, that, that gets in the way. So, so for us, it would not work.
[00:25:19] Adam Wiggins: Do you feel like there's always a tendency to want to reach for standardization and abstractions pretty early in a new technology cycle?
[00:25:26] There's something comforting there, or you feel like you can see them, or whatever. I feel like there's some of that discussion around lang chain right now. But yeah, this is not only so early, but also moving so fast. , I think it's . I think it's tough to, to ask for that. That's, that's not the, that's not the space we're in, but the, yeah, the larger an organization, the more that's your, your default is to, to, to want to reach for that.
[00:25:48] It, it, it's a sort of comfort.
[00:25:51] swyx: Yeah, I find it interesting that you would say that , being a founder of Heroku where , you were one of the first platforms as a service that more or less standardized what, , that sort of early developer experience should have looked like.
[00:26:04] And I think basically people are feeling the differences between calling various model lab APIs and having an actual AI platform where. , all, all their development needs are thought of for them. , it's, it's very much, and, and I, I defined this in my AI engineer post as well.
[00:26:19] Like the model labs just see their job ending at serving models and that's about it. But actually the responsibility of the AI engineer has to fill in a lot of the gaps beyond that. So.
[00:26:31] Adam Wiggins: Yeah, that's true. I think, , a huge part of the exercise with Heroku, which It was largely inspired by Rails, which itself was one of the first frameworks to standardize the SQL database.
[00:26:42] And people had been building apps like that for many, many years. I had built many apps. I had made my own templates based on that. I think others had done it. And Rails came along at the right moment. We had been doing it long enough that you see the patterns and then you can say look let's let's extract those into a framework that's going to make it not only easier to build for the experts but for people who are relatively new the best practices are encoded into you.
[00:27:07] That framework, , Model View Controller, to take one example. But then, yeah, once you see that, and once you experience the power of a framework, and again, it's so comforting, and you can develop faster, and it's easier to onboard new people to it because you have these standards. And this consistency, then folks want that for something new that's evolving.
[00:27:29] Now here I'm thinking maybe if you fast forward a little to, for example, when React came on the on the scene, , a decade ago or whatever. And then, okay, we need to do state management. What's that? And then there's, , there's a new library every six months. Okay, this is the one, this is the gold standard.
[00:27:42] And then, , six months later, that's deprecated. Because of course, it's evolving, you need to figure it out, like the tacit knowledge and the experience of putting it in practice and seeing what those real What those real needs are are, are critical, and so it's, it is really about finding the right time to say yes, we can generalize, we can make standards and abstractions, whether it's for a company, whether it's for, , a library, an open source library, for a whole class of apps and it, it's very much a, much more of a A judgment call slash just a sense of taste or , experience to be able to say, Yeah, we're at the right point.
[00:28:16] We can standardize this. But it's at least my, my very, again, and I'm so new to that, this world compared to you both, but my, my sense is, yeah, still the wild west. That's what makes it so exciting and feels kind of too early for too much. too much in the way of standardized abstractions. Not that it's not interesting to try, but , you can't necessarily get there in the same way Rails did until you've got that decade of experience of whatever building different classes of apps in that, with that technology.
[00:28:45] James Brady: Yeah, it's, it's interesting to think about what is going to stay more static and what is expected to change over the coming five years, let's say. Which seems like when I think about it through an ML lens, it's an incredibly long time. And if you just said five years, it doesn't seem, doesn't seem that long.
[00:29:01] I think that, that kind of talks to part of the problem here is that things that are moving are moving incredibly quickly. I would expect, this is my, my hot take rather than some kind of official carefully thought out position, but my hot take would be something like the You can, you'll be able to get to good quality apps without doing really careful prompt engineering.
[00:29:21] I don't think that prompt engineering is going to be a kind of durable differential skill that people will, will hold. I do think that, The way that you set up the ML problem to kind of ask the right questions, if you see what I mean, rather than the specific phrasing of exactly how you're doing chain of thought or few shot or something in the prompt I think the way that you set it up is, is probably going to be remain to be trickier for longer.
[00:29:47] And I think some of the operational challenges that we've been talking about of wild variations in, in, in latency, And handling the, I mean, one way to think about these models is the first lesson that you learn when, when you're an engineer, software engineer, is that you need to sanitize user input, right?
[00:30:05] It was, I think it was the top OWASP security threat for a while. Like you, you have to sanitize and validate user input. And we got used to that. And it kind of feels like this is the, The shell around the app and then everything else inside you're kind of in control of and you can grasp and you can debug, etc.
[00:30:22] And what we've effectively done is, through some kind of weird rearguard action, we've now got these slightly chaotic things. I think of them more as complex adaptive systems, which , related but a bit different. Definitely have some of the same dynamics. We've, we've injected these into the foundations of the, of the app and you kind of now need to think with this defined defensive mindset downwards as well as upwards if you, if you see what I mean.
[00:30:46] So I think it would gonna, it's, I think it will take a while for us to truly wrap our heads around that. And also these kinds of problems where you have to handle things being unreliable and slow sometimes and whatever else, even if it doesn't happen very often, there isn't some kind of industry wide accepted way of handling that at massive scale.
[00:31:10] There are definitely patterns and anti patterns and tools and whatnot, but it's not like this is a solved problem. So I would expect that it's not going to go down easily as a, as a solvable problem at the ML scale either.
[00:31:23] swyx: Yeah, excellent. I would describe in, in the terminology of the stuff that I've written in the past, I describe this inversion of architecture as sort of LLM at the core versus LLM or code at the core.
[00:31:34] We're very used to code at the core. Actually, we can scale that very well. When we build LLM core apps, we have to realize that the, the central part of our app that's orchestrating things is actually prompt, prone to, , prompt injections and non determinism and all that, all that good stuff.
[00:31:48] I, I did want to move the conversation a little bit from the sort of defensive side of things to the more offensive or, , the fun side of things, capabilities side of things, because that is the other part. of the job description that we kind of skimmed over. So I'll, I'll repeat what you said earlier.
[00:32:02] Capabilities: Offensive AI Engineering
[00:32:02] swyx: It's, you want people to have a genuine curiosity and enthusiasm for the capabilities of language models. We just, we're recording this the day after Anthropic just dropped Cloud 3. 5. And I was wondering, , maybe this is a good, good exercise is how do people have Curiosity and enthusiasm for capabilities language models when for example the research paper for cloud 3.
[00:32:22] 5 is four pages
[00:32:23] James Brady: Maybe that's not a bad thing actually in this particular case So yeah If you really want to know exactly how the sausage was made That hasn't been possible for a few years now in fact for for these new models but from our perspective as when we're building illicit What we primarily care about is what can these models do?
[00:32:41] How do they perform on the tasks that we already have set up and the evaluations we have in mind? And then on a slightly more expansive note, what kinds of new capabilities do they seem to have? Can we elicit, no pun intended, from the models? For example, well, there's, there's very obvious ones like multimodality , there wasn't that and then there was that, or it could be something a bit more subtle, like it seems to be getting better at reasoning, or it seems to be getting better at metacognition, or Or it seems to be getting better at marking its own work and giving calibrated confidence estimates, things like this.
[00:33:19] So yeah, there's, there's plenty to be excited about there. It's just that yeah, there's rightly or wrongly been this, this, this shift over the last few years to not give all the details. So no, but from application development perspective we, every time there's a new model release, there's a flow of activity in our Slack, and we try to figure out what's going on.
[00:33:38] What it can do, what it can't do, run our evaluation frameworks, and yeah, it's always an exciting, happy day.
[00:33:44] Adam Wiggins: Yeah, from my perspective, what I'm seeing from the folks on the team is, first of all, just awareness of the new stuff that's coming out, so that's, , an enthusiasm for the space and following along, and then being able to very quickly, partially that's having Slack to do this, but be able to quickly map that to, okay, What does this do for our specific case?
[00:34:07] And that, the simple version of that is, let's run the evaluation framework, which Lissa has quite a comprehensive one. I'm actually working on an article on that right now, which I'm very excited about, because it's a very interesting world of things. But basically, you can just try, not just, but try the new model in the evaluations framework.
[00:34:27] Run it. It has a whole slew of benchmarks, which includes not just Accuracy and confidence, but also things like performance, cost, and so on. And all of these things may trade off against each other. Maybe it's actually, it's very slightly worse, but it's way faster and way cheaper, so actually this might be a net win, for example.
[00:34:46] Or, it's way more accurate. But that comes at its slower and higher cost, and so now you need to think about those trade offs. And so to me, coming back to the qualities of an AI engineer, especially when you're trying to hire for them, It's this, it's, it is very much an application developer in the sense of a product mindset of What are our users or our customers trying to do?
[00:35:08] What problem do they need solved? Or what what does our product solve for them? And how does the capabilities of a particular model potentially solve that better for them than what exists today? And by the way, what exists today is becoming an increasingly gigantic cornucopia of things, right? And so, You say, okay, this new model has these capabilities, therefore, , the simple version of that is plug it into our existing evaluations and just look at that and see if it, it seems like it's better for a straight out swap out, but when you talk about, for example, you have multimodal capabilities, and then you say, okay, wait a minute, actually, maybe there's a new feature or a whole new There's a whole bunch of ways we could be using it, not just a simple model swap out, but actually a different thing we could do that we couldn't do before that would have been too slow, or too inaccurate, or something like that, that now we do have the capability to do.
[00:35:58] I think of that as being a great thing. I don't even know if I want to call it a skill, maybe it's even like an attitude or a perspective, which is a desire to both be excited about the new technology, , the new models and things as they come along, but also holding in the mind, what does our product do?
[00:36:16] Who is our user? And how can we connect the capabilities of this technology to how we're helping people in whatever it is our product does?
[00:36:25] James Brady: Yeah, I'm just looking at one of our internal Slack channels where we talk about things like new new model releases and that kind of thing And it is notable looking through these the kind of things that people are excited about and not It's, I don't know the context, the context window is much larger, or it's, look at how many parameters it has, or something like this.
[00:36:44] It's always framed in terms of maybe this could be applied to that kind of part of Elicit, or maybe this would open up this new possibility for Elicit. And, as Adam was saying, yeah, I don't think it's really a I don't think it's a novel or separate skill, it's the kind of attitude I would like to have all engineers to have at a company our stage, actually.
[00:37:05] And maybe more generally, even, which is not just kind of getting nerd sniped by some kind of technology number, fancy metric or something, but how is this actually going to be applicable to the thing Which matters in the end. How is this going to help users? How is this going to help move things forward strategically?
[00:37:23] That kind of, that kind of thing.
[00:37:24] AI Engineering Required Knowledge
[00:37:24] swyx: Yeah, applying what , I think, is, is, is the key here. Getting hands on as well. I would, I would recommend a few resources for people listening along. The first is Elicit's ML reading list, which I, I found so delightful after talking with Andreas about it.
[00:37:38] It looks like that's part of your onboarding. We've actually set up an asynchronous paper club instead of my discord for people following on that reading list. I love that you separate things out into tier one and two and three, and that gives people a factored cognition way of Looking into the, the, the corpus, right?
[00:37:55] Like yes, the, the corpus of things to know is growing and the water is slowly rising as far as what a bar for a competent AI engineer is. But I think, , having some structured thought as to what are the big ones that everyone must know I think is, is, is key. It's something I, I haven't really defined for people and I'm, I'm glad that this is actually has something out there that people can refer to.
[00:38:15] Yeah, I wouldn't necessarily like make it required for like the job. Interview maybe, but , it'd be interesting to see like, what would be a red flag. If some AI engineer would not know, I don't know what, , I don't know where we would stoop to, to call something required knowledge, , or you're not part of the cool kids club.
[00:38:33] But there increasingly is something like that, right? Like, not knowing what context is, is a black mark, in my opinion, right?
[00:38:40] I think it, I think it does connect back to what we were saying before of this genuine Curiosity about and that. Well, maybe it's, maybe it's actually that combined with something else, which is really important, which is a self starting bias towards action, kind of a mindset, which again, everybody needs.
[00:38:56] Exactly. Yeah. Everyone needs that. So if you put those two together, or if I'm truly curious about this and I'm going to kind of figure out how to make things happen, then you end up with people. Reading, reading lists, reading papers, doing side projects, this kind of, this kind of thing. So it isn't something that we explicitly included.
[00:39:14] We don't have a, we don't have an ML focused interview for the AI engineer role at all, actually. It doesn't really seem helpful. The skills which we are checking for, as I mentioned before, this kind of fault first mindset. And conventional software engineering kind of thing. It's, it's 0. 1 and 0.
[00:39:32] 3 on the list that, that we talked about. In terms of checking for ML curiosity and there are, how familiar they are with these concepts. That's more through talking interviews and culture fit types of things. We want for them to have a take on what Elisa is doing. doing, certainly as they progress through the interview process.
[00:39:50] They don't need to be completely up to date on everything we've ever done on day zero. Although, , that's always nice when it happens. But for them to really engage with it, ask interesting questions, and be kind of bought into our view on how we want ML to proceed. I think that is really important, and that would reveal that they have this kind of this interest, this ML curiosity.
[00:40:13] ML First Mindset
[00:40:13] swyx: There's a second aspect to that. I don't know if now's the right time to talk about it, which is, I do think that an ML first approach to building software is something of a different mindset. I could, I could describe that a bit now if that, if that seems good, but yeah, I'm a team. Okay. So yeah, I think when I joined Elicit, this was the biggest adjustment that I had to make personally.
[00:40:37] So as I said before, I'd been, Effectively building conventional software stuff for 15 years or so, something like this, well, for longer actually, but professionally for like 15 years. And had a lot of pattern matching built into my brain and kind of muscle memory for if you see this kind of problem, then you do that kind of a thing.
[00:40:56] And I had to unlearn quite a lot of that when joining Elicit because we truly are ML first and try to use ML to the fullest. And some of the things that that means is, This relinquishing of control almost, at some point you are calling into this fairly opaque black box thing and hoping it does the right thing and dealing with the stuff that it sends back to you.
[00:41:17] And that's very different if you're interacting with, again, APIs and databases, that kind of a, that kind of a thing. You can't just keep on debugging. At some point you hit this, this obscure wall. And I think the second, the second part to this is the pattern I was used to is that. The external parts of the app are where most of the messiness is, not necessarily in terms of code, but in terms of degrees of freedom, almost.
[00:41:44] If the user can and will do anything at any point, and they'll put all sorts of wonky stuff inside of text inputs, and they'll click buttons you didn't expect them to click, and all this kind of thing. But then by the time you're down into your SQL queries, for example, as long as you've done your input validation, things are pretty pretty well defined.
[00:42:01] And that, as we said before, is not really the case. When you're working with language models, there is this kind of intrinsic uncertainty when you get down to the, to the kernel, down to the core. Even, even beyond that, there's all that stuff is somewhat defensive and these are things to be wary of to some degree.
[00:42:18] Though the flip side of that, the really kind of positive part of taking an ML first mindset when you're building applications is that you, If you, once you get comfortable taking your hands off the wheel at a certain point and relinquishing control, letting go then really kind of unexpected powerful things can happen if you lean on the, if you lean on the capabilities of the model without trying to overly constrain and slice and dice problems with to the point where you're not really wringing out the most capability from the model that you, that you might.
[00:42:47] So, I was trying to think of examples of this earlier, and one that came to mind was we were working really early when just after I joined Elicit, we were working on something where we wanted to generate text and include citations embedded within it. So it'd have a claim, and then a, , square brackets, one, in superscript, something, something like this.
[00:43:07] And. Every fiber in my, in my, in my being was screaming that we should have some way of kind of forcing this to happen or Structured output such that we could guarantee that this citation was always going to be present later on that the kind of the indication of a footnote would actually match up with the footnote itself and Kind of went into this symbolic.
[00:43:28] I need full control kind of kind of mindset and it was notable that Andreas Who's our CEO, again, has been on the podcast, was was the opposite. He was just kind of, give it a couple of examples and it'll probably be fine. And then we can kind of figure out with a regular expression at the end. And it really did not sit well with me, to be honest.
[00:43:46] I was like, but it could say anything. I could say, it could literally say anything. And I don't know about just using a regex to sort of handle this. This is a potent feature of the app. But , this is that was my first kind of, , The starkest introduction to this ML first mindset, I suppose, which Andreas has been cultivating for much longer than me, much longer than most, of yeah, there might be some surprises of stuff you get back from the model, but you can also It's about finding the sweet spot, I suppose, where you don't want to give a completely open ended prompt to the model and expect it to do exactly the right thing.
[00:44:25] You can ask it too much and it gets confused and starts repeating itself or goes around in loops or just goes off in a random direction or something like this. But you can also over constrain the model. And not really make the most of the, of the capabilities. And I think that is a mindset adjustment that most people who are coming into AI engineering afresh would need to make of yeah, giving up control and expecting that there's going to be a little bit of kind of extra pain and defensive stuff on the tail end, but the benefits that you get as a, as a result are really striking.
[00:44:58] The ML first mindset, I think, is something that I struggle with as well, because the errors, when they do happen, are bad. , they will hallucinate, and your systems will not catch it sometimes if you don't have large enough of a sample set.
[00:45:13] AI Engineers and Creativity
[00:45:13] swyx: I'll leave it open to you, Adam. What else do you think about when you think about curiosity and exploring capabilities?
[00:45:22] Do people are there reliable ways to get people to push themselves? for joining us on Capabilities, because I think a lot of times we have this implicit overconfidence, maybe, of we think we know what it is, what a thing is, when actually we don't, and we need to keep a more open mind, and I think you do a particularly good job of Always having an open mind, and I want to get that out of more engineers that I talk to, but I, I, I, I struggle sometimes.
[00:45:45] Adam Wiggins: I suppose being an engineer is, at its heart, this sort of contradiction of, on one hand, yeah, systematic, almost very literal, yeah, wanting to control exactly what James described understand everything, model it in your mind, Precision, yeah, systematizing but fundamentally it is a, It is a creative endeavor, at least.
[00:46:09] I got into creating with computers because I saw them as a canvas for creativity, for making great things, and for making a medium for making things that are, , so multidimensional that it goes beyond any medium humanity's ever had for creating things. So I think, or hope, that a lot of engineers are drawn to it.
[00:46:31] Partially because you need both of those. You need that systematic controlling side and then the creative open ended, almost like artistic side. And I, and I think it is, I think it is exactly the same here. In fact, if anything, I feel like there's a theme running through everything James has said here, which is in many ways, what we're looking for in an AI engineer is not.
[00:46:52] Really all that fundamentally different from other, , call it conventional engineering or other types of engineering, but working with this strange new medium that has these different qualities. But in the end there, there, a lot of the things are an amalgamation of past engineering skills.
[00:47:07] And I think that, that mix of, yeah, curiosity, artistic, open ended, what can we do with this, with a desire to systematize, control, make reliable, make repeatable is, is the mix you need and trying to trying to find that balance, I think is, is probably where it's at. But fundamentally, I think people who are, are getting into this field to work on this is because it is an exciting, , they're excited by the promise and the potential of the technology.
[00:47:34] So to, to not have that kind of creative open ended curiosity side would be well would, would be surprising. Like what, why, why do it otherwise? So I think that, that blend is always what you're looking for. What you're looking for broadly, but here, now we're just scoping it to this new world of language models.
[00:47:51] Inside of Me There Are Two Wolves
[00:47:51] James Brady: I think the default first mindset and the ML curiosity attitude Could be somewhat intention, right? Because for example, the, the stereotypical, stereotypical version of someone that is great at building fault tolerant systems has probably been doing it for a decade or two. They've been principal engineer at some massive scale technology company.
[00:48:14] And that kind of a person might be less I think it's really important that people are able to turn on a dime and be under linkage control and be creative and take on this different mindset. Whereas someone who's very early in their career is much more able to do that kind of exploration and follow their curiosity kind of a thing.
[00:48:33] And they might be a little bit less creative. Practiced in how to, , serve terabytes of traffic every day, obviously. So
[00:48:43] Adam Wiggins: Yeah, the stereotype that comes to mind for me with those two you just described is the, the principal engineer, , fault tolerance, , handle unpredictable, is kind of grumpy and always skeptical of anything new and, , it's probably not going to work and that sort of thing.
[00:48:58] Whereas that, yeah, fresh face early in their career maybe more application focused and it's always thinking about the happy path and the optimistic and oh don't worry about the edge case that probably won't happen i i don't write code with bugs i don't know whatever like this but but really need both together i think in or both of those attitudes or personalities if that's even the right way to put it together in one I think
[00:49:21] James Brady: people can come from either end of the spectrum to be, to be clear.
[00:49:23] , not all grizzled principal engineers are the way that I'm described. Thankfully some, some probably are, and not all, , junior engineers are allergic to writing, , careful software or, or unable and unexcited to pick that up. So yeah, , it could be someone that's in the middle of the career and naturally has a bit of both.
[00:49:41] Could be someone at either end and just. , once they kind of round out their skill set and lean into the thing that they're a bit weaker on any of the, any of the above would work well for us. , a fair
[00:49:49] swyx: amount of like, actually we, I think we've accidentally defined AI engineering along the way as well, because you kind of have to do that in order to to hire and interview for people.
[00:49:58] Sourcing AI Engineers
[00:49:58] swyx: The last piece I wanted to And the last thing I would offer to our audience is sourcing a very underappreciated part because people just tend to rely on recruiters and, , assume that candidates fall from the sky. But I think the two of you have had plenty of experience with like really good sourcing and I just want to give leave some time open for what is AI engineer sourcing look like?
[00:50:19] Is it being very loud on Twitter?
[00:50:21] James Brady: Well, I mean, that definitely helps. I am really quiet on Twitter, unfortunately, but a lot of my teammates are much more effective on that front which is deeply appreciated. I think in terms of in terms of, maybe I'll focus a little bit more on active outbound, if you will, rather than the kind of yes, Marketing, branding type of work that that Adam's been really effective with us on.
[00:50:44] So the kinds of things that I'm looking for are certainly side projects. It's, it's really easy still. We're early on in this, early enough on in this process that people can still do interesting work pretty much at the cutting edge, not in terms of training whole models, of course, but AI engineering. You can.
[00:51:02] Very much build interesting apps that have interesting ideas and work well just using a, , basic Open API, Open AI API key. So, people sharing that kind of stuff on Twitter is always really interesting, or in, , Discord or Slacks, things like this. In terms of the, the kind of caricature of the grizzled principal engineer kind of a person, It's, it's notable.
[00:51:27] I mean, I've spoken with a bunch of people coming from that kind of perspective. They're fairly easy to find. They tend to be on LinkedIn. They tend to be really obvious on LinkedIn because they're maybe a bit more senior. They've got a ton of connections. They're probably expected to kind of post thought leadership kinds of things on LinkedIn.
[00:51:46] Everyone's favorite. And , some of those, some of those people are interested in picking up new skills and jumping into ML and, and large language models. And sometimes it's obvious from a profile. Sometimes you just need to reach out and introduce yourself and say, hey, this is what we're doing.
[00:52:00] We think we could use your skills and a bunch of them will, will, will bite your hand off actually, because it is such an interesting area. So that's how, that's how we've found success at sourcing on the kind of more experienced end of the spectrum. I think on the, on the less experienced end of the spectrum, having lots of hooks in the ocean seems to be a good strategy if I think about what's worked for us.
[00:52:25] So, it's, it tends to be much harder to find those people because they have less of an online presence in terms of like active outbound. So, things like blog posts, hot takes on Twitter, things like challenges that we might have Those are the kind of vectors through which you can find these keen, full of energy, less experienced people and bring them towards you.
[00:52:50] Yeah. Adam, do you have anything? You're pretty good on Twitter compared to me, at least. What's your, what's your take on yeah, the kind of more like throwing stuff out there and have people come towards you for this kind of a role.
[00:53:03] Adam Wiggins: Yeah, I do typically think of sourcing as being the one two punch of one, raise the beacon, let the world know that you are working on interesting problems, and you're expanding your team, and maybe there's a place for someone like them on that team, and that can come in a variety of forms, whether it's, , going to a job fair and having a booth, obviously it's job descriptions posted to your site, it's obviously things like, In some cases, yeah, blog posts about stuff you're working on, releasing open source, Anything that goes out into the world and people find out about what you're doing, Not at the very surface level of here's what the product is, And, I don't know, we have a couple job descriptions on the site, But a layer deeper of like, here's the kind, here's what it actually looks like.
[00:53:50] So, I think that's, that's one piece of it. And then the other piece of it is, as you said, is the outbound. I think it's not enough to especially when you're small. I think it's, it changes a lot when you're a bigger company with a strong brand or if the product you're working on is more in a technical space.
[00:54:05] And so, therefore, maybe your customer, there's actually among your customers, there's the sorts of people that you might might like to work for you. I don't know if you're a GitHub, then probably all of your users and customers, , the people you want to hire are among your user base, which is a nice combination, but for most products, that's not going to be the case.
[00:54:20] So then now the outbound is a big piece of it. And part of that is, as you said, getting out into the world, whether it's going to meetups, whether it's going to conferences, whether it's being on Twitter and just genuinely being out there and part of the field and having conversations with people and seeing people who are doing interesting things and making connections with them.
[00:54:37] Hopefully not in a. Transactional way, or you're always just, , sniffing around for who's available to hire. But you just generally, if you like this work and you want to be part of the field and you want to follow along with people who are doing interesting things, and then by the way, you will discover when they post, oh, I'm wrapping up my , my job here and thinking about the next thing and, , that's a good time to, to ping them and be like, oh, cool, , actually we, we have maybe some things that you, you might be interested in here on the team and that, that kind of, that kind of outbound, but I think it also pairs well, it's, it's not just that you need both, it's that they, they reinforce each other, so if someone has seen, for example, the open source project you've released, And they're like, Oh, that's cool.
[00:55:17] And they briefly looked at your company and then you follow each other on Twitter or whatever, and then they post, Hey, I'm thinking about my next thing and then you write them and they already have some context of like, Oh, I liked that project you did and I liked. , I kind of have some ambient awareness of what you're doing.
[00:55:31] Yeah. Let's have a conversation. This isn't totally cold. So I think those, those two together are important. The other footnote I would put again on the specifics, that's, I think, general sourcing for any kind of role, but for AI engineering specifically, you're not looking for professional experience at this stage.
[00:55:47] You're not always looking for professional experience with language models. It's just too early. So it's totally fine that someone has the professional experience with the Conventional engineering skills but yeah, the interest, the, the, the curiosity, that sort of thing expressed through side projects, hackathons, blog posts, whatever it is.
[00:56:06] swyx: Yeah, absolutely. I often tell people, a lot of people are asking me for San Francisco AI engineers because they want, there's this sort of wave or reaction against the remote mindset, which I know that you guys probably differ in opinion on, but a lot of people are trying to, , go back to office.
[00:56:20] And so my, my only option for people is just find them at the hackathons. Like they're, , the, the most self driven motivated people, Who can work on things quickly and ship fast are already in hackathons. And just go through the list of winners. And then self interestedly, , if, for example, someone's hosting an AI conference from June 25th to June 27th on San Francisco, you might want to show up there and see, for example, who might be available.
[00:56:45] So, and that is true, , not, , it's not something I want to advertise to the employers, the people who come, but a lot of people change jobs at conferences. This is a known thing so.
[00:56:54] Adam Wiggins: Yeah, of course. But I think it's the same as engaging on Twitter, engaging in open source, attending conferences, 100%, this is a great way both to find new opportunities if you're a job seeker, Find people for your team if you're a hiring manager, but if you come at it too networky and transactional, that's just gross for everyone.
[00:57:12] Hopefully, we're all people that got into this work largely because we love it, and it's nice to connect with other people that have the same, , skills and struggle with the same problems in their work. And you make genuine connections and you learn from each other, and by the way, from that can come as a, well, not quite a side effect, but an, an effect on the list is pairing together people who are looking for opportunities with people who have interesting problems to work on.
[00:57:38] swyx: Yeah, most important part of employer branding, , have, have a great mission have great teammates. , if you can show that off in, in whatever way you can you'll, you'll be, you'll be starting off on the right foot. On
[00:57:46] James Brady: that note, we have. Been really successful with hiring a number of people from From targeted job boards, maybe, maybe is the right way of saying it.
[00:57:55] So not some kind of generic Indeed. com or something, not to trash them, but something that's a bit more tied to your mission, tied to what you're doing, something which is really relevant, something which is going to cut down the search space for what you're looking at, what the candidate's looking at. So we're definitely, , affiliated with the AI safety, effective altruists kind of movement.
[00:58:19] I've gone to a few EA Globals and have hired people effectively through the 80, 000 hours list as, as well. So, , that's not the only reason why people would want to join Elicit, but as an example of, if you're interested in, in AI safety or, , whatever your take is on this stuff, then there's probably something, there's a sub stack, there's a podcast, there's a, there's a mailing list, there's a job board, there's something which lets you zoom in on the kind of particular take that, That you agree with.
[00:58:45] Parting Thoughts
[00:58:45] swyx: Cool. I will leave it there. Any, any last comments about just hiring in general advice to other technology leaders in AI? , one, one thing I'm trying to do for my conference as well is to create a forum for technology leaders to, to share thoughts, right?
[00:58:59] James Brady: Yeah, a couple of thoughts here. So firstly, when I think back to how I was when I was in my early 20s, when I was at, when I was at college or university, the maturity and capabilities and just kind of general put togetherness of people at that age now is strikingly different to, to, to where I was then.
[00:59:24] And I, I think this is. Not because I was especially lexadesical or something when I was, when I was young. I think it's I hear the same thing echoed in other people about my, about my age. So the takeaway from that is finding a way of presenting yourself to and identifying and bringing in really high capability young people into your organization.
[00:59:46] I mean, it's always been true, but I think it's even more true now. They're kind of more professional, more capable, more committed more driven. have more of a sense of what they're all about than certainly I did 20 years ago. So that's, that's the first thing. I think the second thing is in terms of the interview process, this is somewhat a general take, but it definitely applies to AI engineer roles.
[01:00:07] And I think more so to AI engineer roles. I really have a strong dislike and distaste for interview questions, which are arbitrary and kind of strip away all the context from what it really is to do the work. We try to make the interview process that's illicit. A simulation of working together. The only people that we go into an interview process with.
[01:00:29] are pretty obviously extraordinary really, really capable. They must have done something for them to have moved into the proper interview process. So it is a check on technical capability and in the ways that we've described, but it's at least as much them sizing us up. Like, is this something which is worth my time?
[01:00:49] Is it something that I'm going to really be able to dedicate myself to? So being able to show them, this is really what it's like working at Elicit. This is the people you're going to work with. These are the kinds of tasks that you're going to be doing. This is the sort of environment that we work in.
[01:01:00] These are the tools we use. All that kind of stuff is really, really important from a candidate experience, but it also gives us a ton more signal as well about, , what is it actually like to work with this person? Not just can they do really well on some kind of leak code style, style problem.
[01:01:15] I think the reason that it bears a particularly on the AI engineer role is because it is something of an emerging category, if you will. So there isn't a very kind of. Well established do these that nobody's written the book yet Maybe this is the beginning of us writing the book and how to get hired as an AI engineer but that book doesn't exist at the moment and Yeah, It's an empirical job as, as much as any other kind of software engineering.
[01:01:41] It's, it's less about having kind of book learning and more about being able to apply that in a real world situation. So let's make the interview as close to a real world situation as possible.
[01:01:49] swyx: I do, I do co sign a lot of that. Yeah, I think this is a really great overview of just the, the, the sort of state of, Hiring AI engineers.
[01:01:56] And I honestly, that's just what, what AI engineering even is, which it really is like, when I was thinking about this as an industrial movement it was very much around, around the labor market, actually and the economic forces that give rise to, to a role like this both on the incentives of the model labs, as well as the demand and supply of engineers and the interest level of companies And the engineers working on these problems.
[01:02:20] So I definitely see you guys as pioneers. Thank you so much for putting together this piece, which is something I've been seeking for a long time. You even shared your job description, your reading list, and your interview loop. So, , if anyone's looking to hire AI engineers, I expect this to be the definitive piece and definitive podcast covering it.
[01:02:39] So thank you so much for taking the time to do this.
[01:02:43] Adam Wiggins: It was fun. Thanks for having us. Thanks a
[01:02:44] James Brady: lot. Really enjoyed the conversation. And I appreciate you naming something which we all had in our heads, but but couldn't put a label on.
[01:02:51] swyx: It was going to be named anyway. So I actually, I never, I never actually personally say that I coined a term because I'm sure someone else used the term before me.
[01:02:59] All I did was write a popular piece on it. All right. So I I'm happy to help because I know that it contributed to job creation at a bunch of companies I respect and, and, and help people find each other, which is my whole goal here. So, yeah, thanks for helping me do this.



How To Hire AI Engineers — with James Brady & Adam Wiggins of Elicit